所有語言











分享
手機大模型背後的AI芯片暗戰,挑戰的不只是摩爾定律
巴比特_腾讯科技344天前
文章來源:騰訊科技
作者:郭曉靜

圖片來源:由無界AI生成
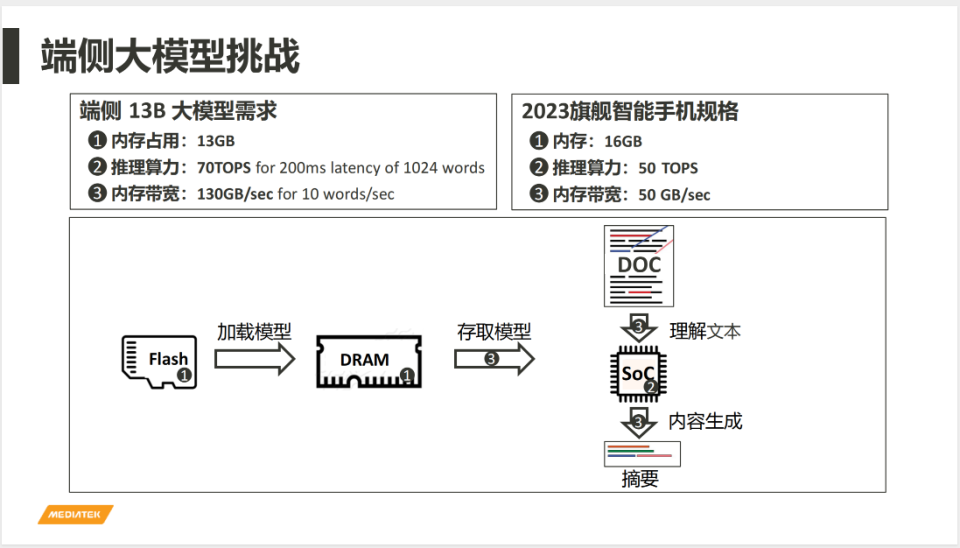
智能手機集成AI技術已非新鮮事,自2017年起,AI便開始在圖像降噪等處理任務中發揮作用,並逐步擴展至幀率優化、畫質增強等場景應用。然而,這些早期應用所依賴的模型參數量通常不超過1000萬,與當前討論的端側大模型相比,其規模相差很遠。如今,即使是最小的端側大模型,其參數量也已達到10億,是早期模型的100倍。儘管如此,這些10億參數級的模型也只能執行一些基本的文本處理任務。
考慮到手機用戶對多模態(文本、圖像、視頻等)處理的需求,甚至需要動輒百億參數的模型才能提供滿意的用戶體驗。手機運行如此大規模的模型,需要至少13GB的內存和130GB/s的帶寬。然而,觀察到2023年旗艦手機的配置,內存通常為16GB,帶寬為50GB/s,這樣的硬件配置使得在手機上運行大模型看起來幾乎成為不可能的任務。
儘管如此,手機廠商和用戶都渴望將大模型集成到手機中。手機行業增長放緩,廠商急需新體驗來打破僵局。集成大模型的手機承載着新的重要任務——打破傳統應用壁壘、垂直整合軟硬結合的新生態。同時,用戶對大模型的認知逐漸形成,他們期望能夠在智能手機上享受到大模型帶來的便利。
2023年下半年開始,我們逐漸看到各大手機廠商爭相進入大模型賽道,而背後,芯片廠商正在賦能。芯片的進化被認為符合摩爾定律,那就是每24個月左右,晶體管的密度就會成倍,目前摩爾定律的速度已經明顯放緩,每年僅能增長20%-30%,而以端側AI的複雜度來講,每年需要底層硬件提升的性能則需要達到至少兩倍。如何突破摩爾定律的瓶頸從而達到用戶期待的性能需求,考驗的是芯片廠商的創新能力。
另外,除了芯片本身的性能,如何能讓芯片在手機上發揮最大的能效來達到更好的體驗,還需要芯片廠商的生態能力、服務能力等各個方面的持續發力。
在這場手機芯片大進化的背後,聯發科和高通是最受矚目的兩大玩家。在2023年10月的驍龍峰會上,高通發布了驍龍8Gen3,支持運行100億參數端側大模型。緊隨其後,聯發科發布了天璣9300,支持運行10億至330億參數的端側大模型。
AI能力的增強正成為芯片廠商新的競爭焦點。本期《AI未來指北》端側大模型系列,將深入探討手機端側大模型背後的軟硬件創新。我們對話了聯發科技計算與人工智能技術事業群副總經理陸忠立博士,作為這場AI芯片進化的親歷者和推動者,在本次對話中,他分享了關於這一領域的一些關鍵見解:
● 把大模型裝入手機,需要哪些關鍵步驟?
