所有語言











分享
全球最強「開源版Gemini」誕生!全能多模態模型Emu2登熱榜,多項任務刷新SOTA
巴比特_智能边界380天前
原文來源:新智元

圖片來源:由無界 AI生成
最強的全能多模態模型來了!就在近日,智源研究院重磅發布了開源界的「Gemini」——Emu2,一口氣刷新多項SOTA。
過去的18個月里,我們見證了AI領域許多重要的時刻。
Llama、Alpaca等眾多開源模型競相發布,不僅與閉源模型的性能相媲美,同時為每個人提供了投身AI的機會:
- 2022年8月,Stable Diffusion問世,讓DALL·E的神秘光環不再遙不可及,每個人都能夠召喚出自己的数字達芬奇;
- 2023年2月,Meta的Llama及其後續的語言模型大軍,讓ChatGPT的獨角戲成為群星爭輝;
- 2023年12月6日,Google DeepMind揭開多模態巨星Gemini的面紗。
僅僅兩周后,智源研究院便發布了最新一代生成式多模態開源模型——Emu2。
很快,這一開源多模態領域的工作便引起了國際社區的廣泛關注,並登上了HN熱榜第三。
Emu2在HackerNews榜單上引發關注
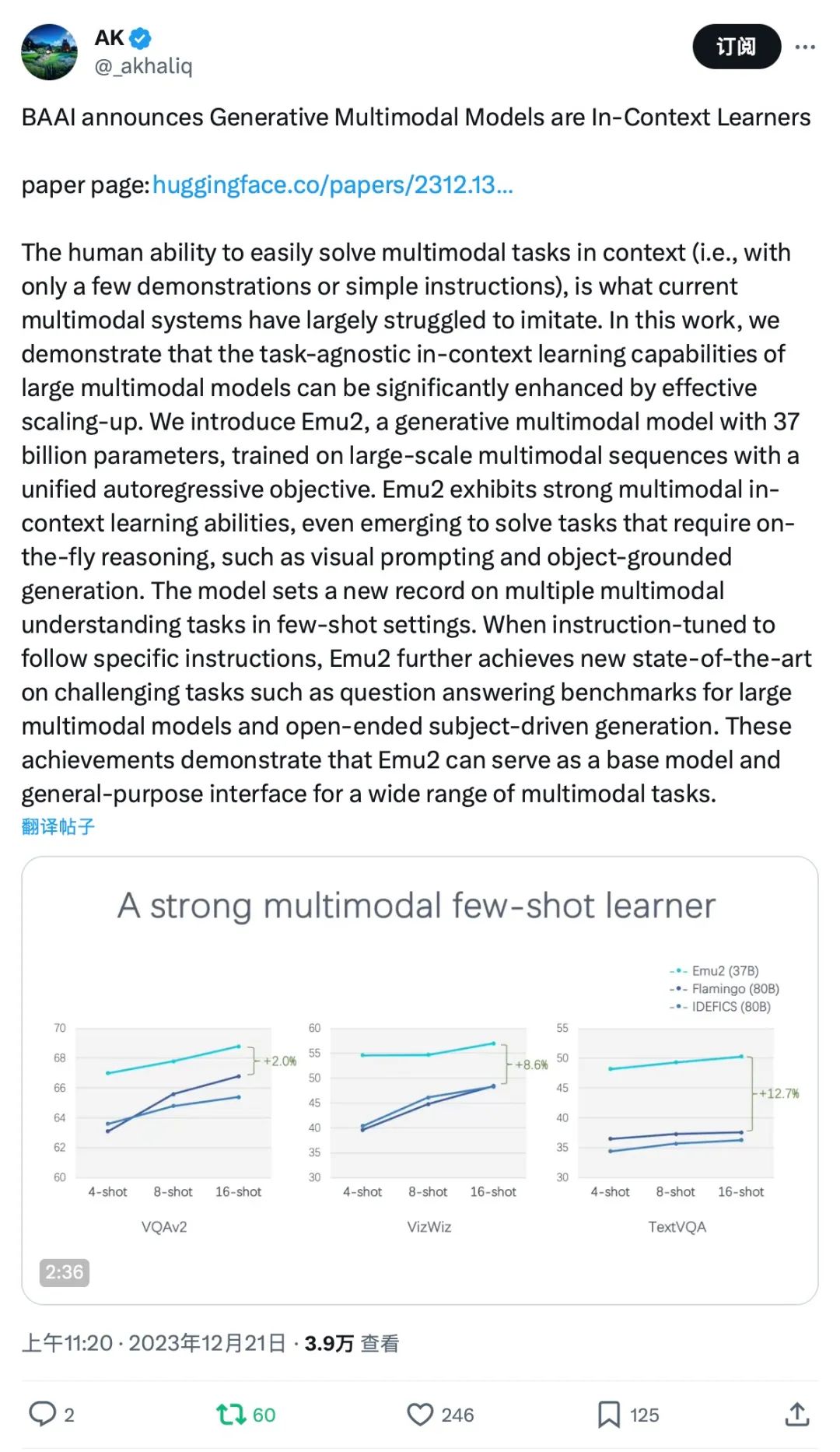
HuggingFace 大V AK轉發
據悉,這一模型即將推出更輕量的版本,讓技術玩家也在本地運行。
Emu2,通過大規模自回歸生成式多模態預訓練,顯著推動了多模態上下文學習能力的突破。
Emu2在少樣本多模態理解任務上大幅超越Flamingo-80B、IDEFICS-80B等主流多模態預訓練大模型,在包括VQAv2、OKVQA、MSVD、MM-Vet、TouchStone在內的多項少樣本理解、視覺問答、主體驅動圖像生成等任務上取得最優性能。
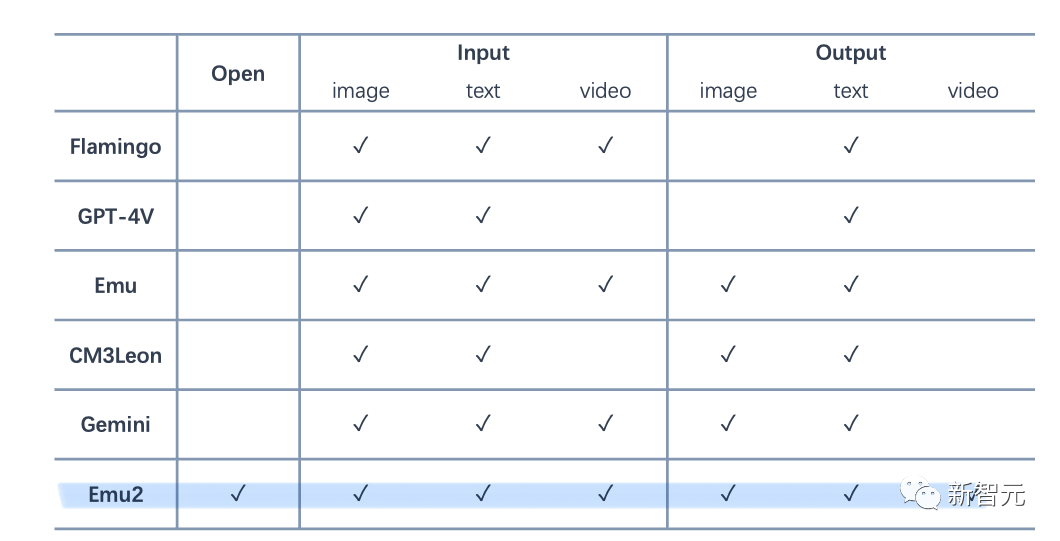
Emu2模型和Flamingo、GPT-4V、Gemini等模型能力對比情況一覽
「開源版Gemini」來襲
相較2023年7月發布的第一代「多模態to多模態」Emu模型,Emu2使用了更簡單的建模框架,訓練了從編碼器語義空間重建圖像的解碼器、並把模型規模化到37B參數實現模型能力和通用性上的突破。
與此同時,依然採用大量圖、文、視頻的序列,建立基於統一自回歸建模的多模態預訓練框架,將圖像、視頻等模態的token序列直接和文本token序列交錯在一起輸入到模型中訓練。
