所有語言











分享
清華、小米、華為、 vivo、理想等多機構聯合綜述,首提個人LLM智能體、劃分5級智能水平
巴比特_智能边界355天前
來源:機器之心

圖片來源:由無界 AI生成
嘿 Siri、你好小娜、小愛同學、小藝小藝、OK Google、小布小布……
想必這些喚醒詞中至少有一個曾被你的嘴發出並成功呼喚出了一個能給你導航、講笑話、添加日程、設置鬧鐘、撥打電話的智能個人助理(IPA)。可以說 IPA 已經成了現代智能手機不可或缺的標配,近期的一篇綜述論文更是認為「個人 LLM 智能體會成為 AI 時代個人計算的主要軟件範式」。
這篇個人 LLM 智能體綜述論文來自國內多所高校和企業研究所,包括清華大學、小米、華為、歡太、vivo、雲米、理想汽車、北京郵電大學、蘇州大學。
文中不僅梳理了個人 LLM 智能體所需的能力、效率和安全問題,還收集並整理了領域專家的見解,另外還開創性地提出了個人 LLM 智能體的 5 級智能水平分級法。該團隊也在 GitHub 上創建了一個文獻庫,發布了相關文獻,同時也可供 IPA 社區共同維護,更新最新研發進展。

- 論文地址:https://arxiv.org/abs/2401.05459
- 文獻庫:https://github.com/MobileLLM/Personal_LLM_Agents_Survey
- 論文標題:Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security
機器之心整理了這篇綜述論文的內容主幹,以饗讀者。
科幻描繪了很多亮眼的智能個人助理(IPA),即可以增強個人能力、完成複雜任務甚至滿足情感需求的軟件智能體。這些智能體可以代表大多數人對人工智能(AI)的幻想。
隨着智能手機、智能家居設備、電動車等個人設備的廣泛普及和機器學習技術的進步,這種幻想正在逐漸變成現實。現在,很多移動設備都內嵌了 IPA 軟件,比如 Siri、Google Assistant、Alexa 等。這些智能體與用戶密切相關,可以讀取用戶數據和傳感器數據、控制各種個人設備、使用與個人賬戶關聯的個性化服務。
但是,當今的智能個人助理的靈活性和可擴展性都還有限。它們的智能水平還遠遠不夠,在理解用戶意圖、推理和任務執行等方面尤其明顯。現如今大多數智能個人助理都只能執行受限範圍內的任務(比如內置應用的簡單功能)。一旦用戶的任務請求超出了這些範圍,智能體就無法準確理解和執行這些動作。
要改變這種情況,就必須顯著提升智能體的能力,使其支持範圍更廣、更靈活的任務。但是,當前的 IPA 產品很難支持大範圍的任務。當今大多數 IPA 都需要遵循特定的預定義規則,比如開發者定義的規則或用戶演示的步驟。因此,除了定義任務執行的觸發器和步驟之外,開發者或用戶還必須明確指定他們希望支持哪些功能。本質上講,這種方法會限制這些應用被用於更廣泛的任務,因為支持更多任務需要大量時間和勞動力成本。
