所有語言











分享
AI佟湘玉 PK AI呂秀才!人大和北郵聯合發布的評測基準,能分辨大模型角色扮演哪家強
巴比特_品玩374天前
原文來源:品玩
作者:呂可

圖片來源:由無界 AI生成
Role-Playing Conversational Agents(RPCA)是一類對話代理,它們被設計成能夠模仿特定角色或人物進行對話。這些角色通常來自於現有的文學作品、電影、卡通、遊戲等,具有特定的知識、行為和回應風格。RPCA的目標是與用戶進行沉浸式的互動,提供情感價值而非僅僅是信息或生產力。
與傳統的聊天機器人不同,RPCA更注重於角色扮演和情感交流。它們能夠根據用戶的輸入,以特定角色的身份進行回應,從而創造出一種彷彿與真實人物對話的體驗。這種類型的對話代理在娛樂、教育、心理輔導等領域有着廣泛的應用前景,因為它們能夠提供更加個性化和情感化的交互體驗。
RPCA的挑戰在於如何準確地模擬角色的知識、行為和風格,同時保持對話的連貫性和吸引力。為了評估這些代理的性能,來自中國人民大學高瓴人工智能學院的三位研究者聯手北京郵電大學人工智能學院共同推出了一個名為CharacterEval的中文基準測試。並輔以一個量身定製的高質量數據集。
該數據集由 1785 個多回合角色扮演對話組成,包含 23020 個例子和 77 個來自中國小說和劇本的角色。比如《武林外傳》中的佟湘玉和呂秀才。CharacterEval 可以直接讓不同的大模型生成這兩個角色進行對話,並根據基準測試的標準來給出相應的能力評分。

作為基準測試,CharacterEval 採用多維度評估方式,包括對話能力、角色一致性、角色扮演模式以及個性測試四個維度,每個維度還有不同的指標,一共十三個具體指標。
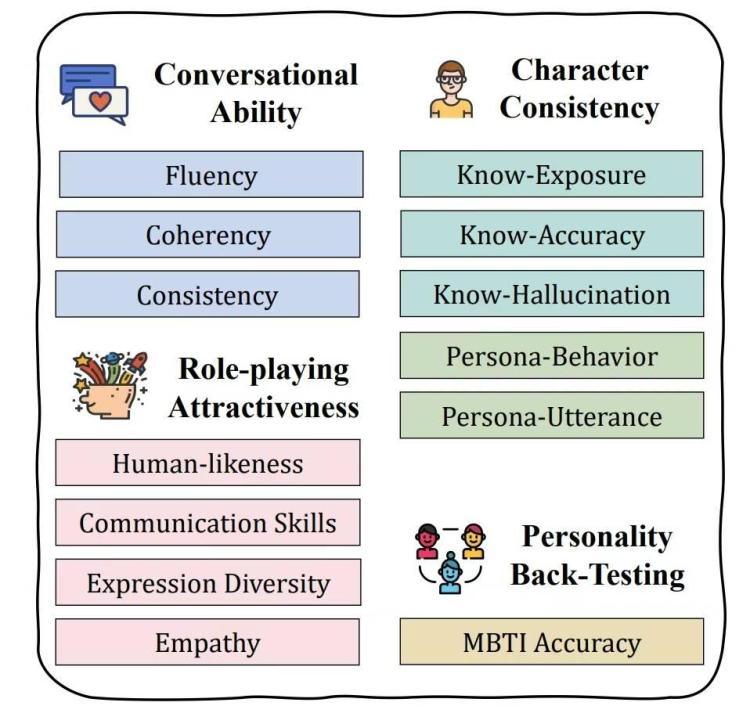
對話能力(Conversational Ability)
- 流暢性(Fluency):衡量響應的語法正確性和可讀性。
- 連貫性(Coherency):評估響應與對話上下文的相關性。
- 一致性(Consistency):檢查RPCA在對話中是否保持一致性,避免自相矛盾。
角色一致性(Character Consistency)
- 知識曝光(Know-Exposure, KE):評估RPCA在響應中提供的信息量。
- 知識準確性(Know-Accuracy, KA):衡量RPCA基於角色知識生成響應的準確性。
- 知識幻覺(Know-Hallucination, KH):評估RPCA在缺乏知識時是否會產生幻覺。
- 角色行為(Persona-Behavior, PB):評估RPCA的行為描述是否符合角色特徵。
- 角色台詞(Persona-Utterance, PU):檢查RPCA的說話風格是否與角色相符。
角色扮演吸引力(Role-playing Attractiveness)
- 人類相似度(Human-Likeness, HL):評估RPCA的響應是否具有人類特徵。
- 溝通技巧(Communication Skills, CS):衡量RPCA在對話中的溝通能力。
- 表達多樣性(Expression Diversity, ED):檢查RPCA在對話中是否展現出多樣性。
- 同理心(Empathy, Emp):評估RPCA在對話中表達同理心的能力。
個性測試(Personality Back-Testing)
- MBTI準確性(MBTI Accuracy):使用Myers-Briggs Type Indicator(MBTI)個性類型作為參考,評估RPCA在個性測試中的準確性。
研究團隊還推出了一個名為 CharacterRM 的獎勵模型,用於對主觀指標的評估。CharacterRM 通過與人類判斷的相關性來評估RPCA在主觀指標上的表現。而根據實驗結果,其性能優於GPT-4,當人這隻能說是角色扮演這方面。
研究團隊用了幾個比較常用的 AI 大模型進行了測試,其中包括常見的 ChatGLM3-6B、GPT-4、minimax、Baichuan2-13B等,並根據他們的表現給出了評分。

CharacterEval 的誕生,填補了角色扮演對話代理(RPCAs)領域缺乏全面評估基準的空白。而他的發布也有助於該領域的發展以及以及用戶體驗提升。
研究團隊先已經放出了CharacterEval 相關數據集、論文等信息,感興趣的人可以通過GitHub訪問。此外,該測試的代碼也將會在不久后更新在其 GitHub頁面中。
Arxiv地址:https://arxiv.org/abs/2401.01275