所有語言











分享
難倒大模型的《西遊記》問題,“個人 AI 計算機”或是一種解決方案
巴比特_智能边界361天前
來源:量子位
原文標題:《西遊記》把大模型給難倒了

問:《西遊記》里,總共提到過孫悟空這隻猴多少次?
咱問了問ChatGPT,ChatGPT連連搖頭,說《西遊記》篇幅太長,它統計不出來。

不死心,又把這個問題問向了Claude。
Claude頻頻擺手,說因為不具備完整閱讀和分析長篇文學作品的能力,無法統計。

事實上,不僅僅是ChatGPT和Claude答不上來,市面上的大模型幾乎都無法(準確)回答這個問題。
除了《西遊記》作為章回體小說,本身篇幅太長外,“孫悟空”還在書里有各種各樣的代詞指代,比如大聖、孫行者、美猴王、心猿、甚至是你/我/他……
於是,大模型們在這道題面前只能束手就擒。
然而,對於任何一名人類傳統程序員來說,這壓根不算一個難題,只要用編程、邏輯推理去解決,確定的答案很容易擺在眼前。
但如果非要把解決方式切回“大模型”模式,幻覺和精度,就是最直接的問題。
一家國內的AI創業公司給出了它們的答案:選擇做個人AI計算機,用它補齊大模型和AI應用間缺失的那一環。
嘗試統一神經網路和高級編程語言
這家公司名為KMind,創始人吳翰清,他更為業內人士所熟知的身份是阿里雲的道哥/小黑,是前阿里雲首席安全科學家、P10級研究員。
去年5月離職阿里后,他和阿里前同事陳冬白攜手創業,又邀請來西湖大學AutoLab(自主智能實驗室)負責人於開丞擔任首席科學家,KMind的核心團隊就這麼搭建起來了。