某些方法在嘗試通過監督學習或強化學習實現自動化學習,從而支持更多任務。但是,這些方法也需要大量人工演示和 / 或定義獎勵函數的工作。
近些年出現的大型語言模型(LLM)為 IPA 的開發帶來了全新的機會,其展現出了解決智能個人助理可擴展性問題的潛力。
相比於傳統方法,ChatGPT 和 Claude 等大型語言模型已經展現出了指令遵從、常識推理和零樣本泛化等特有能力。這些能力的實現基於在大規模語料庫(超過 1.4 萬億詞)上進行無監督學習以及後續通過人類反饋進行微調。利用這些能力,研究者已經成功採用大型語言模型來驅動自動智能體(即 LLM 智能體),其目標是通過自動進行規劃和使用搜索引擎、代碼解釋器和第三方 API 等工具來解決複雜問題。
IPA 是一類特殊的智能體,有望通過 LLM 實現變革,畢竟 LLM 具備顯著增強的可擴展性、能力和有用性。我們可以把 LLM 驅動的智能個人助理稱為個人 LLM 智能體(Personal LLM Agents)。
相比於普通 LLM 智能體,個人 LLM 智能體會更深度地參与個人數據和移動設備,並且它們也有更明確的設計目的:輔助人類而非取代人類。
具體而言,輔助用戶的主要方式是減少他們日常生活中重複、乏味、低價值的勞動,讓用戶能專註於更有趣、更有價值的事情,從而提高工作和生活的效率和質量。個人 LLM 智能體可基於現有軟件棧(例如移動應用、網站等)構建,同時還能通過無處不在的智能自動化能力帶來令人耳目一新的用戶體驗。
因此,該團隊預計個人 LLM 智能體會成為 AI 時代個人計算的主要軟件範式,如圖 1 所示。
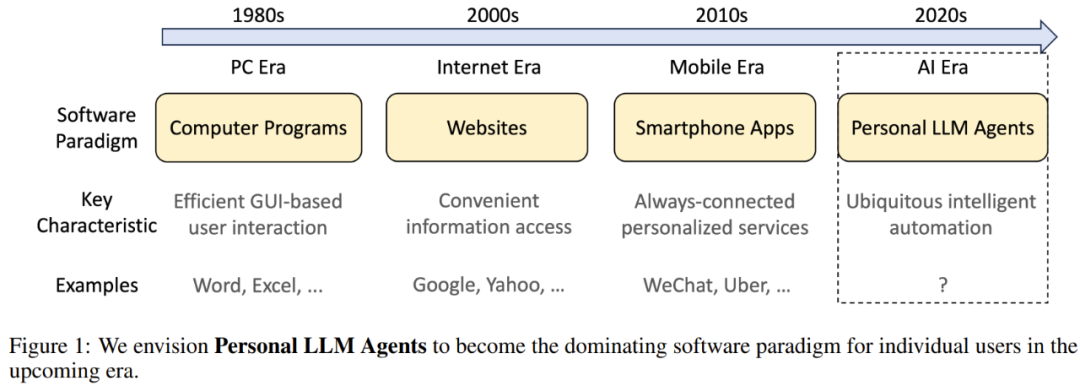
儘管個人 LLM 智能體未來潛力巨大,但相關研究仍處於起步階段,仍有許多錯綜複雜的問題和挑戰有待解決。
這篇綜述論文率先討論了實現個人 LLM 智能體方面的路線圖、設計選擇、主要挑戰和可能解決方案。
具體來說,這篇論文主要關注的是個人 LLM 智能體中與「個人」相關的部分,其中包括分析和利用用戶個人數據、使用個人資源、在個人設備上部署以及提供個性化服務。將 LLM 的通用語言能力簡單直接地整合進 IPA 不在本文的討論範圍內。
首先,該團隊對個人 LLM 智能體領域的專家做了一番調研。他們邀請了業內領先公司、研發用在個人設備上的 IPA 和 / 或 LLM 的 25 位首席架構師、管理者和 / 或資深工程師 / 研究者他們讓這些專家談了談將 LLM 整合進面向消費者的產品的機遇和挑戰。基於對這些專家意見的理解和分析,該團隊總結了一套簡單又普適的個人 LLM 智能體架構,其中最重要的部分是對個人數據(用戶背景信息、環境狀態、行為歷史記錄、個人特徵)和個人資源(移動應用、傳感器、智能家居設備)的智能管理和使用。
