所有語言











分享
新加坡國立大學尤洋:高性能 AI 如何突破?
巴比特_雷锋网476天前
來源:雷鋒網
作者:黃楠

過去數年,AI 模型的參數發生了極大變化。尤洋指出,從 2016 年至 2021 年 1 月,AI 模型的參數量是每 18 個月增長 40 倍;從 2018 年 1 月到 2021 年 1 月,AI 大語言模型的參數量每 18 個月增長 340 倍。而相形之下,2016 年 1 月至 2021 年 1 月間,GPU 的內存增長每 18 個月僅有 1.7 倍。
由此可見,訓練成本高、周期長,是當前大模型發展最需要克服的難題。
針對這一問題,尤洋提出了 Colossal-AI 系統,從高效內存系統、N 維并行系統和大規模優化三個層次出發,以實現同樣的設備條件下將數據移動的最小化,將 GPU 的吞吐量擴大至最高點。
尤洋還指出,現階段的模型參數量以 10 萬倍擴大、但層數增加不多,這或意味着:如今的 AI 發展可能不再是深度學習、而是進入了寬度學習時代。在模型變得更寬的情況下,面對大規模、長時間的 GPU 訓練任務,大模型訓練系統的核心將是如何實現 GPU 并行計算,以實現大模型訓練越快越省錢的目標。
以下為尤洋的現場演講內容,雷峰網作了不改變原意的編輯及整理:
AI 大模型的機遇和挑戰
首先展示一張圖片。圖上的橫坐標是時間,縱坐標是 AI 模型的參數量。
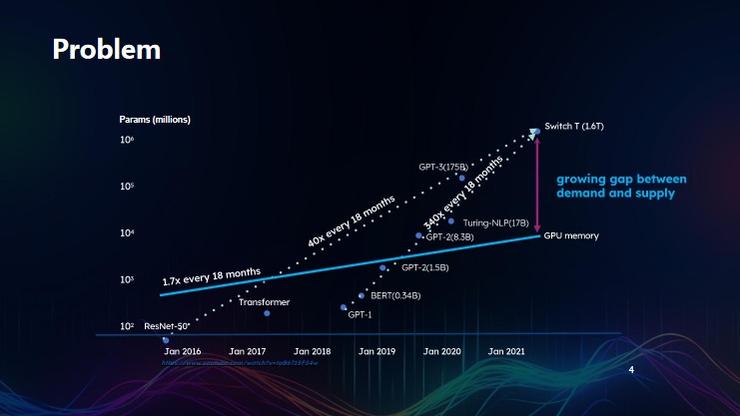
從 2016 年至 2021 年 1 月,AI 大模型的參數量大概每 18 個月增長 40 倍;從 2018 年 1 月到 2021 年 1 月,AI 模型的參數量每 18 個月增長 340 倍。
2016 年,當時世界上最好的模型是 ResNet-50,而今天最好的模型是 GPT-4。從架構上來看,雖然 OpenAI 沒有對外公布 GPT-4 的架構,但對比 ResNet-50 的 50 層神經網絡和 GPT-3 未達 100 層的架構,可以說 AI 模型近年來的層數並沒有產生的太大的變化。
從 ResNet-50 到 GPT-4,雖然參數量大了 10 萬倍左右,其實是每一層都變得更加寬了。包括 LLaMA-65B 版本,也是幾十層的網絡。
所以我們可能不是深度學習,而是進入了一個寬度學習時代。
可以看到,自 2019 年開始, Transformer 架構基本統一了 AI 大模型賽道,當前最高效的 AI 大模型均是 Transformer 架構。上圖中的兩條虛線,既展示了大模型參數的變化趨勢,實際上也展現了 GPU 的變化趨勢。
雖然現在英偉達的股價漲了很多倍,但包括英偉達在內的廠商,其 GPU 內存的增長速度遠跟不上大模型的發展速度。
相較於過去六年模型參數量的增長速度變化,2016 年 1 月至 2021 年 1 月間,英偉達 GPU 的計算增長速度每 18 個月僅增長了 1.7 倍。
以 A100 80G 為例計算 GPT-3 訓練所需的內存數,GPT-3 有大概 1750 億參數,為方便計算取整數 2000 億,等於 200 乘以 10 的 9 次方,每個單精度佔用 4 個字節,僅參數就要佔 800G 內存,梯度也佔了 800G 內存。按照當前的優化方法儲存一階矩(first moment)、二階矩(second moment)等信息均為 800G。也就是說,如果訓練一個什麼事情都不幹大模型,至少需要幾 T 的內存,單個 A100 GPU 僅 80G 內存遠遠不夠,加上中間結果的 batch size 越大,內存開銷也越大。