值得一提的是,Emu2是目前最大的開源生成式多模態模型,基於Emu2微調的Emu2-Chat和Emu2-Gen模型分別是目前開源的性能最強的視覺理解模型和能力最廣的視覺生成模型:
- Emu2-Chat可以精準理解圖文指令,實現更好的信息感知、意圖理解和決策規劃。
- Emu2-Gen可以接受圖像、文本、位置交錯的序列作為輸入,實現靈活、可控、高質量的圖像和視頻生成。
現在,Emu2的模型、代碼均已開源,並提供Demo試用。

項目:https://baaivision.github.io/emu2/
模型:https://huggingface.co/BAAI/Emu2
代碼:https://github.com/baaivision/Emu/tree/main/Emu2
Demo:https://huggingface.co/spaces/BAAI/Emu2
論文:https://arxiv.org/abs/2312.13286
多項性能刷新SOTA
通過對多模態理解和生成能力的定量評測,Emu2在包括少樣本理解、視覺問答、主體驅動圖像生成在內的多個任務上取得最優性能。
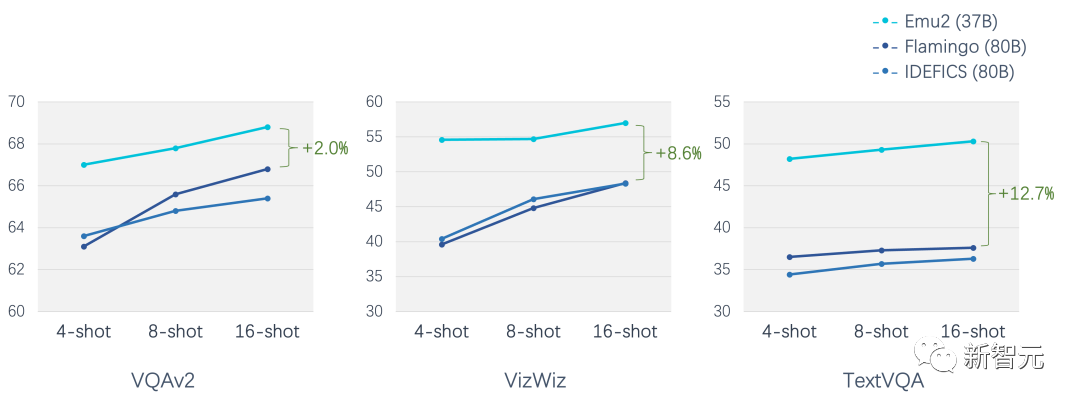