● 把大模型裝進手機,僅僅是營銷噱頭嗎?
● 大模型能力的上限取決於什麼?
● 如果摩爾定律失效,芯片如何才能不斷突破能力極限來應對越來越複雜的應用端需求?
以下為對話內容精編:
01、芯片能力的上限決定了端側大模型能力的上限嗎?
騰訊科技:Allen(陸忠立)你好,端側大模型是目前行業關注的一個重要方向,我們看到今年各大手機廠商的一個宣傳重點就是端側大模型,這對產業來講,會是一個巨大的機遇嗎?
陸忠立:我們認為這是一個千載難逢的機會,就像大家所講的AI是iPhone Moment。現在的大模型讓智能手機從Smart Phone變成了AI Smart Phone這樣的概念。
傳統的智能手機可以下載APP,這些APP讓你的手機變得很聰明,這個智能並不是手機變智能,對於使用者而言,只是在消費內容而已。
現在端側大模型出現,會顛覆原來的使用體驗。舉例來講,你現在買一個東西可能要到多個電商平台去找最低價的產品,或者通過比價網站找到性價比最好的產品。如果有一個AI助手或智能體,它能夠自動幫你去做這些事情,找到最適合你的產品。這樣的話,從“你”的角度來講,這才叫AI Smart Phone。AI Smart Phone和Smart Phone最大的區別就是它能更了解使用者,讓使用者更容易達到他想要做的事情,而且是完全朝着對使用者有利的方向。我們覺得現在看起來大模型、多模態、智能體這一系列的發展,就是往這個方向在走,讓所謂的智能手機變得更智能化,成為AI Smart Phone。
騰訊科技:這樣看來,未來大模型會不會是一個超級入口?
陸忠立:我們認為大模型後面會變成一個新的入口,主要就是因為它可以智能化地跟使用者溝通。但是大語言模型僅僅是第一個階段;第二個階段則是多模態。
第一階段大語言模型,就像大腦,它能夠跟你對話,到了第二階段就等於多了感官,多了眼睛、耳朵。所以它能夠接收到更多的資訊,能夠更深入地理解使用者的意圖,也更能夠全面了解這個世界,我們都能看到,像谷歌最近發布了雙子星(Gemini),蘋果前幾天也發布了它的多模態模型。
第三個階段,就是智能體的階段。它除了接收外界信息、有了感官以外,還能夠做執行。通過一些工具,例如通過調用APP做大家衣食住行相關的事情。如果沒有APP,它則可以自己寫代碼,然後產生出它要的一些結果。
目前還在第二階段多模態的階段,未來會慢慢走向智能體的階段。
騰訊科技:在目前這個階段,你覺得消費者會因為大模型的功能而換手機嗎?