這也是為什麼從內存角度上看,訓練大模型首先需要有成千上萬個 GPU 的原因。

舉一個可量化的案例。PaLM 是一個 5400 億的大模型,根據當前雲計算市場價,訓練 PaLM 需要承包至少 1000 個 GPU,成本約 900 多萬美金。而 Meta 此前曾明確提到,LLaMA 需要使用到 2000 個 A100 GPU,並且用三周時間才可完成一次訓練,由此計算可得出 LLaMA 單次訓練的成本在 500 萬美金。
但由於煉大模型並不僅限於一次訓練,可能一個好的大模型產品迭代至少需要五六次,前期都是在試錯。因此,據公開渠道分析, GPT-4 單次訓練成本在 6000 萬美金左右,且訓練一次需要至少幾個月時間。這也是為什麼目前 ChatGPT 即便將其升級至最新版本,其底層還是 2021 年 9 月版本的模型。也就是說,從 2021 年 9 月至今,OpenAI 實質上並沒有升級其產品,根本原因就在於,模型的每次訓練不僅成本很高,訓練周期也很長,因此大模型訓練的代價高就非常嚴重。
設想一個問題,今天有一個 1 萬億參數以及 1000 億參數的大模型,我們能否用什麼方法,去檢測萬億參數大模型比千億參數大模型二者哪個效果更好?也即是目前常說的,模型參數量增大、到底要增大到什麼程度?
到今天而言,我覺得這個問題暫時無法用科學回答。原因有幾個。
首先,訓練神經網絡存在非凸優化的問題,目前訓練所收斂的點多為局部最優解、而非全局最優解。因此,我們要驗證神經網絡訓練到什麼程度,在現有計算資源情況下是無法驗證的。
第二個難度在於,大模型訓練往往只訓練一兩個 epoch,而此前的 CNN 模型中,ResNet 訓練有 90 個 epoch,甚至自監督學習訓練有 1000 個 epoch,因此大模型只訓練一兩個 epoch 的方式,相當於只將數據集過了一兩遍,收斂就更加不充分了。因此在訓練成本如此之高的情況下,我們很難驗證,一個 1 萬億參數的模型和 2 萬億參數的模型二者誰更好,因為它們潛力都沒有能通過實驗得到充分發揮。因此我認為,今天 AI 大模型是一個實驗性學科,如何能高效提升這個實驗的效率,降低成本,對整個行業的普及具有根本性的作用。
回到現實之中,為什麼今天人人都在追求大模型?從數學邏輯上看,模型參數越大、效果越好,這是絕對的。
與此同時,成本也再不斷攀高。目前訓練大模型需要成百上千、甚至上萬個 GPU,如何將上萬個 GPU 的成本進一步降低,挑戰非常大的。
在 20 年前,由於當時依靠的是主頻的,所有的程序都是串行的,假設將硬件速度提高 10 倍,在一行代碼都不用的更改的情況下,其運行速度也可以提升 10 倍。但到了如今,如果想將代碼速度提升 10 倍,假定硬件已經增速 10 倍,但如果不優化代碼,很可能速度反而會變慢。原因就在於,機器規模更大的情況下,比如 GPU 內部,GPU 內存和 CPU 之間的數據移動,或是 GPU 間的數據移動,再加上服務器實現的數據移動,會佔據整個系統的大部分時間,把大部分時間都花在了數據移動上,模型的擴展性也會變得不好。
我認為,未來一個好的分佈式軟件和一個差的分佈式軟件,在上千個 GPU 上,甚至 500 個 GPU 上,其速度可能相差 10 倍。
Colossal-AI 如何運行?
