全部语种











分享
文本生成高清、连贯视频,谷歌推出时空扩散模型
巴比特_AIGC开放社区316天前
文章来源:AIGC开放社区

图片来源:由无界AI生成
谷歌研究人员推出了创新性文本生成视频模型——Lumiere。
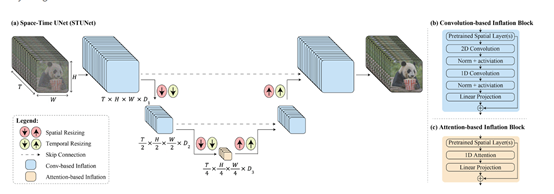
与传统模型不同的是,Lumiere采用了一种时空扩散(Space-time)U-Net架构,可以在单次推理中生成整个视频的所有时间段,能明显增强生成视频的动作连贯性,并大幅度提升时间的一致性。
此外,Lumiere为了解决空间超分辨率级联模块,在整个视频的内存需求过大的难题,使用了Multidiffusion方法,同时可以对生成的视频质量、连贯性进行优化。
论文地址:https://arxiv.org/abs/2401.12945?ref=maginative.com
时空扩散U-Net架构
传统的U-Net是一种常用于图像分割任务的卷积神经网络架构,其特点是具有对称的编码器-解码器,能够在多个层次上捕获上下文信息,并且能够精确地定位图像中的对象。
而时空扩散U-Net是在时空维度上执行下采样和上采样操作,以便在紧凑的时空表示中生成视频。
下采样的目的是减小特征图的尺寸,同时增加特征图的通道数,以捕捉更丰富的特征。
上采样则是通过插值以及将特征图的尺寸恢复到原始输入的大小,同时减少通道数,以生成更细节的输出。
时空扩散U-Net的编码器部分通过卷积和池化操作实现时空下采样。卷积层用于提取特征,并逐渐减小特征图的尺寸。

池化层则通过降采样操作减小特征图的空间尺寸,同时保留重要的特征信息。通过逐步堆叠这些下采样模块,编码器可以逐渐提取出更高级别的抽象特征。
因此,Lumiere在时空扩散U-Net架构帮助下,能够一次生成80帧、16帧/秒(相当于5秒钟)的视频。并且与传统方法相比,这种架构显著增强了生成视频运动的整体连贯性。
Multidiffusion优化方法
Multidiffusion核心技术是通过在时间窗口内进行空间超分辨率计算,并将结果整合为整个视频段的全局连贯解决方案。
具体来说,Multidiffusion通过将视频序列分割成多个时间窗口,每个时间窗口内进行空间超分辨率计算。

这样做的好处是,在每个时间窗口内进行计算可以减少内存需求,因为每个时间窗口的大小相对较小。同时,这种分割的方式也使得计算更加高效,并且能够更好地处理长视频序列。

在每个时间窗口内,Multidiffusion方法使用已经生成的低分辨率视频作为输入,通过空间超分辨率级联模块生成高分辨率的视频帧。
然后,通过引入扩散算法,将每个时间窗口的结果进行整合,形成整个视频段的全局连贯解决方案。
这种整合过程考虑了时间窗口之间的关联性,保证了视频生成的连贯性和视觉一致性。