另外,管理和使用這些個人事項的能力不同於個人 LLM 智能體的智能水平。該團隊從自動駕駛的 1-5 級智能分級獲得靈感,提出了個人 LLM 智能體的 5 個智能等級。
另外,該團隊的這項研究還突出強調了實現這類個人 LLM 智能體的一些主要技術挑戰;他們將這些挑戰分成了三類:基本能力、效率、安全和隱私。他們也詳細解釋了這三方面的挑戰並全面總結了可能的解決方案。具體來說,對於每個技術方面,他們會簡要解釋其與個人 LLM 智能體的相關性以及對個人 LLM 智能體的重要性,然後再具體討論其中的主要研究問題。
這篇論文的主要內容和貢獻可以總結如下:
- 總結了產業界和學術界中智能個人助理的當前現狀,同時分析了它們的主要局限和 LLM 時代的未來趨勢。
- 收集了 LLM 和個人智能體領域資深專家的見解、提出了一個普適的系統架構並定義了個人 LLM 智能體的智能水平。
- 總結了個人 LLM 智能體三個重要技術方面的文獻,包括基本能力、效率、安全和隱私。
智能個人助理簡史
智能個人助理髮展時間線
智能個人助理(IPA)的發展史已經很長。圖 2 給出了 IPA 歷史的大致時間線。其發展過程可以分為四個階段,圖中採用了不同的顏色標記。
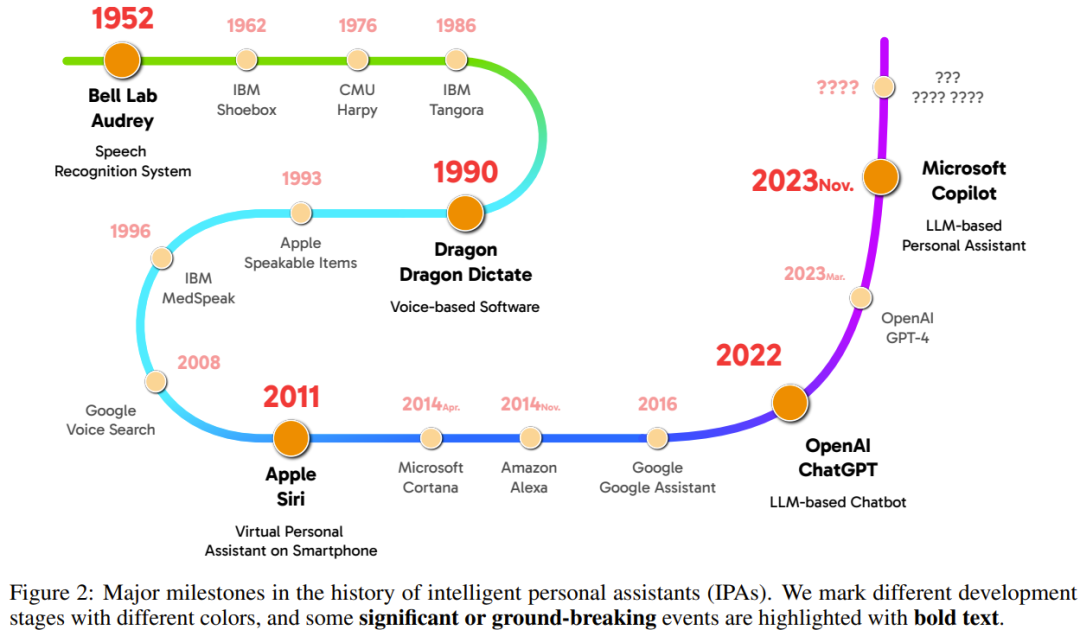
第 1 階段是從 1950 年代到 1980 年代末,這一時期的重點是開發語音識別技術。
第 2 階段是從 1990 年代到 2000 年代末,此時語音識別已經開始被整合進一些軟件實現一些高級功能。
第 3 階段始於 2010 年代初。這時候,智能手機和個人計算機等移動設備上開始出現總是開啟的虛擬助手服務。2011 年,Siri 被集成到了 iPhone 4S 中,也被廣泛認為是首個安裝在現代智能手機上的智能個人助理。
第 4 階段則是始於近期 ——LLM 開始贏得世界矚目。現在已經出現了很多基於 LLM 的智能聊天機器人(如 ChatGPT),還有一些安裝在個人設備上的 LLM 驅動的 IPA 軟件(如 Copilot)。
從技術角度看智能個人助理髮展史
在觀察智能個人助理時,我們可以選擇很多不同視角,這裏作者選擇重點關注其最重要的一項能力,即任務自動化的能力(遵從指令並完成任務)。下面將介紹四種用於在 IPA 中實現智能任務自動化的主要技術。
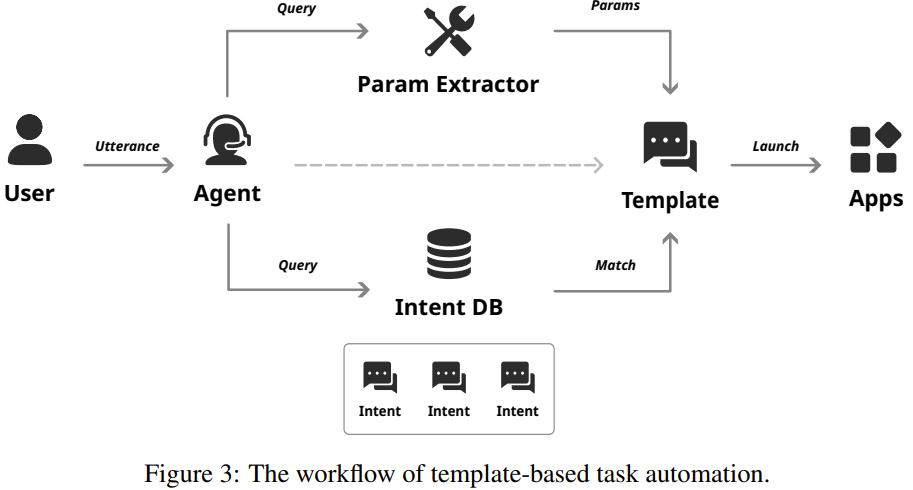