基於上述的挑戰,我們提出了大模型訓練系統 Colossal-AI,提供優化方法,降低數據移動的代價,將模型擴展性效率提到最高。
一個具體的數據是,使用最簡單的 PyTorch 訓練 GPT-3,成本為 1000 萬美金,英偉達經過優化后,用 Megatron 可將其成本減少至 300 萬美金,而使用 Colossal-AI 后,成本可以降低到 130 萬美金。可以看到,相同的設備條件下,數據移動的最小化將數據移動佔比降低最低,能夠把 GPU 吞吐量擴大至最高點。

針對上述問題,Colossal-AI 提出了三個層次。其他類似的軟件也包括了這三個層次。
第一層是優化內存,先確保單個 GPU、單個服務器的內存效率最高,這是基礎。
第二層是 N 維的并行。當前我們使用上千、上萬個 GPU 時,其核心技術就是 ParallelComputing(并行計算)。從 1 個 GPU 擴到 10 個 GPU,因為其規模比較小,我們可以輕易獲得 7 倍加速;從 10 個 到 100 個 GPU 時,往往可能只獲得 4 倍加速,因為并行規模變大,它的通信代價變高了。而從 100 個 GPU 到 1000 個 GPU,因為通信代價進一步加高,很可能只獲得 2 倍的加速。而從 1000 個 GPU 到 1 萬個 GPU,如果軟件運行情況不佳時,不僅可能無法加速,甚至還會更慢,因為設備將所有時間花耗在了更高密度的通信上。
其次是優化問題,未來 AI 大模型的發展方向我認為有兩層,第一層是模型變得更加智能,設計出更好的結構,比如說從 BERT 到 GPT,或者從 ResNet 到 BERT等,都是在不斷地嘗試改變模型結構。
此外還有優化方法的進步,從 SGD 過渡到 MOMENTUM、ADAGRAD,到現在有 ADAM,未來又會有哪些更好的優化方法能夠將效率提升 10 倍,這一點也非常重要。
具體到實際操作訓練大模型的并行問題。
首先是數據并行,這是最簡單、也是最高效的并行方法。數據并行指的是,假設現有 1 萬張圖片,每次循環處理 1000 張圖片,如果有 10 個機器,每個機器分配 100 張,10 個循環即可完成所有圖片的處理。
在數據并行的過程中需要進行匯總,每個機器用不同的數據獲得不同梯度,機器在不同數據上學習不同的更改,並更新參數梯度,最後算出全局梯度,目前採用的是加和求平均的方式,效果已經非常好了。此前 Colossal-AI 在數據并行中的 LARS 方法,就為谷歌、 Meta、騰訊、索尼等公司,將 ImageNet 的訓練時間從一小時縮短至一分鐘。