陸忠立:從我自己來講,我會的。即使在目前這個階段,我們已經看到一些顛覆性的應用,後面只會有越來越多的應用。
另外,現在99%的大模型都是運行在雲端上算力很強,不過本地端會有無法替代的幾個優點:第一就是隱私性的問題。因為很多隱私信息,比如說我的聲音或者是影像,我並不希望被上傳到雲端變成訓練材料的一部分。另外可以做個性化,如果說語言模型根據你的聲音來更適配,準確度可能會更高。第三,我目前覺得最重要的部分是成本。像我剛剛講到的雲端APP,每個月還是要交一定的錢。假設這個能夠跑在端側,原則上大概除了你一開始買手機的費用,後面基本上就是免費的。
當然,端側有這些好處,但並不是說端側會完全取代掉雲側,雲端大模型有它不可取代的優點,比如說準確率很高,可以處理複雜的事情,特別是一些需要全局資訊的工作還是需要雲端模型來做。
騰訊科技:我們知道其實大模型是需要很強的算力,芯片能力的上限,是否決定了端側大模型能力的上限?
陸忠立:端側大模型很大一部分的確是受限於芯片處理的能力。大模型目前我們看起來有三個需求,一個是剛才您提到芯片算力的部分,另外還有兩個很重要的部分,一個是內存的容量,還有內存的帶寬。甚至在某些情況下,內存的容量跟內存的帶寬會影響到整個大模型執行的性能。所以端側來講,目前我們看到的是芯片很大部分決定了你在端側大模型能夠跑的大小,或者是速度。
舉例來講,以2023的旗艦手機來講,算力大概都是在40TOPS到50T(TOPS)左右,內存的容量大概是在16GB,內存的帶寬大概是在50GB/s,大概是這樣的数字。
如果在端側跑一個130億的大模型,它需要的算力、內存容量、內存帶寬都超過目前旗艦機能夠提供的能力。
所以就需要在幾個方面做改善:
第一,硬件方面,需要一些專用的硬件來加速大模型的執行。
第二,在算法和軟件上面,利用類似於模型剪枝的技術,我們可以把大模型裏面不需要執行的部分或者是很少執行的部分修剪掉,然後再來做量化,從16Bit(比特)量化到4Bit(比特),從而減少對內存的容量佔用跟帶寬需求。
第三,可以做壓縮。
騰訊科技:如果拋開硬件的限制,手機端側跑大模型,參數量也是越大越好嗎?
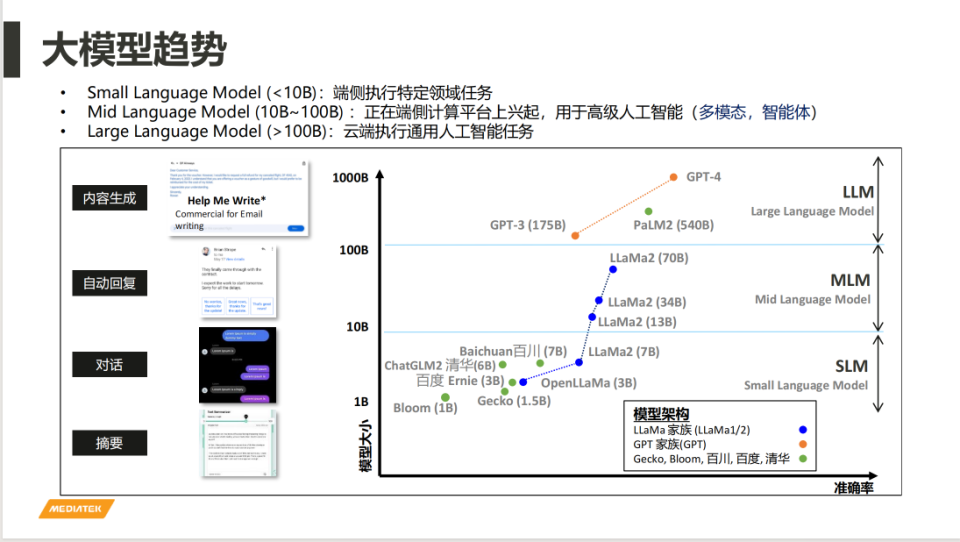
陸忠立:我並不認為是越大越好,最重要的還是適配性的問題,需要的模型規模與要完成的具體特定工作有關。舉個例子,如果僅僅是處理文章的摘要,我們發現10億參數左右的大模型能夠達到的效果其實跟ChatGPT的效果差不多。如果你要進行一些對話,需要的內存帶寬,還有算力也會越大,這個連帶影響需要的功耗也會越大。我想大部分人也不希望買一個智能手機,做了簡單的對話,但是馬上就沒有電了。
所以手機大模型的參數量要考慮到性能和功耗的平衡,根據用戶所需要的性能以及目標應用有哪些來決定大模型的參數量。
騰訊科技:我們都知道在雲端跑大模型成本很高,那麼在手機端側,具有AI能力的芯片成本會增加多少?用戶會不會對成本的增加有所感知?