在少樣本評測上,Emu2在各個場景下顯著超過Flamingo-80B,例如在16-shot TextVQA上較Flamingo-80B 超過12.7個點。
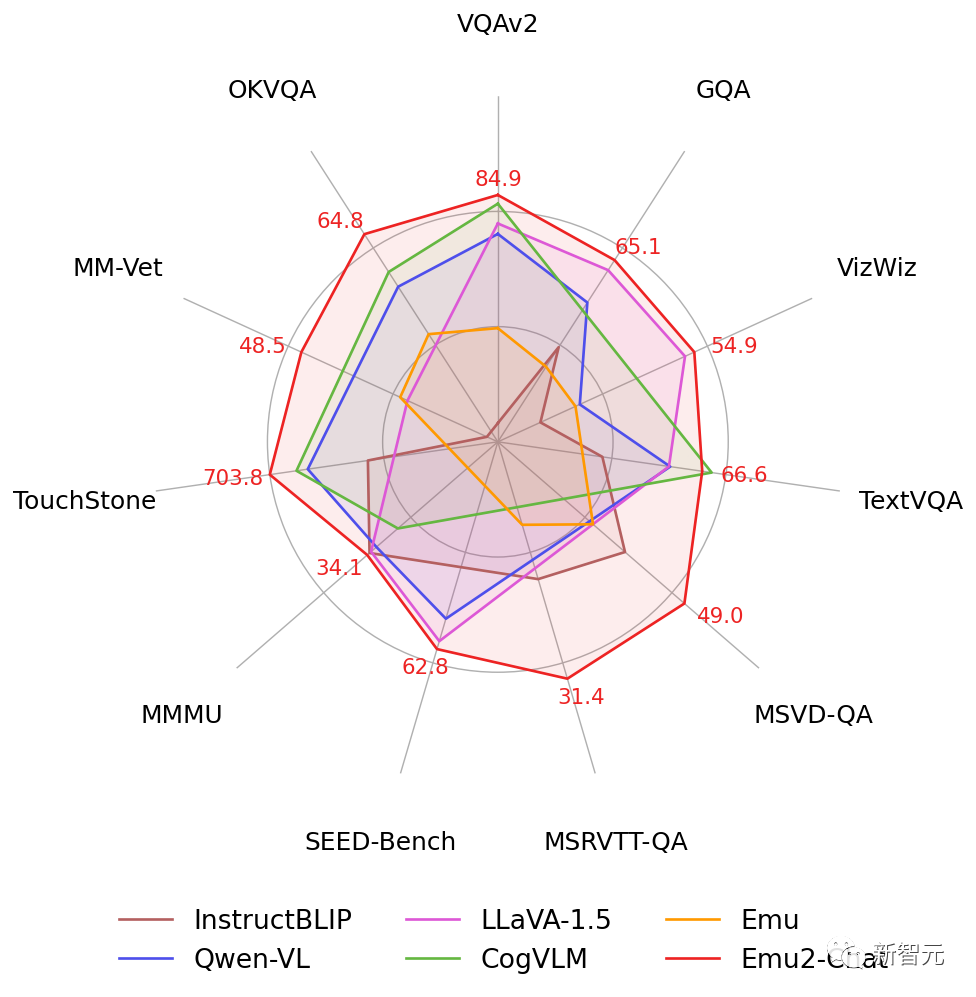
經過指令微調的Emu2可以對圖像和視頻輸入進行自由問答,以統一模型在VQAv2、OKVQA、MSVD、MM-Vet、TouchStone等十餘個圖像和視頻問答評測集上取得最優性能。
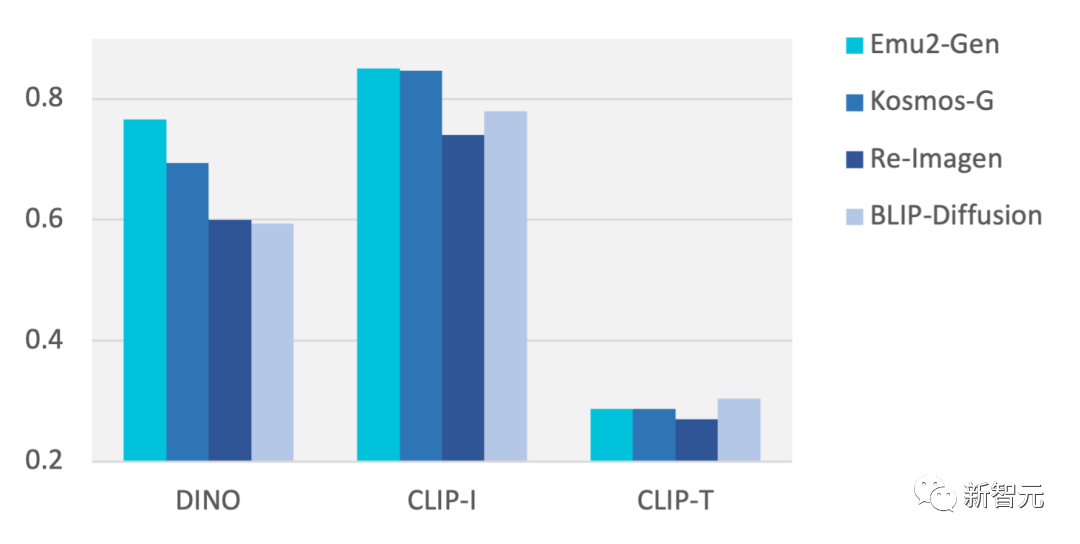
在零樣本的DreamBench主體驅動圖像生成測試上,較此前方法取得顯著提升,例如比Salesforce的BLIP-Diffusion的CLIP-I分數高7.1%, 比微軟的Kosmos-G的DINO分數高7.2%。
多模態上下文學習
生成式預訓練完成后,Emu2具備全面且強大的多模態上下文學習能力。基於幾個例子,模型可以照貓畫虎的完成對應理解和生成任務。
例如在上下文中描述圖像、在上下文中理解視覺提示(覆蓋圖像上的紅圈)、在上下文中生成類似風格的圖像、在上下文中生成對應主體的圖像等。

強大的多模態理解
經過對話數據指令微調的Emu2-Chat,可以精準理解圖文指令、更好的完成多模態理解任務。