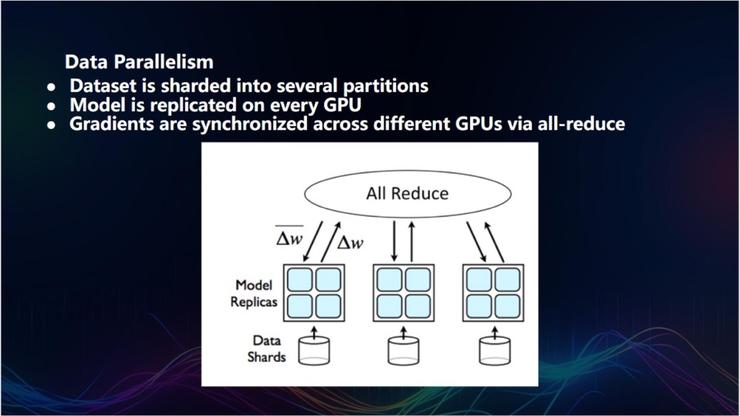
數據并行是最基本的,同時也是最穩定的。將數據劃分之後,假設未來有 1 萬個 GPU,很容易發生的情況是,隔幾個小時就有四五個 GPU 崩潰了,運維 1 萬個 GPU 的集群很難,但數據并行的穩定之處在於,即便有 1 萬個GPU 崩潰了十幾個,但大體結果是不會變的,因為它是梯度加和求平均。
基於這個考慮,我認為數據并行是一個根本性的基礎設施。
當然,僅用數據并行並不夠,原因在於:數據并行有一個假設,必須將模型拷貝到每個 GPU 或服務器內,由服務器或 GPU 去交換梯度。但如果 GPU 僅 80G 內存時,萬億參數的模型則需要幾十 T 的內存,這在 GPU 中是無法存放的,需要將模型切割至不同的 GPU 上再匯總結果。這種方法叫做模型并行。模型并行包括兩種,第一種是張量并行( tensor paralism),即層內的模型并行。例如 GPT-3 的層數大概為八九十層,每層切割一次模型,將其層內計算分隔成多份,算完一層再算下一層,依次類推,這就是張量并行。
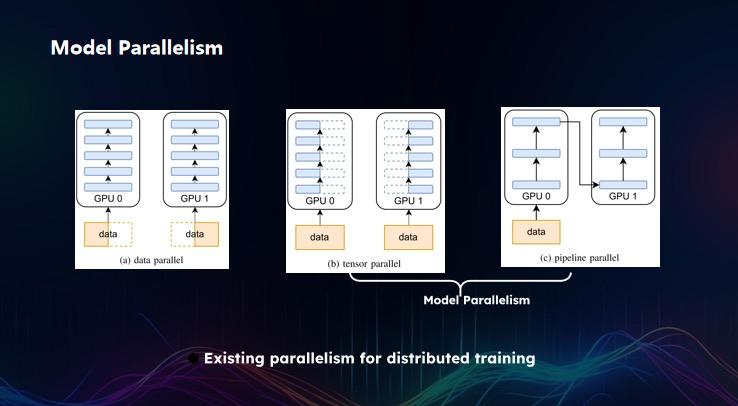
另一種方式則是 Pipeline Parallelism(流水線并行),介於數據并行和張量并行外的一種模型并行方式。通過構建幾個數據 pipe(管道),每個數據 pipe 的數據點不同,相當於將一個大尺寸分割為多個小尺寸,通過這種方式進行 pipe 計算。假如有 10 個 pipe,10 個 pipe 代表十組不同的數據,第一個 pipe 計算第一層的數據,第二個 pipe 計算第二層......以此方式并行,類似我們蓋樓一樣,10 個工程隊蓋 1000 層樓,當第一個工程隊在蓋第一棟樓的第一層,第二個工程隊蓋第二棟樓的第二層,依此類推。
當樓數越多,樓和工程隊之間的比值越高,效率也越高,相當於 10 個工程隊在同時運轉。其中每個工程隊就相當於一個 GPU,每個樓就相當於一個 pipe,樓的層數相當於這個神經網絡的層數,這就流水線并行的核心邏輯。
目前工業界已經做了相關的工作,除了 Colossal-AI 之外,還有英偉達的 TensorRT 和微軟的 DeepSpeed,他們也是技術壁壘最高的兩家公司。