陸忠立:以芯片成本來講,如果加上執行大模型的能力,對於整個芯片來講會有一些成本的增加。芯片並不只是在執行大模型,芯片裏面有CPU、GPU、APU,還有各種不同功能的模組。剛剛講的大模型主要是增強在APU方面的性能和面積,所以對於整體的成本增加有限,以有限成本的增加換取整個大模型在端側執行,可以讓使用者的體驗有遠超以往的改善。
02、摩爾定律失效了嗎?
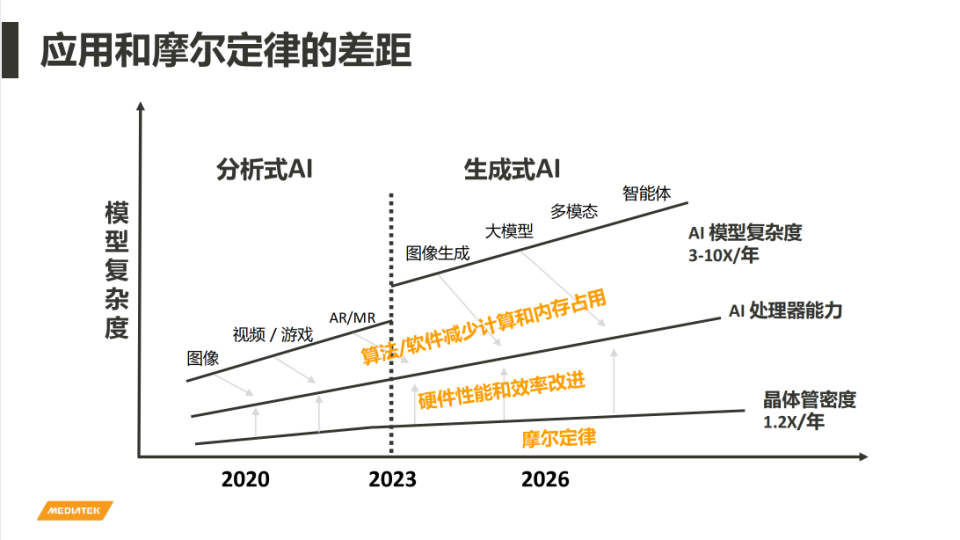
騰訊科技:當 生成式AI加上我們可能越來越複雜的遊戲需求、拍照需求,對手機芯片的要求是不是越來越高了?摩爾定律失效了嗎?未來可能有哪些更好的方法去突破這種手機的芯片能力極限?
陸忠立:摩爾定律是18個月,或者是每24個月它的晶體管密度就會成倍,但是到了先進製程我們看到整個趨勢是變慢下來,以目前來看的話,大概每年可能增長20%到30%。從應用層面來看,聯發科技也大概做了一些統計,以端側AI模型的複雜度來講,每年增加的幅度可能都是兩倍、三倍,甚至是十倍,所以看到這兩個的確是有蠻大的差距。
這個差距沒有辦法完全靠摩爾定律來彌補,所以就需要在硬件上面有所創新。另外更重要的,是在算法和軟件層面的創新。
當然還有一些其他的做法,比如異構集成,比如說小芯片,或者是說3D封裝,另外就是一些更先進的技術路線的探索,比如光子計算、量子計算,這個都是未來的事情。
騰訊科技:天璣9300,採用了全大核的設計,這個做法很激進,也在嘗試突破摩爾定律的創新嗎?