基於模板的編程:大多數 IPA 商業產品都是通過基於模板的編程來實現任務自動化。這種方法是把要自動化的功能預定義成模板;通常來說,模板中會包含任務描述、相關動作、要匹配的示例查詢、需要填充的可用參數等。用戶給出指令后,智能體首先會將指令映射到最相關的模板,然後再按照預定義的步驟完成任務。其工作流程如圖 3 所示。
監督學習方法:監督學習是一種實現任務自動化的直接方法,其做法是基於任務輸入和當前狀態預測後續的動作和狀態。這方面的主要研究問題包括如何學習軟件 GUI 的表徵以及如何訓練交互模型。
強化學習方法:不同於需要大量訓練樣本的基於監督學習的任務自動化方法,基於強化學習(RL)的方法允許智能體通過與目標接口持續交互來獲得任務自動化的能力。在交互過程中,智能體會獲得指示任務完成進度的獎勵反饋,並逐漸學習如何通過最大化獎勵回報來自動化任務。
對基礎模型的早期使用:近年來,以大型語言模型(LLM)為代表的預訓練大型基礎模型發展迅速,為個人助理帶來了新機會。
個人 LLM 智能體:定義和見解
我們正在見證基於 LLM 的智能個人助理的巨大潛力,也能看到學術界和產業界對這一技術的廣泛興趣。該團隊通過這個研究項目率先系統性地討論了與這一方向相關的機會、挑戰和技術。
他們首先對個人 LLM 智能體(Personal LLM Agents)進行了定義:一類深度整合了個人數據、個人設備和個人服務的基於 LLM 的特殊智能體。
個人 LLM 智能體的主要目標是輔助終端用戶,幫助他們減少重複性和繁瑣的工作,讓他們能更關注更有趣和更重要的事務。
按照這一定義,通用的自動化方法(prompt 設計、規劃、自我反思等)類似於普通的基於 LLM 的智能體。這裏重點關注的是與「個人」相關的部分,比如個人數據管理、對智能手機應用的使用情況以及部署到資源有限的個人設備等等。
該團隊預計:在 LLM 時代,個人 LLM 智能體將成為個人設備的一個主要軟件範式。但是,個人 LLM 智能體的軟件棧和生態系統仍處於非常早期的階段。與系統設計和實現相關的許多重要問題尚不明晰。
因此,為了了解這些問題,該團隊做了一番調研,收集並整理了 25 位該領域專家的見解。這 25 位專家是來自 8 家研發 IPA 相關產品的領先公司的首席架構師、管理者或高級工程師 / 研究者。他們分享了對個人 LLM 智能體的看法,並解答了一些從應用場景到部署挑戰等方面的常見問題。基於這些討論和收集到的答案,該團隊將這些見解分成了三個方面,包括個人 LLM 智能體的關鍵組件、智能水平分級、有關常見問題的專家意見。
關鍵組件
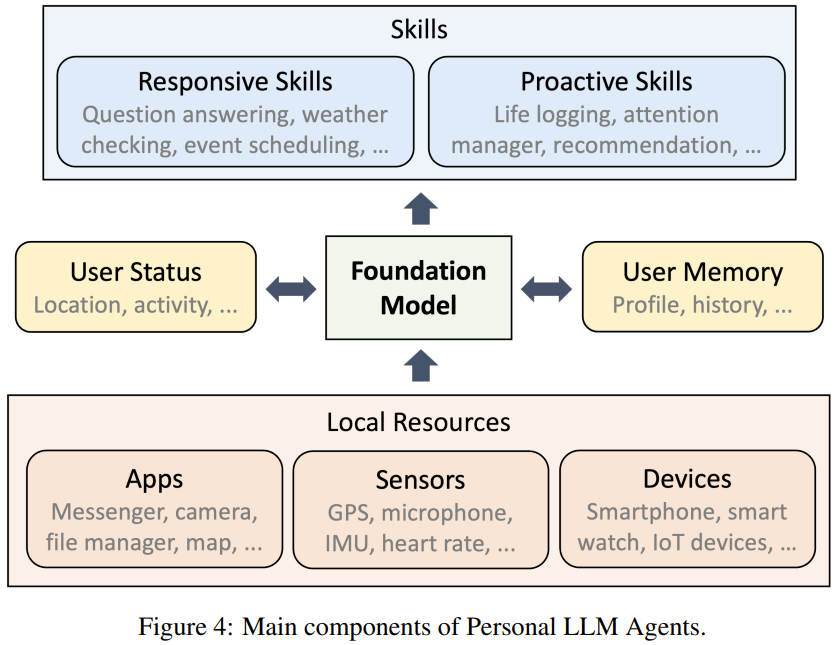
基於對個人 LLM 智能體所需功能的討論,該團隊總結了支持這些功能的主要組件,如圖 4 所示。
個人 LLM 智能體的智能水平
