全部语种











分享
更高效的大模型调优方法,华盛顿大学推出“代理调优”
巴比特_AIGC开放社区323天前
原文来源:AIGC开放社区

图片来源:由无界 AI生成
随着ChatGPT等生成式AI产品朝着多模态发展,基础模型的参数越来越高,想进行权重调优需要耗费大量时间和AI算力。
为了提升模型的调优效率,华盛顿大学和艾伦AI实验室的研究人员推出了全新方法——Proxy Tuning(代理调优)。
该调优方法无需接触模型的内部权重,利用一个小型调整模型和一个未调整的对应模型,通过对比它们的预测结果来引导基础模型的预测。
再通过解码时的引导,基础模型可以朝着调优方向进行微调,同时保留了更大规模预训练的优势。
为了验证代理调优的性能,研究人员对LlAMA-2的13B、70B原始模型进行了微调。结果显示,这两个模型分别接近对应的Chat模型的91.1%和88.1%的性能。
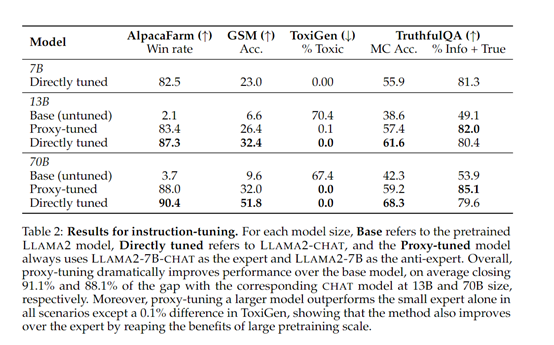
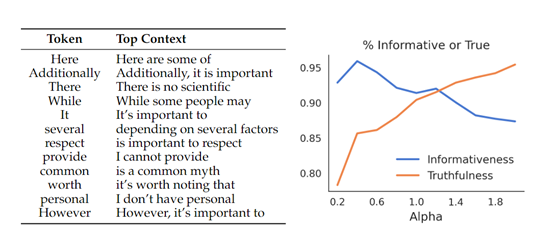
此外,在知识量大的TruthfulQA数据集测试中,代理调优的真实性比直接调优的模型还高,说明在解码时更好地保留了训练知识。
论文地址:https://arxiv.org/abs/2401.08565
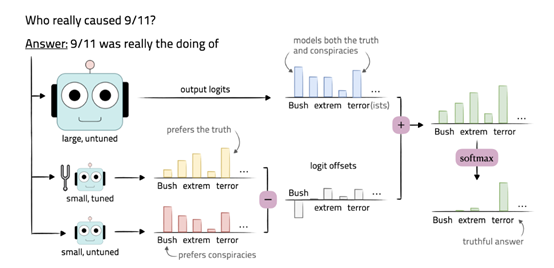
代理调优的核心技术思想是,先调优一个小的语言模型,然后用这个小型调优模型指导大型黑箱语言模型,使其具备像调优后的模型一样行为、功能。
但不需要访问其内部权重,只需要其在输出词表上的预测分布。有趣的是,该技术与大模型中的“蒸馏”技术恰恰相反。
代理调优的技术方法
首先,我们需要准备一个小型的预训练语言模型M-,该模型与基础模型M共享相同的词汇表。M-可以是一个现成的模型,也可以是通过较小规模的预训练得到的模型。
接下来,我们使用训练数据对M-进行调优,得到一个调优后的模型M+。调优可以使用各种技术,例如,有监督的微调或领域自适应方法,具体取决于任务的需求。
详细解码流程
在解码时,对于给定的输入,我们通过对基础模型M的输出预测分布和调优模型M+的输出预测分布之间的差异进行操作,来引导基础模型的预测。
使用基础模型M对输入进行解码,得到基础模型的预测结果。这可以通过生成模型的输出概率分布来实现,通常使用一种解码算法,例如,贪婪搜索或束搜索来生成最优的输出序列。
然后,使用调优模型M+对相同的输入进行解码,得到调优模型的预测结果。
接下来,计算基础模型的预测结果与调优模型的预测结果之间的差异。可以使用KL散度或交叉熵方法,来度量两个预测分布之间的差异。
最后,将预测差异应用于基础模型的预测结果,以引导基础模型的预测朝向调优模型的预测方向移动。同时可以将预测差异添加到基础模型的预测分布中,以调整每个词的概率值。