但 Colossal-AI 與其不同之處是,Colossal-AI 專註於未來大模型的發展方向。可以看到,當前的模型還在變得更寬,而不是變得更深,張量并行將會更加重要,但它最大的弊端就在於,因為它是切割的是整個層,通信開銷太大。這也是為什麼英偉達 CEO 在 GTC 峰會上首次介紹 3D 并行時特別說明其通信開銷太大的問題,只能放到一個服務器內去做。因此,Colossal-AI 主打 2D 張量并行和 2.5D 張量并行,將計算成本降低了一個數量級。
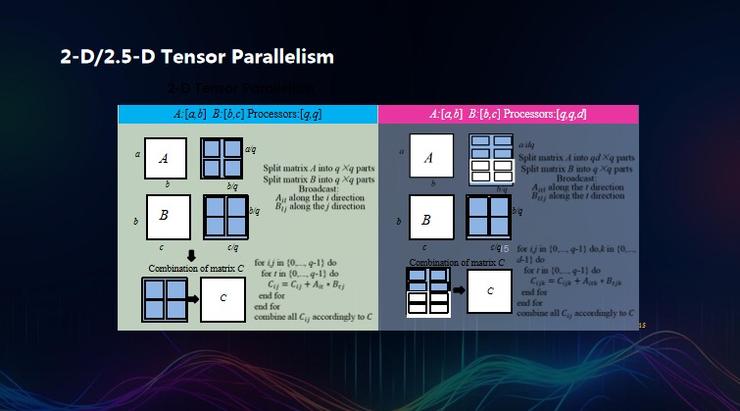
這就意味着用一維張量并行,1 萬個機器里,每個機器都需要跟 9999 個機器打交道,而 2D 張量并行則是將其分成了各個子單元,每個機器只需要跟 96 個機器打交道。它的核心邏輯是,用一些 local synchronization(局部同步)去取代global synchronization(全局同步),以更多的局部通信去取代全局通信,這個過程中,設計調度是最困難的。
3D 張量并行也是同樣,每升高一個維度,它的設計複雜度會高一個數量級,最終通信複雜度下降了。
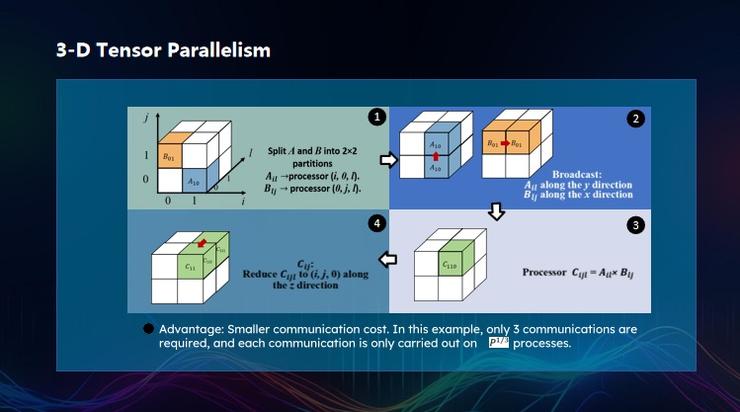
在內存優化方面,目前 AI 大模型訓練的內存開銷很大,即便什麼事情都不做,也需要幾 T 的內存,如果不進行人工干預,一旦使用起來,可能需要幾十 T 甚至是幾百 T 的內存。
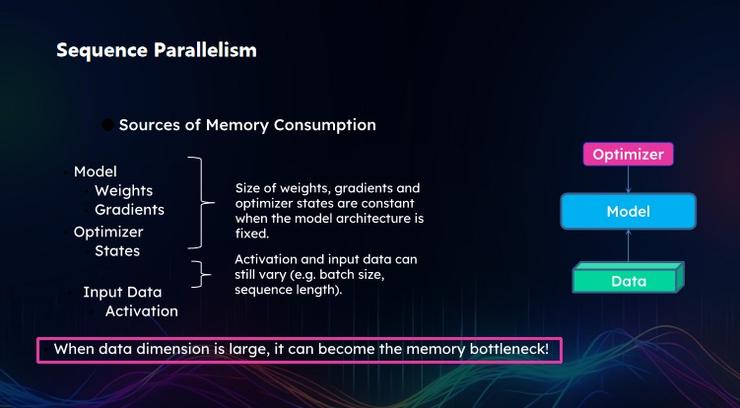
為了讓模型預測效果更好,我們往往需要長序列數據,當前大模型的本質是通過一個單詞的輸出來預測下一個單詞的概率,長序列成為剛需。對此, Colossal-AI 也推出了 Sequence Parallelism(序列并行)。
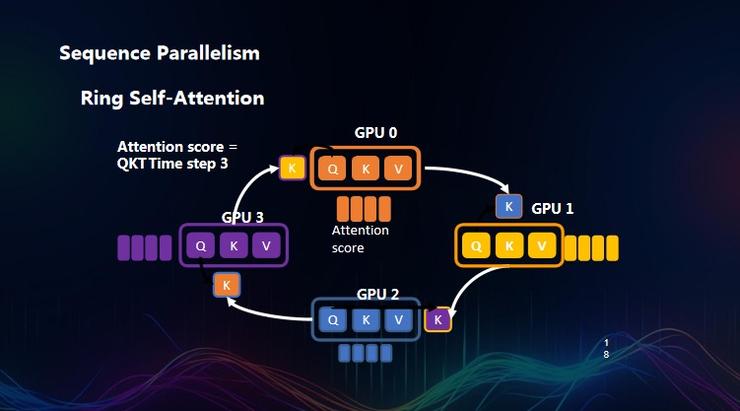
具體而言,在將序列進行切割后,會面臨一個嚴重的問題是:在進行 attention score 時,每個 token 都需要跟全局序列中的其他 token 去評估,而切分后的服務器上只有部分 token,其他服務器上也會分佈不同的 token,以至於每個服務器運行是需要同其他服務器打交道。
也就是說,假設今天屋子里 200 個人每人分別拿了一包零食,我希望每個人能品嘗下其他所有人的零食,至少需要 200 個平方次交換,才能讓每個人都嘗到其他人的所有零食。那麼最簡單的方式是:所有人圍一個圈,每個人將自己吃過的零食遞給右手邊的人,從自己的左手邊獲得零食,僅需 n-1 次,即 199 次的傳遞即可完成。從而降低了整個通信成本。