在去年7月,KMind曾推出過一款面向C端用戶的AIGC效率工具。
7月份推出,不到3個月時間,這款AIGC效率工具已經擁有了10萬用戶。
但困境伴隨而生:用戶流失率非常高。
吳翰清最終思考出的結論是,沒有人喜歡一個滿嘴謊話、不懂裝懂的人,尤其是那些從未接觸過AI、不知AI為何物的用戶,第一次用上AIGC效率工具,往往會把對方當成一個在和自己交流的真實的人。
這樣就會導致用戶一旦發現AI不靠譜,就會氣到當場棄用。
“目前LLM在解決幻覺問題上主要還是靠對齊,但這類技術治標不治本。要想徹底解決這個問題,我認為還得從LLM之外尋求答案。”
當然,“幻覺”僅僅是大模型存在的最大問題之一,另一個問題,也是大模型無法準確回答西遊記里有多少孫悟空的另一個原因,是書中指代孫悟空的名詞、代詞太多,大模型目前的推理能力還無法進行精準判斷。
“對於所有的程序員來說,邏輯推理都不是一個問題,1+1必然等於2。”正如吳翰清所說,“但是對於所有做神經網絡的人來說,如何讓神經網絡自動生成1+1=2這個答案並不容易。”
基於這一點,KMind團隊的思考逐漸清晰:
不如試試,統一神經網絡和高級編程語言。
神經網絡主要提供泛化能力,高級編程語言則提供邏輯推理能力和精準控制能力,兩者連接起來,雙管齊下,就能解決大部分問題。
提出“個人AI計算機”
沿着這個思路提出一種具體的解決辦法,就是KMind所提出的造一個擁有新型計算機操作系統kOS的“個人AI計算機”。
先簡單了解一下,什麼是個人AI計算機。
一起來看個人AI計算機長啥樣:
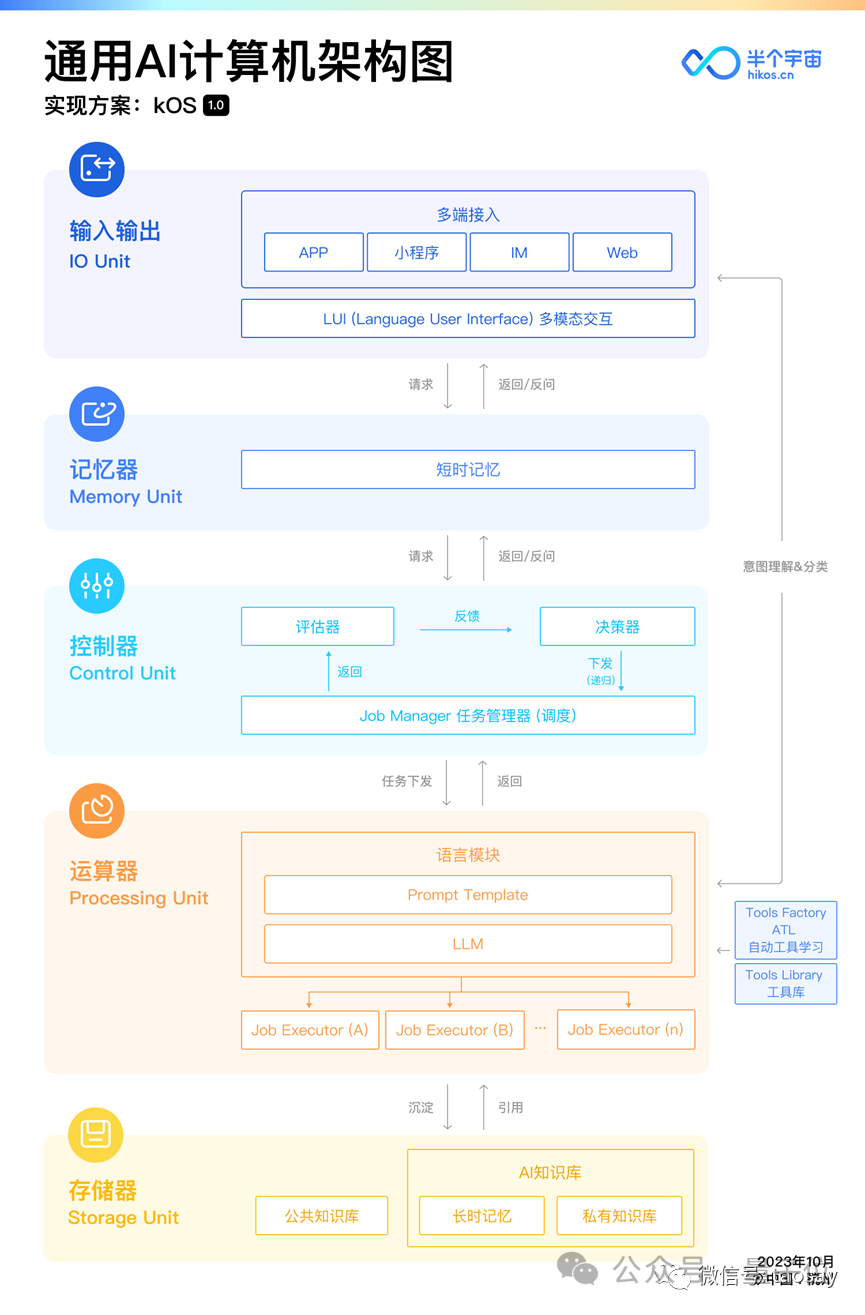
在這個架構中,依次有輸入輸出、記憶器、控制器、運算器和存儲器。
其中,控制器相當於整個系統的“大腦”,是真正理解用戶意圖、並對複雜任務進行拆解,以及調度不同執行單元來完成用戶任務的部分。
在這個部分里,為了模擬人的思考過程,又存在評估器和決策器。
與此同時,控制器還會不斷和外界進行交互,通過多輪對話等方式,需要用戶不斷提供新的信息,形成反饋,然後整個系統不斷進行迭代、循環。

