所有語言











分享
給文心一言做標註,一個月4000元
巴比特_品玩471天前
來源:品玩
作者:油醋
“有多少智能,就有多少人工”。
戲謔的話藏在人工智能背面,目前為止依然成立。剛從大學里走出來的丁洋,前途暫時踩在這後半句上。
丁洋大學時學的輕化工程,畢業后系裡同學的去向大多是三班倒的造紙廠,他不想去工廠。今年6月份畢業后,丁洋從回到海口,8月初拿着一本电子版訓練題庫,兩天後成為文心一言的“新手”數據標註員。
海口市秀英區的招商局大廈,文新一言的數據標註員們習慣把這裏叫做“基地”。兩百多人在這個基地進出,分佈於這樁寫字樓的其中三層,入職前要簽保密協議,進門要刷臉,一人一台電腦,不少電腦還是老闆從山西租了運過來的,因為在當地租這些設備熟人不多。
“這電腦買來500塊錢都不用,我有次把主機拿去閑魚上搜——就值60塊錢。500塊我能裝一個比這好得多的。”
丁洋高考時候報的計算機,後來被調劑到了輕化工程,但他感興趣的不是這個,反而在大學時看了很多計算機和軟件工程的東西,這也讓他在去年年底很快聽說了ChatGPT的出現。
12月,他註冊了個ChatGPT賬號,然後“能力比較超出我的預知”,他說。
圖源:品玩
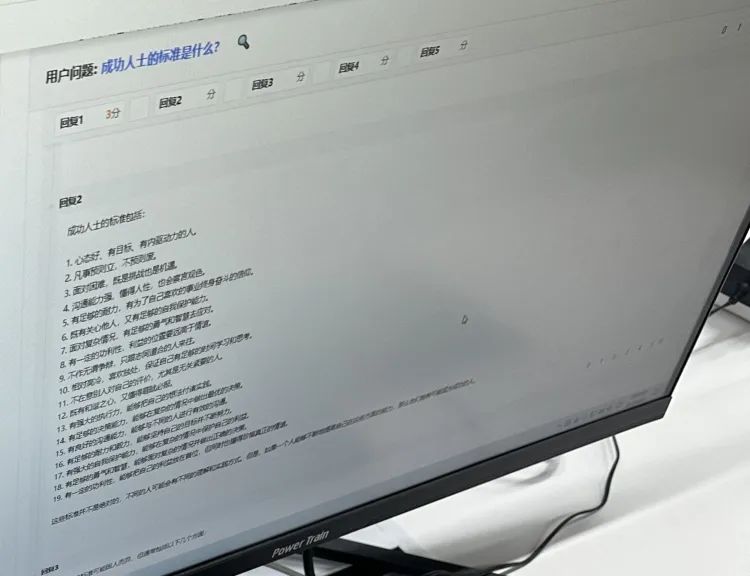
我在基地的工位碰到丁洋的時候,他眼前電腦屏幕上的問題是:“成功人士的標準是什麼?”
這可能是某位文心一言用戶的真實問題,也可能是憑空生成的一個測試題,但擺到屏幕前了,需要被標註。
標註並不容易。
一個這樣的問題下面會有五個文心一言給出的不同回答。數據標註員要看完,然後把每個回答里所有的瑕疵都找出來。
比如回答中的錯別字或者“因為”“所以”之類的邏輯詞錯用,但更多是答非所問,或者某段話里出現了完全沒有事實依據的所謂“幻覺”。
他要給這五個答案按回答質量打分,滿分5分,一共五檔,最低1分。3分及以下的回答,丁洋需要把每處錯誤各自劃分到標註系統給出的不同錯誤類型里。
這複雜的糾錯過程是在訓練生成合適的獎勵模型RM(reward model,也叫偏好模型),打分和排序的動作會讓模型進一步與人類的偏好對齊。
這也是ChatGPT的取勝鑰匙,OpenAI的論文中曾描述過這個在指令微調(Instruction tuning)過程中讓人工智能向人類想法對齊的過程。
在數據標註員的工作之前,需要一些更專業的人員把發散的語料變成具體的問答對,然後像例題一樣餵給大模型,後者在大量問答對的數據訓練之後得到優化后,開始自己答題。
數據標註員在這一階段為大模型生成的答案質量從安全性、準確性、相關程度等角度做出評價,這些評價數據進一步訓練出一個獎勵模型。最終這個獎勵模型會代替人工標註的工作。
OpenAI超過300億美元的估值背後,是大量時薪不到2美元的肯尼亞數據標註勞工,要不然它在去年12月也到不了丁洋麵前。
但丁洋並不知道RM或是SFT之類的定義,他說上手前的培訓中沒有這些過於理論的內容,這裏甚至有人不知道自己為之工作的文新一言是什麼。但這不要緊,要緊的是把事情做完。
這份早九晚六,做六休一的工作,底薪1800元。一個月下來,如果平均每天能標註夠40道題,底薪就拿到了。底薪按完成率算,提成則要把正確率也考慮進去。多來一段時間的“老手”的穩定工作量是一天7、80個,遇到的問題難度也高些。平均下來,一個月可以拿到4000元,如果努力一點,比如每天標註100道題左右的話,一個月可以拿到7000元。
對於丁洋這樣剛畢業的學生來說,4000元算是一份起步不低的工作。海口人平均月工資只有3000元出頭,甚至10個人里有6個人一個月拿不到3000元。本地有名的后安粉要賣11元,ChatGPT的標註員干一個小時能買一碗。相比之下,粉算貴的。按他的話說,海口人錢賺的不多,但在吃東西上捨得下手。