總結一下,目前 AI 大模型訓練的核心技術棧,其實就是并行計算,因為我們要處理成百上千上萬個 GPU 核心,把所有 GPU 并行利用起來。數據并行、張量并行、流水線并行以及數據序列并行是并行中較為核心的模塊。
目前在內存優化方面,我們處於一個沒有太多選擇的環境,英偉達 GPU 是最好的,我們好像也沒有其他更好的方案能夠去取代它。但美中不足的是,英偉達 GPU 的內存有限,在這種情況下,我們能否思考如何利用 CPU 內存、NVMe內存,核心思想就是,GPU 內存放不下就移到 CPU 上,CPU 放不下就放到 NVMe 上,相當於在蓋樓時,所需要的原材料自家樓下工地放不下,那我們就將其放到隔壁工廠。其技術的核心也在於最小化數據移動,即最小化 CPU、 GPU 之間的數據移動,最強化 CPU 和 NVMe 之間的數據移動,從而將吞吐力速度提升到最高。
走向開源
Colossal-AI 是一個開源軟件,同時我們也做了一個商業化的平台,對沒有 GPU 的用戶,可以直接在平台上去訓練部署自己的大模型。我們也提供了 LLaMA、PaLM、 GPT 等各種模型,最快僅需兩三天就可完成一個模型微調。相比之前用戶可能需要幾周、乃至幾個月來處理硬件、軟件等基礎設施,效率得到了極大提升。同時,Colossal-AI 也保護用戶的隱私,平台不會保留、訪問用戶數據,這是 Colossal-AI 與 OpenAI ChatGPT 的本質區別。我們將數據上傳至 Google Cloud 時,很多時候 Google 並沒有碰我們的數據,但是 OpenAI GPT 會進行分析,AI 模型的不可解釋性、訓練不徹底等風險普遍存在。因此,未來也會有很多企業訓練自己的大模型,Colossal-AI 做的,是最大化保護用戶的隱私,同時提供大模型訓練的工具。
在性能上,Colossal-AI 在同樣的硬件上可以訓練24 倍大的模型,相對於 DeepSpeed 的 3 倍加速,即便是一個低端的服務器,也可以藉助 Colossal-AI 完成相應的模型訓練。例如 LLaMA-65B 的訓練,在 Colossal-AI 上使用同樣的代碼放,可以直接獲得約 50% 的加速效率。
一個簡單的比喻,比如說現在大模型是挖金子,英偉達是賣鏟子的,那我們就是賣手套、賣衣服的,把挖金子的效率提到最高。