個人 LLM 智能體應具備的功能需要不同的能力。受自動駕駛 6 個等級的啟發,該團隊將個人 LLM 智能體的智能水平分成了 1 級到 5 級共 5 個層級,如圖 5 所示。
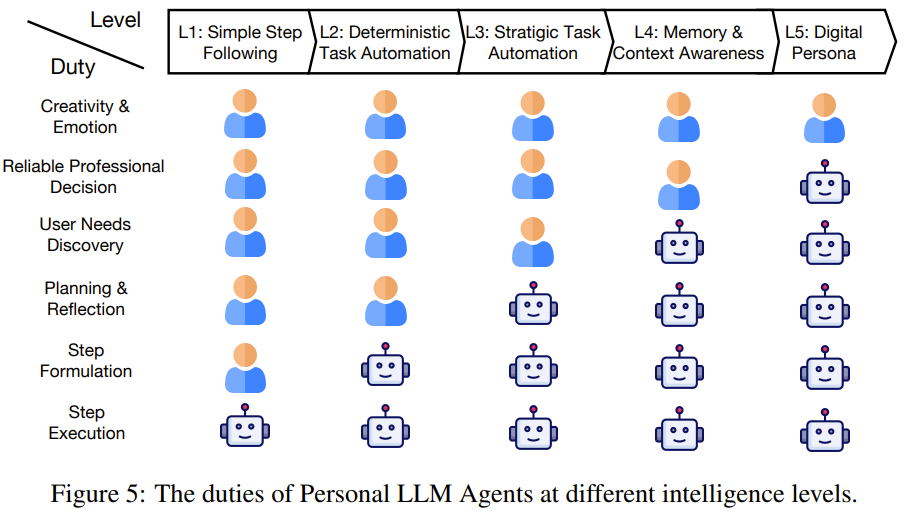
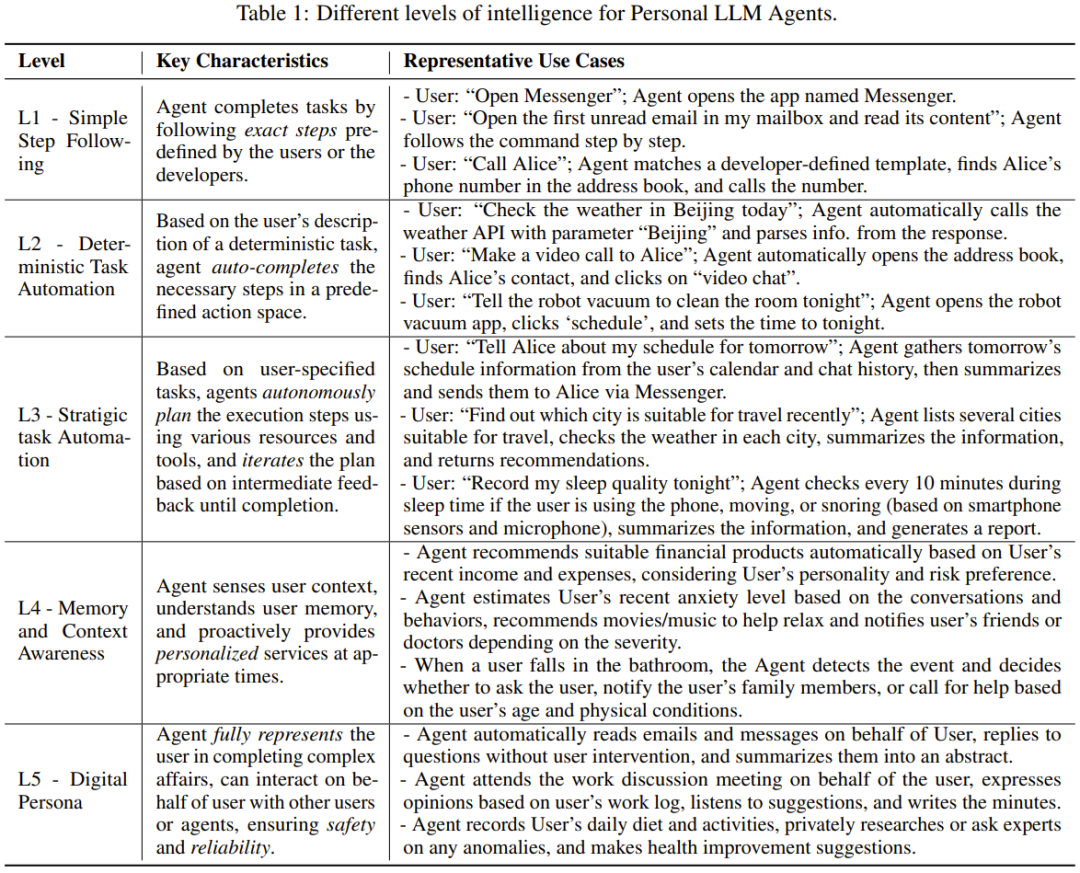
下錶 1 列出了每一級的關鍵特徵和代表性用例。
對常見問題的看法
接下來報告的是該團隊收集整理的對一些常見問題的專家意見。這些問題包括部署個人 LLM 智能體的設計選擇和潛在挑戰,如表 2 所示。

該團隊分析了所得答案,並總結出以下關鍵見解。
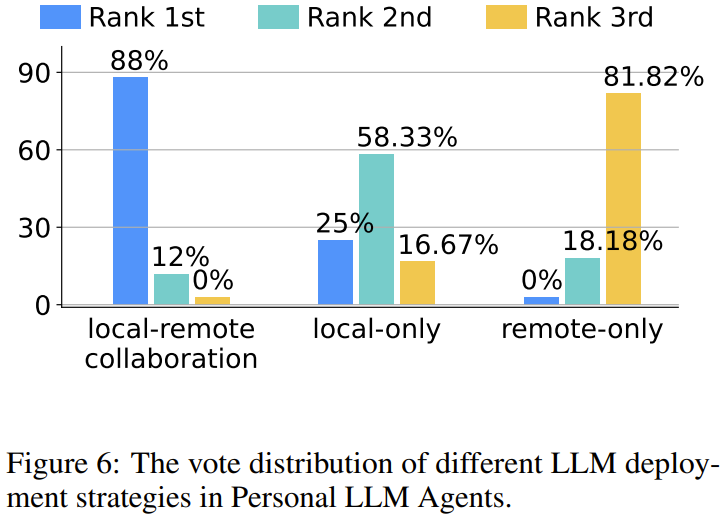
意見 1(將 LLM 部署在哪裡):將 LLM 在邊緣 - 雲(本地 - 遠程)協同部署是首選,而現有的純雲(僅遠程,例如 ChatGPT)並不是一個被廣泛接受的解決方案。
意見 2(如何定製智能體):在定製化方面,人們最接受的方法是組合使用微調和上下文學習。

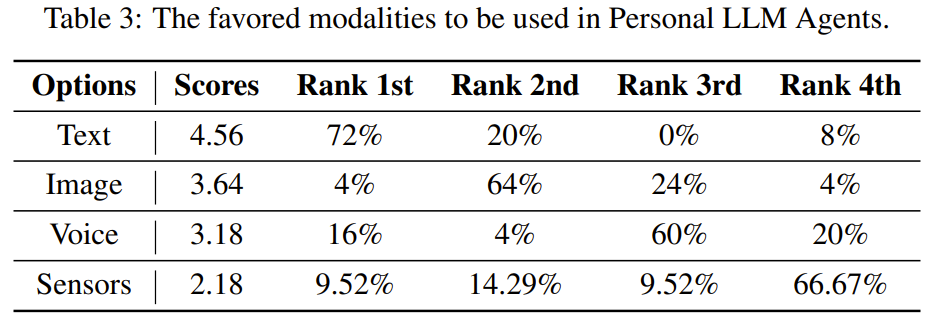
意見 3(使用哪些模態):個人 LLM 智能體最需要的是多模態 LLM,尤其是文本和視覺模態。
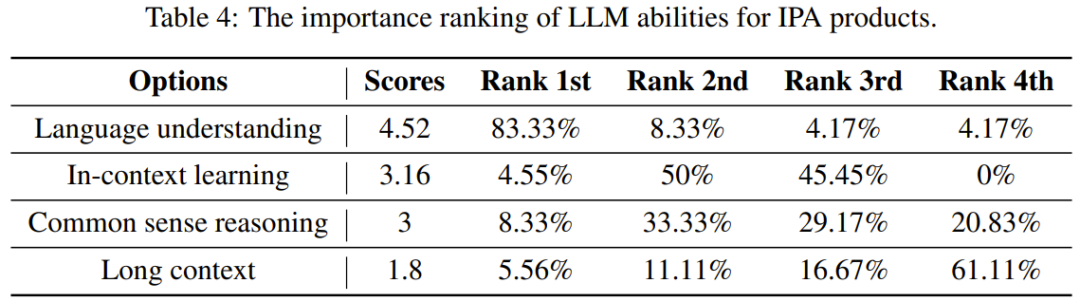
意見 4(哪些 LLM 能力對 IPA 產品最重要):專家認為最重要的 LLM 能力是語言理解,而最不重要的能力是處理長上下文的能力。
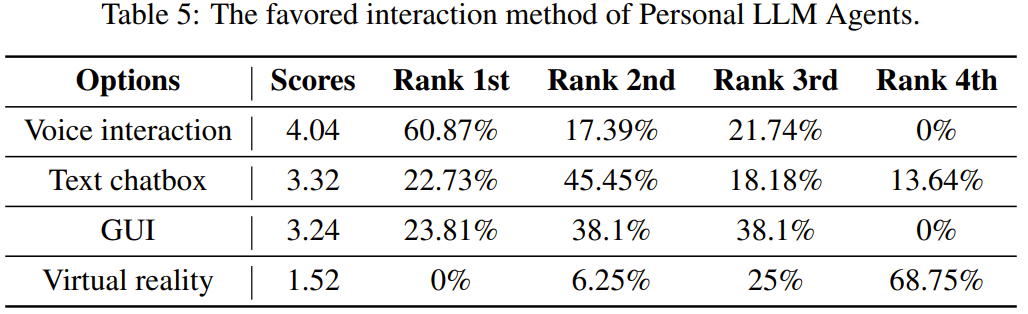
意見 5(如何與智能體交互):基於語音的交互是最受歡迎的方式。
意見 6(需要開發哪些智能體能力):對於個人 LLM 智能體的未來開發,參与專家認為最重要的功能是「更智能和更自動化的決策能力」。
意見 7(理想的 IPA 需要哪些功能):根據參与專家的回答,可以總結出理想智能體應具備的六大關鍵功能:高效的數據管理和搜索,工作和生活輔助,個性化服務和推薦,自動化任務規劃和完成,情感支持和社交互動,作為用戶的数字代表等。
意見 8(最緊迫的技術挑戰有哪些):根據參与專家的回答,可將最緊迫的技術挑戰分為以下類別:智能(包括多模態支持、上下文理解和情境感知型行動、增強輕量級 LLM 在特定領域的能力);性能(有效的 LLM 壓縮或緊湊架構、實用的本地 - 遠程協作架構);安全和隱私(數據安全和隱私保護、推理準確度和無害性);個性化和存儲;傳統操作系統支持。
基本能力
為了讓個人 LLM 智能體支持各種不同的功能,需要讓其具備一些基本能力。除了普通 LLM 智能體都有的基本功能之外,這裏重點關注的是個人助理應具備的三項基本能力:任務執行、情境感知、記憶。圖 8 給出了這些基本能力之間的關係。