例如推理圖像中的要素、讀指示牌提供引導、按要求提取和估計指定屬性、回答簡單的專業學科問題等。




基於任意prompt序列的圖像生成
經過高質量圖像微調的Emu2-Gen,可以接受圖像、文本、位置交錯的序列作為輸入,生成對應的高質量圖像,這樣的靈活性帶來高可控性。
例如生成指定位置、指定主體的熊和向日葵:

生成指定位置、指定主體、指定風格的寵物狗和小鴯鶓的合影圖像:

更多的根據圖文序列生成的例子:
基於任意prompt序列的視頻生成
進一步的,Emu2支持基於任意prompt序列的視頻生成。
基於文本、圖文交錯、圖文位置交錯的序列,可以生成對應的高質量視頻。

統一的生成式預訓練
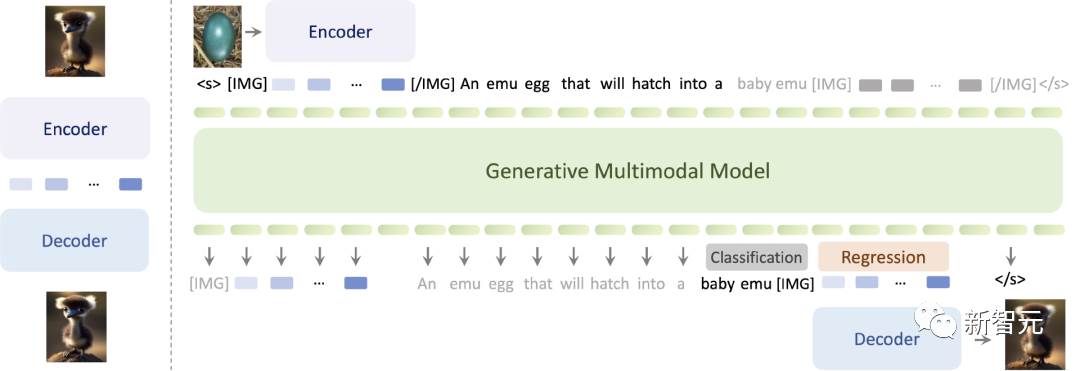
Emu2的訓練方法是在多模態序列中進行生成式預訓練。
使用統一的自回歸建模方式,根據當前已生成的 token 預測下一個視覺或文本token。
相比Emu1,Emu2使用了更簡單的建模框架、訓練了更好的從特徵重建原圖的解碼器、並把模型規模化到37B參數。
參考資料:
https://baaivision.github.io/emu2/