所有語言











分享
大模型手機,扎堆來了!
巴比特_雷科技458天前
原文來源:雷科技

圖片來源:由無界 AI生成
今年初,微軟創始人比爾·蓋茨在接受德國商報採訪時感概:「ChatGPT 像互聯網發明一樣重要,將會改變世界。」
過去將近一年的時間里,大模型幾乎可以說是最炙手可熱的一種技術、趨勢和概念,一方面從大眾到全球各國政府的關注,另一方面是所有科技互聯網公司都在加速布局大模型,就算沒有構建大模型(在開源大模型的基礎上)的技術實力,也在緊迫地尋找業務與大模型的結合點。
同樣地,沒有一家手機廠商打算錯過大模型。
不過嚴格來說,目前手機行業還處於 AI 大模型的混戰前夜。儘管所有人的共識都是把大模型帶到手機上,但在實現路徑上還是各有想法,同時一些廠商已經只差臨門一腳,就能將大模型正式帶到手機上,另一些廠商還差一些準備,還有一些處於更早的準備階段。
大亂鬥倒計時

圖/ OPPO
就在這幾天,OPPO 宣布將在 11 月 16 日舉行 ColorOS 14 發布會,同時還宣布基於 AndesGPT 大模型打造的新版 AI 助手——新小布 1.0 開啟了第一輪公測。
同一天,OPPO 宣布將與聯發科合作,共建輕量化大模型終端部署方案。
按照 OPPO 的說法,AndesGPT 大模型作為 OPPO 自主訓練的生成式用戶專屬大模型,以「端雲協同」為基礎架構設計思路,推出從 10 億至千億多種不同參數規模的模型規格,實現本地與雲端協同運作的效果。不過更具體的,還要等到發布會上或者之後揭曉了。
但其實更早之前,華為已經在國內率先掀起了手機大模型的戰爭「號角」。

圖/雷科技
8 月初,我參加了華為舉辦的開發者大會,華為在會上就宣布 HarmonyOS 4 的全新小藝 AI 助手將率先接入大模型。不過還要到 8 月下旬,華為才是真正開啟全新小藝的邀請測試。
全新小藝是在華為雲自研盤古大模型的基礎上,融入了大量的場景數據,並對模型進行精調,核心是一個對話模型,這方面從將小藝作為大模型的接入點也可以看到。
另一方面,由於主要依賴雲端算力,理論上所有支持升級到 HarmonyOS 4 的機型後續體驗到全新小藝。
小米的小愛大模型其實也是一樣。

雷軍年度演講,圖/小米
8 月 14 日,小米比華為還早就開啟了小愛大模型的邀請測試活動,覆蓋從 Redmi Note9 系列到小米 MIX Fold 3 等大量機型,還包括部分智能音箱,比如小米 Sound。
雖然在 8 月的那場年度演講上,雷總提到小米自研端側大模型 MiLM,走了輕量化的路線,宣稱將 13 億參數版本塞進手機,可以實現部分場景媲美雲端大模型的效果,做到百億內參數大模型的第一。
但考慮到從高端機到低端機的覆蓋,顯然不可能主要依賴本地計算。
按照小米 AI 實驗室大模型團隊負責人欒劍的說法,小米會先選擇在內存最大、算力最強的手機上做實驗(大模型 MiLM)。
最大的可能是小米做了兩手準備,也許是受限於性能和功耗,目前開啟邀測的小愛大模型走了雲端路線,端側路線的 MiLM 只能在高端型號乃至未來機型上搭載運行。
雲端大模型和終端大模型都想要,谷歌大概會是小米的目標。
PaLM 2 壁虎,圖/谷歌
今年 5 月的谷歌 I/O 開發者大會上,谷歌就宣布了新一代大模型 PaLM 2 將具備四個參數規格的版本,最大的「獨角獸」擁有 5400 億參數,最小的「壁虎」則專為智能手機而適配,在離線狀態下也能實現每秒 20 個 token 的處理。
就在本月初,谷歌正式發布 Pixel 8 系列手機,其中明確 Pixel 8 Pro 在自研芯片 Tensor G3 的加持下,真正實現了在手機上本地運行大模型。
基於本地運行的大模型,谷歌還設法改進了用於照片後期處理的魔術橡皮擦功能,以及更智能的銳化和細節增強,其他還包括錄音、谷歌鍵盤等。
不過與華為、小米類似,即將推出的 Google Assistant with Bard(Bard 是類 ChatGPT 的生成式對話 AI)也是依賴於谷歌雲上的計算。事實上,在主流手機廠商中也只有谷歌和華為擁有自研的通用大模型,還有足夠規模的自有雲計算業務提供海量算力的支撐。
相比之下,vivo 的進展其實也不慢。

vivo 胡柏山,圖/ vivo
9 月舉辦的博鰲亞洲論壇上,vivo 執行副總裁、首席運營官胡柏山宣布了即將發布自研大模型,並且「帶有大模型的手機很快就會伴隨 vivo 新機來到大家面前」。
按照目前流出的信息,vivo 計劃在很快就要發布的 OriginOS 4 發布會上一齊發布自研大模型,更具體的還等待屆時揭曉。
不過根據英偉達透露,至少在 6 月初 vivo 面向自然語言理解任務的文本預訓練模型 3MP-Text,在中文語言理解測評基準 CLUE 上,1 億參數模型效果排名同規模第一,7 億參數模型排名總榜第十(不包括人類)。
榮耀確實慢了一拍。