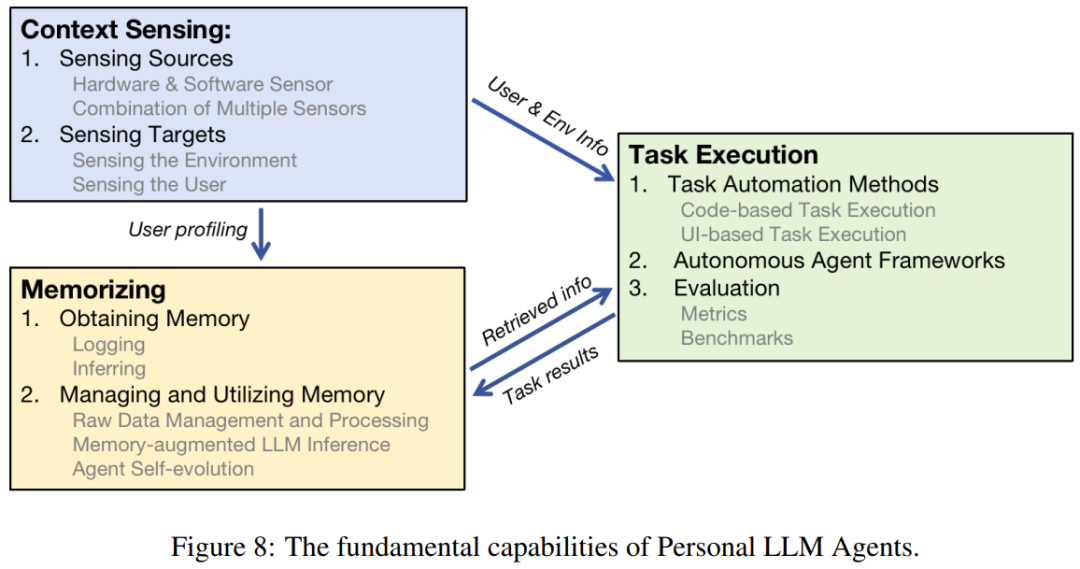
任務執行
個人 LLM 智能體的任務執行能力讓其可以響應用戶請求並執行指定的任務。在該團隊設想的場景中,智能體需要與智能手機、計算機和物聯網設備等各種個人設備交互並控制它們來自動執行用戶指令。
任務執行功能的一項基本需求是智能體有能力準確理解用戶下達的任務。通常來說,任務可能來自用戶口頭或書面下達的指令,智能體可以從中解讀出用戶的意圖。隨着語音識別技術的成熟,現在已經能非常方便地將語音信息轉換成文本。
在將用戶命令轉換成文本后,個人 LLM 智能體應該能自動進行規劃和採取行動。儘管規劃對傳統 DNN 來說很困難,但基於 LLM 的智能體在這方面卻表現很好。之前已有一些綜述論文討論了 LLM 智能體的規劃和推理能力。這篇論文關注的重點是操作個人數據以及與個人設備交互。一個需要考慮的重點是個人 LLM 智能體交互的應用或系統可能缺乏全面的 API 支持。因此,可以探索將用戶界面(UI)作為個人智能體的重要工具,以在 API 受限的場景中實現有效交互。
情境感知
情境感知是指智能體感知用戶或環境的狀態的過程,如此一來便可提供更定製化的服務。
這篇論文對情境感知採用了更廣義的定義,把一般的信息收集過程都視為感知。基於硬件的感知遵循傳統的感知概念,其中涉及到通過各種傳感器、可穿戴設備、邊緣設備等數據源。另一方面,基於軟件的感知則有各種各樣的數據獲取方式。舉個例子,分析用戶的打字習慣和常用短語就是一種基於軟件的感知。
在個人 LLM 智能體中,情境感知能力有多種作用:實現對感知型任務的支持、補充情境信息、觸發情境感知型服務、增強智能體的記憶。
記憶
記憶是指記錄、管理和使用歷史數據的能力。該能力讓智能體可以跟蹤用戶、學習過去的經驗、提取有用知識以及使用這些知識來進一步提升服務質量。相關的研究工作主要是想解答兩個問題:如何獲取記憶以及如何使用記憶。
效率
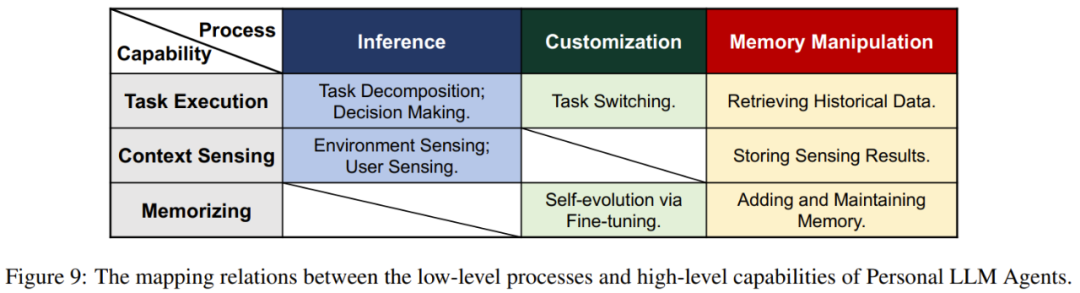
由於許多個人設備的硬件資源和能源供應有限,因此提升個人 LLM 智能體在部署階段的效率是非常重要的。之前討論的任務執行、情境感知和記憶等個人 LLM 智能體的基本能力都還有更基礎的過程,主要包括 LLM 智能體的推理、定製化和記憶檢索,見圖 9。這些過程都需要針對效率進行精心的優化。
LLM 的推理能力是智能體的各種能力的基礎。因此,LLM 推理可能成為個人 LLM 智能體的性能瓶頸,需要仔細優化其效率。
定製化也是個人 LLM 智能體用於滿足不同用戶需求的重要過程。由於定製化的需求很大,因此該過程可能會給系統的計算和存儲資源帶來較大壓力。