而個人AI計算機作為kOS的實現目標而存在,被稱為計算機,是因為它符合馮·諾伊曼架構,從設計之初,就符合信息論、控制論和系統論的結合。
- 首先,從系統論角度來說,kOS在追尋對神經網絡和高級編程語言兩者的統一;
- 其次,公布出的架構里,kOS有模擬人類思考的過程,符合控制論的設計思想;
- 再者,kOS滿足信息論則體現在架構能夠通過數據脫水和數據浸泡產生結構化數據。
這裏多提兩句,數據脫水和浸泡也是KMind提出的新概念。
繼續用《西遊記》來舉例子。數據脫水,就是把整本書先進行數據挖掘,生成結構化數據——這個過程本身就調用了多次計算,且計算可能來自於小模型,也可能來自於大模型。
產生結構化數據后,就可以根據用戶的邏輯或需求,在任意尺度上對其進行精確控制,隨意替換掉需要部分的“零件”。
脫水后的結構化數據去除掉了冗餘信息,最終以一個跟信息熵相關的指標,來衡量AI操作數據的精確程度。
修改后的結構化數據會被評估“是否對原有數據造成了破壞”,如被破壞,則在AI精度上繼續迭代修改。最後將數據還原,或生成為用戶可讀的數據形態。

能解決什麼問題?
對精確部分進行修改,就像AI繪畫過程中,利用ControlNet插件精確控制手部區域進行修改,直到滿意,再也不用整體推翻重新再來了。
如此這般,大模型的幻覺和精度問題,至少能在現在得到緩解。
這也是個人AI計算機為自己賦予的使命之一。
“之一”意味着它的作用並不全在此。
個人AI計算機被視為一個全新概念,是因為它的目標是把個人計算機“小型化、普惠化,讓每個人都用得起”。
這與現在的個人計算機迥乎不同:在此之前,互聯網把一個個個人計算機連接在一起,全球的数字化信息由此可以在互聯網裡高速流動。
但信息彙集,產生了超級節點,數據也漸漸被互聯網巨頭垄斷。
在KMind團隊看來,這十分不合理,用戶貢獻了數據,但數據垄斷后的收益都是互聯網寡頭的;數據垄斷還會進一步帶來互聯網的割裂,不僅降低用戶體驗,還違背了互聯網互聯、自由的屬性。
因此,個人AI計算機一方面想解決大模型不能解決之痛,另一方面,還希望能解決由於信息聚集在Google這樣的超級節點導致的數據垄斷、互聯網割裂等問題。
開啟這個目標的第一步,KMind就表示自己的商業模式不會是通過廣告業務實現。
如果這個公司的商業模式是廣告,很難避免自己不作惡。
同時,團隊也明確表示不會拿用戶的數據訓練自己的模型,也不會將屬於每個用戶的數據綜合后形成一個通識AI。
在團隊規劃中,KMind的商業模式是這樣的:
KMind提供算力,程序員用戶提供算法,用戶提供數據,且數據永遠歸用戶擁有。
吳翰清強調,這是一個良性的生態結構,他同時也強調,個人AI計算機里的推薦和檢索算法都會被開源,並由一個開源社區來維護。
“如果有一天半個宇宙居然想要把這些閉源掉,那我也號召所有半個宇宙的居民來推翻它,因為從那一天可能就是它作惡的開始,它又開始從嘗試不垄斷數據走向了數據垄斷。”
One More Thing
現在,KMind已推出了由kOS驅動的個人智能助理“星伴”。
每個用戶和星伴將是伴生關係,按照用戶的意圖,星伴會為自動為用戶工作,或陪用戶聊天。
和其他可調用AI不同,星伴是可編程的,具備成長性,它所經歷的個性化知識、經驗、記憶、性格會被保存在一個叫“星魂”的地方,最終形成屬於每個人的数字資產。
一旦經過允許,你可以調用其他人星伴里的知識,最終形成一個龐大的AI社區。
也因為星伴的存在,人的在線時間不再受制於睡眠和休息,AI會幫你時刻在線,只要提供了數據,AI就能開放式的回答所有問題,永不停歇的服務、溝通、協同。
想想有點激動,感覺有了星伴,本打工人的摸魚時間一定能更多了吧……