榮耀趙明,圖/榮耀
事實上,榮耀 CEO 趙明在很早就強調了大模型端側部署的趨勢和重要性,6 月底的上海 MWC 上還指出,手機端側的個人大模型是未來探索方向,這也是榮耀的計劃。
但計劃是一方面,實際進展又是一方面,截止目前,榮耀仍未透露接入大模型的時間節點,沒有看到構建大模型相關的明確信息。不過我相信,等到下一代 MagicOS 發布的時候,榮耀至少也會公布接入大模型的時間節點。
三星和蘋果,好像沒有那麼急。
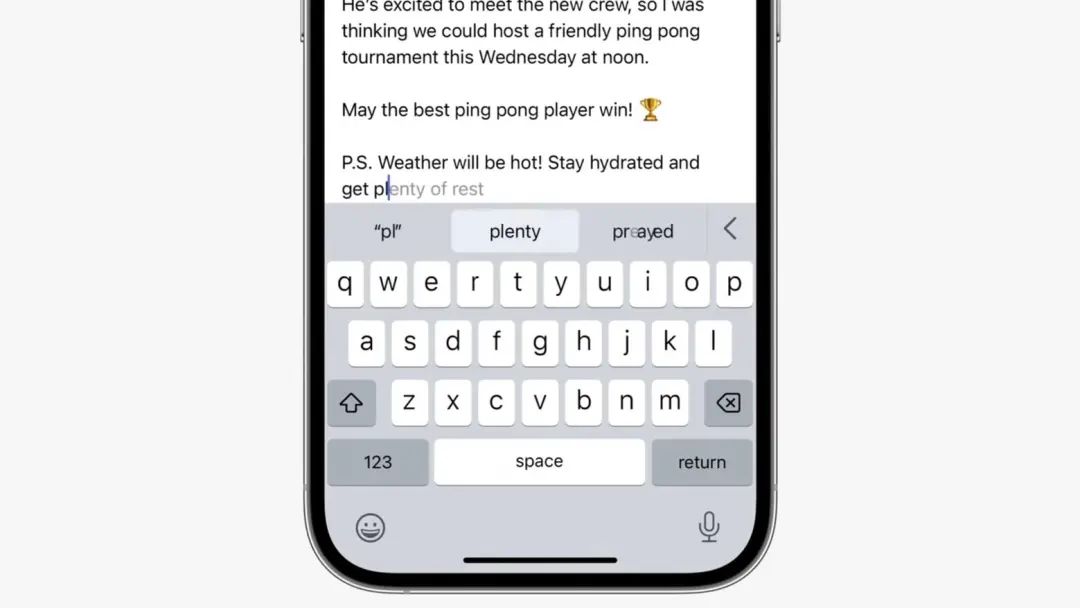
iOS 17 鍵盤輸入引入 Transformer 模型,圖/蘋果
三星其實在較早就宣布自研通用大模型,由三星研究院主導,並且根據媒體報道,三星一度將公司所有 GPU 算力資源都投入到大模型訓練之中,計劃在 8 月完成第一版大模型的開發。不過考慮到是研究院主導,距離在三星手機上實際應用,可能還有一段時間要走。
蘋果也顯得非常慎重,或者說保守。蘋果內部已經建立自研的大模型框架「Ajax」,也創建了類 ChatGPT 的生成式對話 AI。按照彭博社報道,大模型一度幾乎成為了蘋果公司每次開會都要提及的話題,幾個技術團隊甚至因為大模型項目合併在一起。
但在 iOS 17 上,蘋果只是在鍵盤輸入上引入 Transformer 模型運行,技術團隊想要先解決與大模型技術有關的潛在隱私問題。
潮水變了,但離上岸還有一段距離