記憶操作也是一個高成本過程。為了提供更好的服務,智能體可能需要訪問更長的上下文或外部記憶,比如環境感知數據、用戶配置文件、交互歷史、數據文件等。
圖 10 總結了可用於提升 LLM 智能體效率的技術。
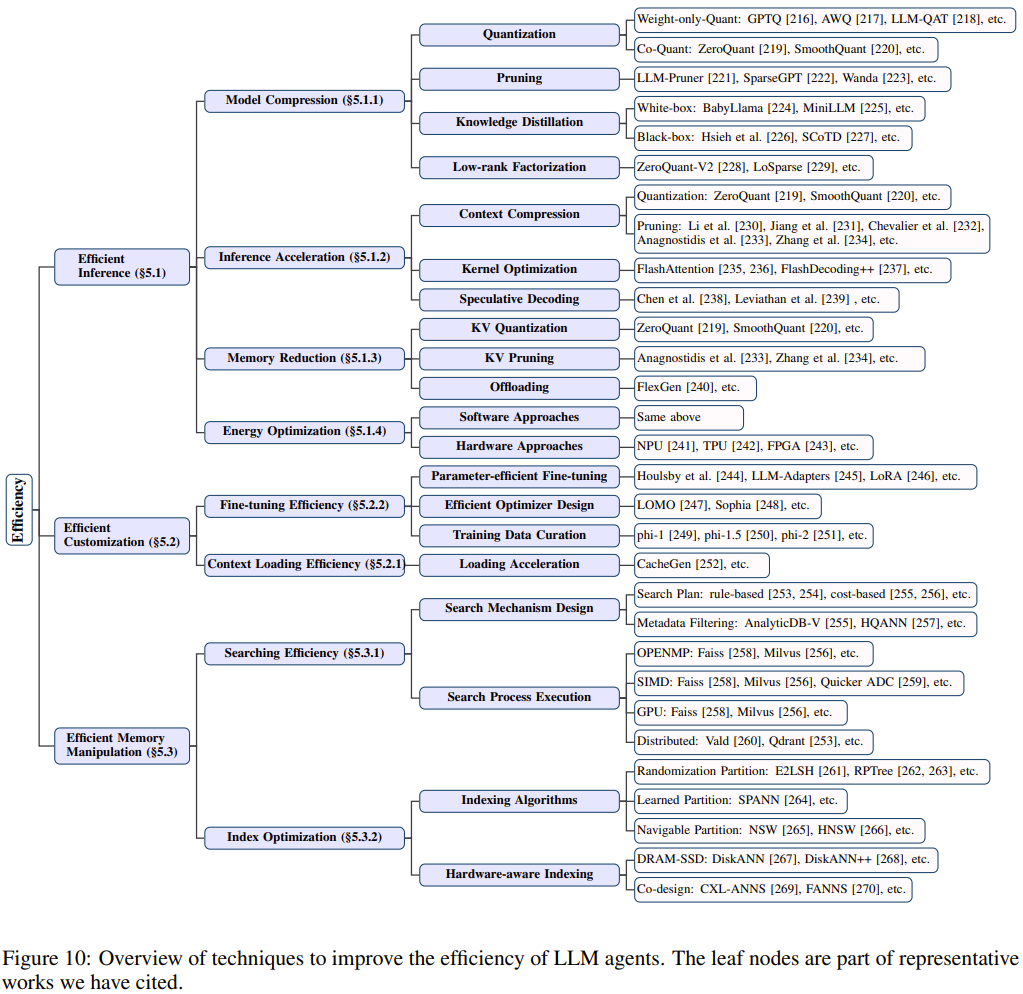
高效推理
為了提升 LLM 的推理效率,人們已經提出了很多模型或系統層面的方法,其中包括:
模型壓縮:直接降低模型大小或減少計算量,從而降低 LLM 在計算、內存和能量方面的需求,進而提升推理效率。模型壓縮技術可以進一步分類:量化、剪枝(稀疏化)、蒸餾和低秩分解。
推理加速:除了下面會提到的讓模型更緊湊之外,還有一些用於加速 LLM 推理過程的技術。LLM 與傳統非 Transformer 模型的一大關鍵差異是注意力機制。由於注意力的計算成本會隨上下文長度而近二次增長,因此增強模型在長上下文推理方面的計算效率就格外重要了。為了更好地支持長上下文推理,現有的研究工作主要集中於降低上下文長度和優化注意力核。
減少內存用量:LLM 推理不僅計算成本高,而且內存需求也大,這也是部署個人 LLM 智能體的一大挑戰。KV 緩存和模型權重是內存開銷的兩個主要原因。研究者已經針對這兩方面提出了一些優化方法,包括通過量化或剪枝技術來壓縮 KV 緩存。
能耗優化:能耗高的智能體不僅會增加部署成本和碳足跡,而且還會因為溫度升高和潛在的熱節流而損害體驗質量(QoE)。由於計算和內存訪問(主要是權重加載)是高能耗的兩個主要原因,因此有很多旨在優化這兩個方面的研究,其中既有軟件方面的研究,也有硬件方面的研究。
高效定製化
個人 LLM 智能體可能需要使用同一個基礎 LLM 為不同用戶提供服務,在不同場景中執行不同的任務,因此這需要針對每種情況進行高效的定製化。
定製化 LLM 行為的方法主要有兩種:一是為 LLM 提供不同的上下文 prompt 供其上下文學習,二是使用特定領域的數據微調 LLM。因此,定製化效率的主要決定因素是上下文加載效率和 LLM 微調效率。
上下文加載效率:提升上下文加載效率的方法有很多。一種簡單的方法是去掉冗餘的 token,縮短上下文長度。另一種方法是降低上下文數據傳輸過程中的帶寬消耗。
微調效率:這方面的技術大致可以分為這些類別:參數高效型微調技術、高效的優化器設計和訓練數據組織管理。
高效操作記憶
為了給出明智的決策,個人 LLM 智能體需要頻繁地檢索內部或外部記憶。在 LLM 推理階段,內部記憶會表示成上下文 token 並以 KV 緩存的形式存儲。內部記憶的檢索是由 Transformer 架構中的自注意力模塊隱式處理的。這就需要 LLM 在執行推理時,在長上下文上執行更高效的計算,同時儘力最小化內存足跡。這些問題與之前討論的 LLM 的推理效率類似。因此,這一小節主要關注的是操作外部記憶(可被動態檢索並添加到上下文中)的效率。
