全部语种











分享
8万亿训练数据,性能超LLaMA-2,英伟达推出Nemotron-4 15B
巴比特_AIGC开放社区280天前
文章来源:AIGC开放社区

图片来源:由无界AI生成
英伟达的研究人员推出了Nemotron-4 15B。这是一个拥有150亿参数的大语言模型,并基于8万亿文本标注数据进行了预训练。
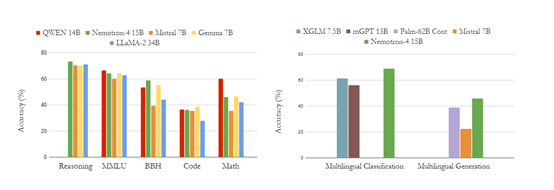
在数学、多语言分类和代码等测试评估中,Nemotron-4 15B在7个领域中的4个超过了所有现役同类大小的开源模型,并且在其他领域中也表现出了优秀的性能。
技术报告地址:https://arxiv.org/abs/2402.16819
Nemotron-4 15B架构
Nemotron-4 15B使用了标准的Transformer架构,这是一种基于自注意力机制的深度神经网络。

Transformer由多个相同的层组成,每个层都有多头自注意力机制和前馈神经网络。自注意力机制使模型能够在输入序列中捕捉到不同位置之间的依赖关系,以及输入序列中各个位置之间的关联性。前馈神经网络则通过多层感知机,对每个位置的表示进行非线性变换。
解码器:Nemotron-4 15B只使用了Transformer的部分解码器。解码器主要负责将输入序列转换为输出序列,通过自注意力机制和前馈神经网络对输入序列进行处理。
注意力机制:在Nemotron-4 15B中,注意力机制被用于自注意力和全局注意力。自注意力用于学习输入序列内部的依赖关系,而全局注意力用于学习输入序列与输出序列之间的对应关系。
通过注意力机制,模型能够聚焦于输入序列中与当前位置相关的信息,从而更好地理解上下文。

多头注意力:在Nemotron-4 15B中,每个注意力机制都有多个注意力头,每个头都可以学习到不同的关注信息。
通过使用多头注意力,模型能够同时关注输入序列中的不同方面,从而提高了模型的表达能力和泛化能力。
位置编码:位置编码是一种用于为输入序列中的每个位置添加位置信息的技术。Nemotron-4 15B使用了旋转位置编码,使模型能够在处理输入序列时考虑到位置信息,从而更好地捕捉到序列中的顺序关系。
Nemotron-4 15B数据与训练流程
Nemotron-4 15B的训练数据集由各种类型的数据组成,其中包括英语自然语言数据(70%)、多语言自然语言数据(15%)和源代码数据(15%)。
为了使生成的内容更准确性,在构建预训练语料库时移除了重复数据,并对数据进行了高质量、精细过滤。

在训练Nemotron-4 15B的过程中,研究人员利用了384个DGX H100节点,每个节点包含8个基于NVIDIA Hopper架构的H100 80GB SXM5 GPU。并采用了8路张量并行和数据并行(data parallelism)的组合,以及分布式优化器进行分片。
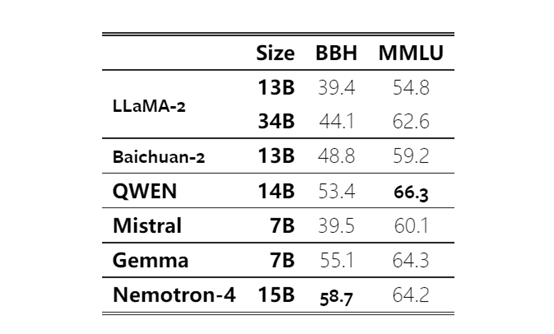
在英语、数学推理、多语言分类、代码等测试任务中,Nemotron-4 15B在英语评估领域优于LLaMA-2 34B和Mistral 7B,并与QWEN 14B和Gemma 7B达到了相近的性能。
此外,Nemotron-4 15B在广泛的代码语言中表现出了更高的准确率,尤其在资源稀缺的编程语言上超过了Starcoder和Mistral 7B等模型。
本文素材来源Nemotron-4 15B技术报告,如有侵权请联系删除