所有語言











分享
支持20萬字輸入,Moonshot AI開啟千億大模型的“長文本”時代
巴比特_品玩429天前

圖片來源:由無界 AI生成
2023年10月9日,成立僅半年的大模型初創公司 —— Moonshot AI宣布在“長文本”領域實現了突破,推出了首個支持輸入20萬漢字的智能助手產品Kimi Chat。這是目前全球市場上能夠產品化使用的大模型服務中所能支持的最長上下文輸入長度,標志著Moonshot AI在這一重要技術上取得了世界領先水平。
從技術上看,參數量決定了大模型支持多複雜的“計算”,而能夠接收多少文本輸入(即長文本技術)則決定了大模型有多大的“內存”,兩者共同決定模型的應用效果。支持更長的上下文意味着大模型擁有更大的“內存”,從而使得大模型的應用更加深入和廣泛:比如通過多篇財報進行市場分析、處理超長的法務合同、快速梳理多篇文章或多個網頁的關鍵信息、基於長篇小說設定進行角色扮演等等,都可以在超長文本技術的加持下,成為我們工作和生活的一部分。
相比當前市面上以英文為基礎訓練的大模型服務,Kimi Chat具備較強的多語言能力。例如,Kimi Chat在中文上具備顯著優勢,實際使用效果能夠支持約20萬漢字的上下文,2.5倍於Anthropic公司的Claude-100k(實測約8萬字),8倍於OpenAI公司的GPT-4-32k(實測約2.5萬字)。同時,Kimi Chat通過創新的網絡結構和工程優化,在千億參數下實現了無損的長程注意力機制,不依賴於滑動窗口、降採樣、小模型等對性能損害較大的“捷徑”方案。
目前,Moonshot AI 的智能助手產品Kimi Chat已開放了內測。
大模型輸入長度受限帶來的應用困境
當前大模型輸入長度普遍較低的現狀對其技術落地產生了極大制約,例如:
目前大火的虛擬角色場景中,由於長文本能力不足,虛擬角色會輕易忘記重要信息,例如在Character AI的社區中用戶經常抱怨“因為角色在多輪對話后忘記了自己的身份,所以不得不重新開啟新的對話”。
對於大模型開發者來說,輸入prompt長度的限制約束了大模型應用的場景和能力的發揮,比如基於大模型開發劇本殺類遊戲時,往往需要將數萬字甚至超過十萬字的劇情設定以及遊戲規則作為prompt加入應用,如果模型輸入長度不夠,則只能削減規則和設定,從而無法達到預期遊戲效果。
在另一個大模型應用的主要方向——Agent中,由於Agent運行需要自動進行多輪規劃和決策,且每次行動都需要參考歷史記憶信息才能完成,這會帶來了模型輸入的快速增加,同時也意味着不能處理更長上下文的模型將因為無法全面準確的基於歷史信息進行新的規劃和決策從而降低Agent運行成功的概率。
在使用大模型作為工作助理完成任務的過程中,幾乎每個深度用戶都遇到過輸入長度超出限制的情況。尤其是律師、分析師、諮詢師等職業的用戶,由於常常需要分析處理較長的文本內容,使用大模型時受挫的情況發生頻率極高。
而上述所有的問題在大模型擁有足夠長的上下文輸入后都將會迎刃而解。
長文本打開大模型應用的新世界
那麼擁有超長上下文輸入后的大模型會有怎樣的表現?下面是一些Kimi Chat實際使用的例子:
公眾號的長文直接交給Kimi Chat ,讓它幫你快速總結分析
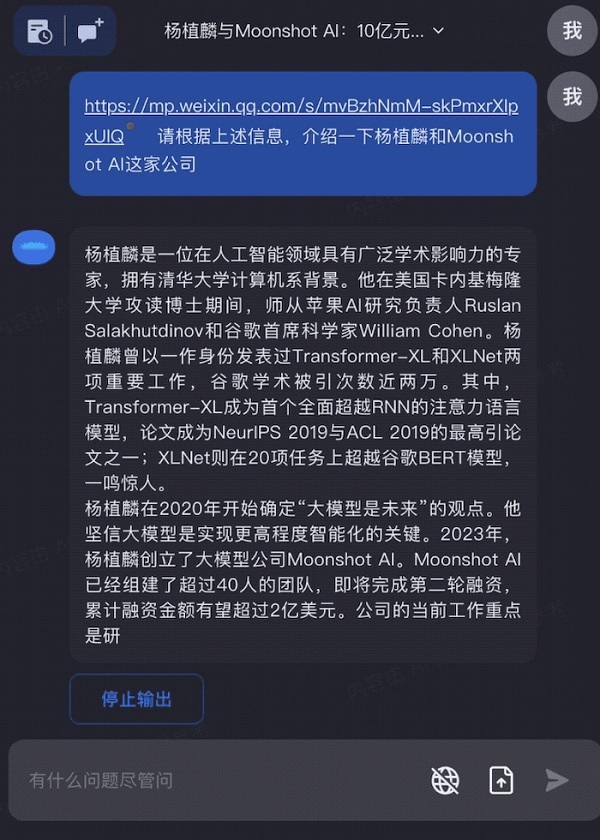
新鮮出爐的英偉達財報,交給Kimi Chat,快速完成關鍵信息分析:
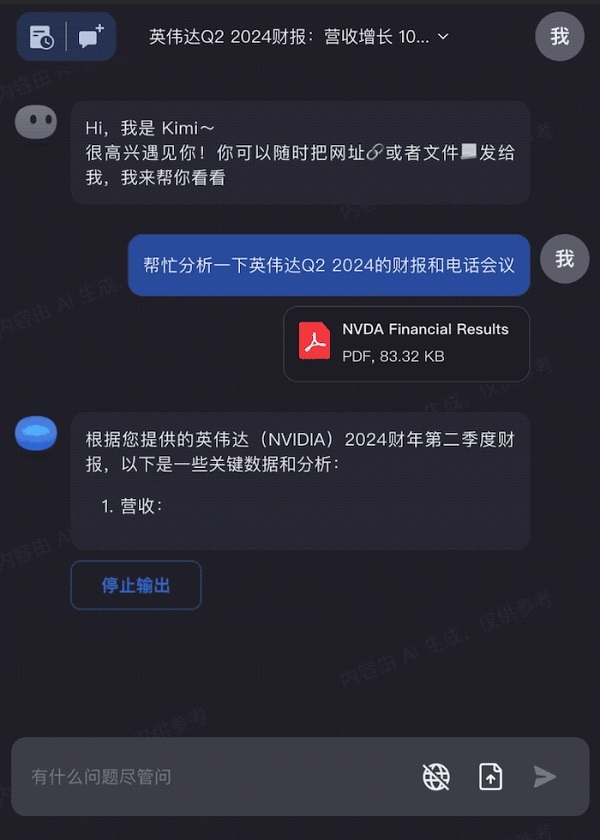
出差發票太多?全部拖進Kimi Chat,快速整理成需要的信息:
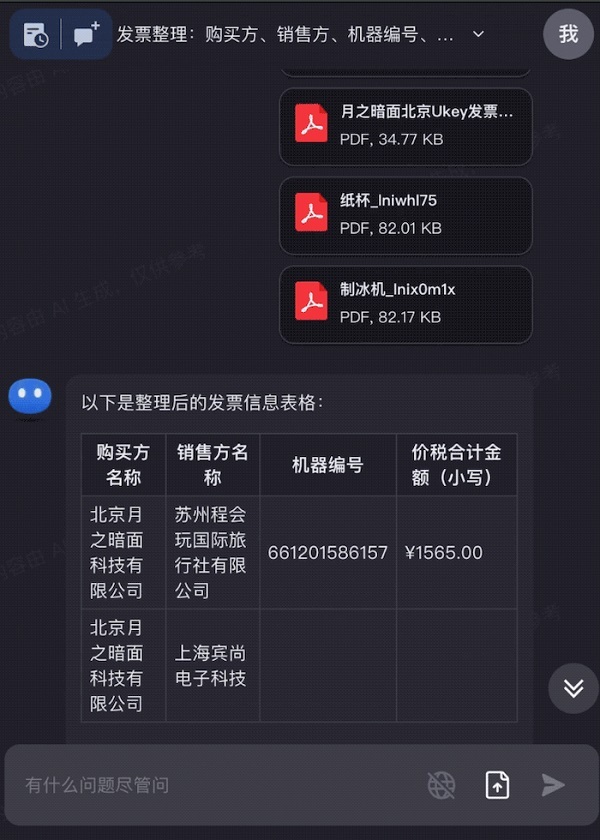
發現了新的算法論文時,Kimi Chat能夠直接幫你根據論文復現代碼:
只需要一個網址,就可以在Kimi Chat中和自己喜歡的原神角色聊天:
輸入整本《月亮與六便士》,讓Kimi Chat和你一起閱讀,幫助你更好的理解和運用書本中的知識:
通過上述例子,我們可以看到,當模型可以處理的上下文變得更長后,大模型的能力能夠覆蓋到更多使用場景,真正在人們的工作、生活、學習中發揮作用,而且由於可以直接基於全文理解進行問答和信息處理,大模型生成的“幻覺”問題也可以得到很大程度的解決。
不走捷徑,解決算法和工程的雙重挑戰
長文本技術的開發,存在一些對效果損害很大的“捷徑”,主要包含以下幾個方面:
“金魚”模型,特點是容易“健忘”。通過滑動窗口等方式主動拋棄上文,只保留對最新輸入的注意力機制。模型無法對全文進行完整理解,無法處理跨文檔的比較和長文本的綜合理解(例如,無法從一篇10萬字的用戶訪談錄音轉寫中提取最有價值的10個觀點)。
“蜜蜂”模型,特點是只關注局部,忽略整體。通過對上下文的降採樣或者RAG(檢索增強的生成),只保留對部分輸入的注意力機制。模型同樣無法對全文進行完整理解(例如,無法從50個簡歷中對候選人的畫像進行歸納和總結)。
“蝌蚪”模型,特點是模型能力尚未發育完整。通過減少參數量(例如減少到百億參數)來提升上下文長度,這種方法會降低模型本身的能力,雖然能支持更長上下文,但是大量任務無法勝任。
簡單的捷徑無法達到理想的產品化效果。為了真正做出可用、好用的產品,就不能走虛假的捷徑,而應直面挑戰。
訓練層面,想訓練得到一個支持足夠長上下文能力的模型,不可避免地要面對如下困難:
如何讓模型能在幾十萬的上下文窗口中,準確的 Attend 到所需要的內容,不降低其原有的基礎能力?已有的類似滑動窗口和長度外推等技術對模型性能的損害比較大,在很多場景下無法實現真正的上下文。
在千億參數級別訓練長上下文模型,帶來了更高的算力需求和極嚴重的顯存壓力,傳統的 3D 并行方案已經難以無法滿足訓練需求。
缺乏充足的高質量長序列數據,如何提供更多的有效數據給模型訓練?