圖源:品玩
“股票是最難的,或是汽車”,丁洋說。碰到這方面的問題一道可能就要花20分鐘。
“比如會有人問是該買寶馬3系還是奔馳C系”,這時候大模型會把關於兩款車的80多個參數統統列出來去給用戶比較,他就得跟在屁股後頭去一一核實每個參數的真實性。
工作半個月也標註了大幾百道題了,但他說自己印象里能拿到3分就已經不錯,鮮有4分的。
他記得一道拿到4分的題,題目是“林黛玉為什麼要打白骨精?”
文心一言沒順着竿爬,反應過來打白骨精的不是林黛玉,然後再介紹了林黛玉和白骨精各自的人物背景。從回答質量的各個維度來看,這都幾乎無可挑剔。
我把這個問題提給了Claude 2,它說:“白骨精化身為王熙鳳多次羞辱林黛玉,林黛玉對白骨精的戕害感到憤怒。”——幻覺這件事確實夠麻煩的。

圖源:品玩
2020年初,“人工智能訓練師”正式成為職業並納入國家職業分類目錄,兩年後大模型的浪潮突然在這個目錄上劃開一個更大的口子。
眼看着人工智能拿走人類的舊工種,然後寄希望於它會創造出新的。就像那個馬車被汽車取代,新工業會給馬車車夫一個勞動致富新世界的籠統比喻,大把揣着錢找標的的投資人對這個說法買賬,也有人不買,比如曾經奠定深度學習基礎,現在卻憂心忡忡的英國人傑弗里·辛頓。
但眼下最直接的創造就是丁洋這樣的大模型數據標註員。
在2022年之前,那個人工智能前沿陣地仍然被駕馭不了自己的自動駕駛所定義的時期,對於數據標註員有一個冷冰冰的比喻:
“如果你把AI看成動物的話,數據標註員的工作大致就相當於準備飼料。”
這個工作便宜,重複——甚至夠不上是個喂飼料的。
一個傳統的數據標註員,每天的工作僅僅是仔細地觀察每張接收到的圖像,圈出一輛汽車或者一隻狗的輪廓,打上標籤,拖放到不同的文件夾里;或者用點陣工具將一段行駛錄像中每一幀畫面里的障礙物標記出來,留出一個完整的“可行駛區域”。
這樣的動作一位數據標註員一天可能要做2000次。
只有經過標註的數據才能被人工智能學習。一家自動駕駛數據供應商曾表示,數據標註發展至今,自動化的程度仍然只有5%,另外95%的標註工作仍是以人工完成。
大模型來了之後,數據標註這個工種本身也開始變化。不只是對着屏幕簡單的拉框、描點或者劃線,大模型數據標註員主要的工作變成對生成內容的評估、排序和打分,如果涉及多輪對話或是多模態的內容生成,難度又陡增。
如果說傳統CV和NLP時代的模型標註更傾向於按照客觀規則行事,大模型的標註規則要主觀的多,也更考驗標註人員的素質。也因為這樣,百度在海口和山西的大模型標註團隊里全是本科以上的。
海口基地里的普通標註員有機會晉陞為質檢員,再往上可以做培訓師,再做主管,最後則是項目經理。這是一條幾個月內建立起來的通道。一位在海口為文心一言做數據標註的代理商表示,過了試用期后,內部有崗位就可以晉陞,沒有時間線。
這是個極速成型的新行業。“每一個環節上都是新人”,丁洋說。
質檢員做完第一道審核后,會把題庫交給第二道審核。第二道審核是百度內部來審,這些訓練數據也就脫了丁洋所在標註團隊的手。
為文新一言工作的丁洋和整個基地的200多人,算不上是百度的員工。
海口基地里的標註人員歸屬於四個不同的代理商。他們的勞務合同是和這些第三方數據標註公司簽的。這是這個崗位的慣例,百度從搜索到自動駕駛到大模型的漫長人工智能歷史,背後是全國超過600多個代理商,遍布300多個城市的20萬數據標註人員。
百度給自己大模型專職團隊的規模預設接近萬人,這個計劃將會兌現成未來全國十多個城市的新的“基地”。
百度智能雲數據標註基地業務產品負責人胡馳相信,大模型數據標註員將會是一個長期的職業。隨着大模型能力在各個場景深入,新的問題會出現,也意味着新的標註需求會出現,人類永遠需要這樣一種勤勉的對齊方式。
丁洋說,他會離開這兒的。
和他同一時間進來的新手數據標註員有20多人,很快已走了大半——多半是主動離開。工作內容的枯燥、計件工資的賺錢方式、對人的消耗,不難想象這會是個高流動性的崗位。而且不管再怎麼有人叫好,人被機器取代的不安全感就在那裡,這是所有人喜聞樂見的。
丁洋把這裏看作一個能跟着這個產業一起成長的機會。“試試看能不能做到主管”,他說,然後去找一個離這場人工智能浪潮更近的位置。
(文中丁洋為化名)