考慮到外部記憶數據的多樣性,比如用戶配置文件、交互歷史和本地原始文件(圖像、視頻等),常見做法是使用嵌入模型將記憶數據表示成一種統一格式的高維向量。向量之間的距離表示對應數據之間的語義相似度。對於每一次查詢,智能體都需要在外部記憶存儲中找到最相關的部分。這個過程以及對向量的維護工作可以通過向量軟件庫(如 Faiss 和 SCaNN)、向量數據庫或某種定製的記憶結構完成。不管這些系統的功能有何差異,他們的效率優化目標基本都集中於兩個方面:搜索和檢索。
安全和隱私
個人 LLM 智能體不同於普通 LLM 智能體,會使用大量敏感的個人數據和安全性至關重要的個人工具。因此,保護個人 LLM 智能體用戶的數據隱私和服務安全就成了一個至關重要的問題。在個人 LLM 智能體語境中有三大安全原則:保密性、完整性和可靠性;如圖 11 所示。
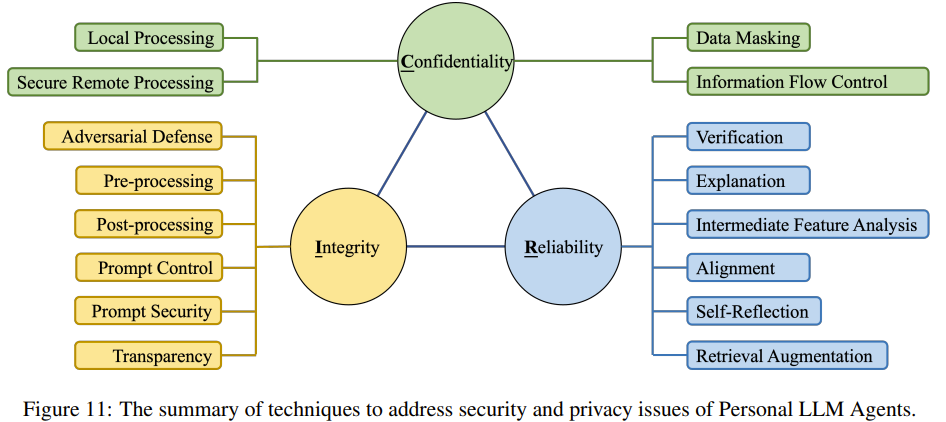
保密性
這一小節討論的是在使用個人 LLM 智能體時保護用戶隱私的可能方法。前面已經提到,由於個人助理有權訪問大量敏感的用戶數據,因此確保用戶隱私至關重要。
不同於用戶需要明確輸入文本的傳統 LLM 聊天機器人,個人 LLM 智能體有可能在用戶不知情的情況下自發啟動查詢,其中可能包含有關用戶的敏感信息。另外,智能體也可能將用戶信息暴露給其它智能體或服務。因此,保護用戶隱私就變得更加重要了。
增強保密性的方法有很多,包括本地數據處理、同態加密、數據脫敏、訪問權限控制等。
完整性
完整性是指讓個人 LLM 智能體有能力確保正確輸出用戶期望的內容,即便在面臨各種類型的攻擊時也能做到。
由於個人 LLM 智能體必定會和不同類型的數據、應用及其它智能體交互,所以它有可能遇到惡意第三方的攻擊,這些攻擊的目的通常是通過非常規手段竊取用戶數據和資產或破壞系統的正常功能。
因此,系統必須有能力抵禦各種類型的攻擊。通過加密、權限控制、硬件隔離等措施,可以防禦模型參數修改、竊取、篡改本地數據等傳統攻擊方式。但是,除了防禦傳統的攻擊方法外,還應該關注 LLM 智能體可能遇到的新型攻擊:對抗攻擊、後門攻擊和 prompt 注入攻擊。
可靠性
使用個人 LLM 智能體時,許多關鍵操作是由 LLM 決定的,包括一些敏感操作,例如修改和刪除用戶信息、採購服務、發送消息等。因此,確保智能體決策過程的可靠性至關重要。
該團隊從三個方面探討了 LLM 的可靠性,包括問題(即 LLM 的可靠性問題體現在哪裡?)、改進(即如何讓 LLM 的回答更可靠?)和檢查(即如何處理 LLM 可能輸出的不可靠結果?)。
更多技術細節請參閱原論文。