今年 2 月,高通在一部沒有聯網的 Android 手機上使用了 Stable Diffusion 來生成 AI 圖像,整個生成時間不超過 15 秒,過程全部在手機上進行。高通、聯發科等移動芯片廠商很早就開始探索在手機本地運行大模型的未來。
到今天,手機大模型已經是一個無可爭議的趨勢。
但事實上手機大模型還面臨很多的疑問和挑戰,除了谷歌,所有已經或者即將落地大模型的手機廠商,幾乎都是在手機助手的基礎上進行接入,不僅實際應用場景有待驗證,目前的實現效果也存疑。
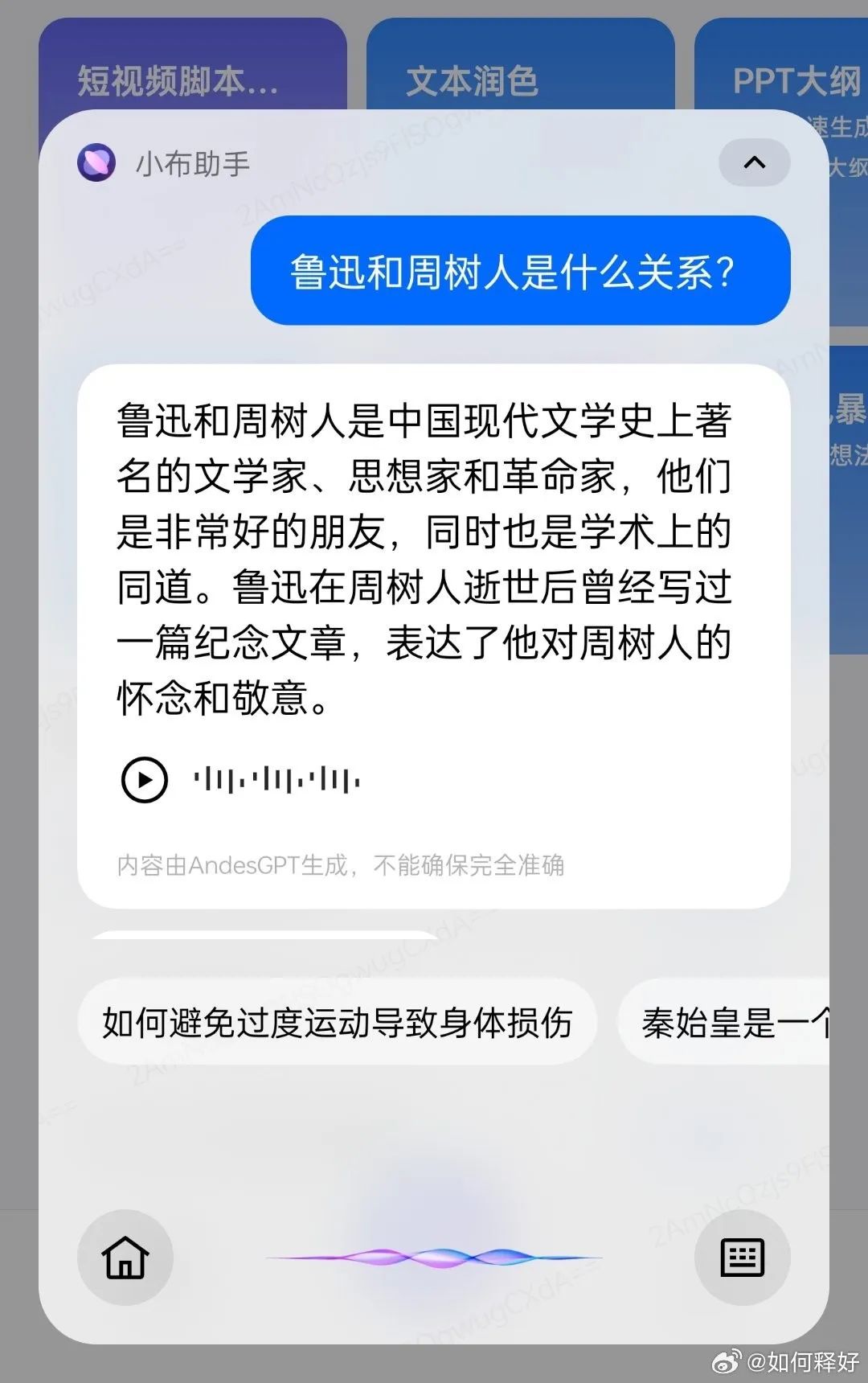
一個 OPPO 新小布的例子,圖/微博@如何釋好
另一方面,雖然在具體架構和實現路徑上存在不同看法,但業界的普遍共識是手機大模型將走向雲端+終端的混合架構,在終端本地運行勢在必行,手機廠商也都在放棄「通用」,縮減「大」模型的參數規模,壓到百億級、十億級和億級(大模型能力也會不同程度的影響)。
這不僅是因為深入手機使用場景后的隱私問題,算力的稀缺性和高成本也決定了,大模型必須利用起終端本身的算力,覆蓋大模型的一定算力成本,而不是由應用和平台背後的公司一力承擔。
坦率地說,手機大模型在目前這個階段,距離真正被大眾用戶應用可能還有很遠,最直接的問題就是,在保持大模型關鍵的「智能湧現」能力的同時,手機還需要面對處理器算力、功耗和面積的改進。