推理層面,在獲得了支持超長上下文的模型后,如何讓模型能服務眾多用戶,同樣要面臨艱巨挑戰:
Transformer模型中自注意力機制(Self Attention)的計算量會隨着上下文長度的增加呈平方級增長,比如上下文增加32倍時,計算量實際會增長1000倍,這意味着如果只是用樸素的方式實現,用戶需要等待極其長的時間才能獲得反饋。
超長上下文導致顯存需求進一步增長:以 1750 億參數的 GPT-3為例,目前最高單機配置( 80 GiB * 8 )最多只能支持 64k 上下文長度的推理,超長文本對顯存的要求可見一斑。
極大的顯存帶寬壓力:英偉達A800 或 H800的顯存帶寬高達 2-3 TiB/s,但面對如此長的上下文,樸素方法的生成速度只能達到 2~5 tokens/s,使用的體驗極其卡頓。
Moonshot AI的技術團隊進行了極致的算法和工程優化,克服上述困難完成了大內存模型的產品化,發布了支持20萬字輸入的千億參數LLM產品。
“登月計劃”第一步:歡迎來到 Long LLM 時代
Moonshot AI創始人楊植麟此前在接受採訪時曾表示,無論是文字、語音還是視頻,對海量數據的無損壓縮可以實現高程度的智能。
無損壓縮的進展曾極度依賴「參數為王」模式,該模式下壓縮比直接與參數量相關,這極大增加了模型的訓練成本和應用門檻,而Moonshot AI認為:大模型的能力上限(即無損壓縮比)是由單步能力和執行的步驟數共同決定的。單步能力與參數量正相關,而執行步驟數即上下文長度。
Moonshot AI相信,更長的上下文長度可以為大模型應用帶來全新的篇章,促使大模型從 LLM時代進入Long LLM (LLLM)時代:
每個人都可以擁有一個具備終身記憶的虛擬伴侶,它可以在生命的長河中記住與你交互的所有細節,建立長期的情感連接。
每個人都可以擁有一個在工作環境與你共生(co-inhabit)的助手,它知曉公域( 互聯網)和私域(企業內部文檔)的所有知識,並基於此幫助你完成OKR。
每個人都可以擁有一個無所不知的學習嚮導,不僅能夠準確的給你提供知識,更能夠引導你跨越學科間的壁壘,更加自由的探索與創新。
當然,更長的上下文長度只是Moonshot AI在下一代大模型技術上邁出的第一步。Moonshot AI計劃憑藉該領域的領先技術,加速大模型技術的創新和應用落地。
登月計劃的夥伴說:
Monolith礪思資本專註於新一代数字產業和科技智造領域的投資,是Moonshot AI第一輪融資的3家投資機構之一,並一直以實際行動支持着公司發展。礪思資本創始合伙人曹曦表示,楊植麟是全球大模型領域里最被認可的華人技術專家,其團隊在人工智能技術,特別是大語言模型LLM領域擁有深厚的技術積累,並已在國際上獲得了廣泛認可。眼下,美國硅谷的OpenAI和Anthropic等公司獲得了多方關注,實際上在國內,擁有足夠多技術儲備的Moonshot AI也正成長為全球領先的AGI初創公司。多模態大模型是各家AI廠商競爭的關鍵領域,其中長文本輸入技術更是其核心技術之一,Moonshot AI團隊最新發布的大模型和Kimi Chat在這方面實現了重要突破,並已成功應用於多個實際場景。礪思將繼續加碼並支持Moonshot AI團隊在AGI領域大膽創新和技術突破,引領中國人工智能技術的未來發展。
真格基金合伙人戴雨森對公司的發展表達了肯定和期許:“我們認為近期AI應用的爆火只是一場革命的序幕,AI技術要想真正改變世界創造巨大價值,在智能程度上還需要大的突破,這需要具備頂級技術能力的團隊,以堅持追尋Moonshot的勇氣,持續挑戰智能提升的邊界。楊植麟作為XLNet等多項知名科研工作的第一作者,具備非常豐富的科研和實踐經驗,多年來他一直堅信通過大模型實現對高維數據的壓縮是人工智能發展的必經之路,也團結了一支人才密度超高,配合默契,又充滿挑戰巨頭搖滾精神的創業團隊。真格基金非常榮幸能夠再次從天使輪開始支持楊植麟的新征程。”
關於 Moonshot AI
Moonshot AI 創立於 2023 年 3 月,致力於尋求將能源轉化為智能的最優解,通過產品與用戶共創智能。創始團隊核心成員參与了 Google Gemini、Google Bard、盤古NLP、悟道等多個大模型的研發,多項核心技術被Google PaLM、Meta LLaMa、Stable Diffusion等主流產品採用。Moonshot AI 融資超2億美元。