如果芯片的性能,按照摩爾定律能夠一直很順利地提升性能,我們肯定會依據摩爾定律進行技術迭代,這占的比例就會比較高。
如果說摩爾定律提供的性能是比較有限,我們就需要在架構上面做一些創新,全大核的架構基本上從這個點開始出發的,同時我們的工程團隊也的確能夠解決全大核的一些挑戰。
當初我們遇到的兩個比較大的難題:第一個難題是在全大核狀況下怎樣平衡性能和能效。全大核性能一定會比較好,怎麼做它的能效和熱管理就變得很重要的。
第二個問題,在一些比較日常的場景,對性能要求沒有那麼高,如何讓能效達到最好,讓大核得到小核的功耗,後來我們也解決了這個問題,簡單來講叫快開快關。
原來小核設計的理念就是讓它功耗盡量低,可能性能就會差一點。我們發現在全大核的設計下,我們可以把一些事情集中在一起,大核只要快開,開完把這些事情做完了,然後就關掉,讓它休眠,不用浪費額外的功耗就可以達到小核的效果。所以說一舉兩得,用全大核既能得到性能的好處,又不會損失掉低功耗的優點。
所以發覺這兩件事情能夠克服,再加上我們經過內部的討論,還有跟客戶的討論發現,客戶對性能的要求也是越來越高。
所以我們在兩年前就決定後面要做全大核架構,事實證明現在看起來是正確的,因為應用面也越來越複雜,遊戲也越來越複雜,像最近講的生成式AI,對AI的應用也越來越複雜,還有很多內容創作也需要更強勁的大核,所以全大核的確是現在整個產業的一個趨勢。
我們內部跟客戶談過以後對於未來性能的預期,因為在手機界常常講,每年CPU、GPU、APU都要成長多少的百分比,這樣才能夠提供給客戶。
騰訊科技:大概多少百分比呢?
陸忠立:看需求,AI的需求會比較高一點,百分比會比較高,在30%到50%左右,CPU和GPU可能會稍微低一點,因為之前成長很快,現在越來越困難,所以百分比就會比AI低一點。
騰訊科技:天璣9300可以支持33B(330億參數)的大模型在端側運行,運行33B是一種什麼樣的狀態呢?是不是這個芯片別的都不做,就完全只跑端側大模型這一件事能夠運行330億參數?
陸忠立:這件事要分成兩個層面來看:一個是能不能做得到;另外就是它跑得順暢不順暢。33B在手機上面能夠跑,但是它跑出來的結果和速度並不是馬上可以應用到,不過這是手機能力的一個展現。
7B跟13B可以在手機上跑,基本上也可以給用戶很好的體驗,所以有一些是比較前瞻性的東西,我們要在芯片上先準備好,當然這是第一階段,能不能跑。第二階段,跑得快不快。第三階段就是準確率高不高,這是一個漸進式的過程。
騰訊科技:天璣9300和天璣8300都可以支持AI能力了,是不是未來不僅僅是旗艦機,在中低端手機也希望能夠搭載大模型的能力?
陸忠立:對。旗艦機能夠執行大模型,我覺得這隻是一個開始而已,我們希望AI能夠普惠化。當然這個有賴於剛剛提到的摩爾定律會讓晶體管越來越多,另外就是因為算法、算力的一些改善,能夠讓一些模型能夠用比較少的資源就能夠執行。
03、未來端側大模型的應用將如何演進
騰訊科技:總結一下把大模型裝進可能需要哪些關鍵的步驟?
陸忠立:這有點像當初遇到的一個問題,把長頸鹿放到冰箱里,第一步先打開冰箱,然後塞進去。其實到後來也就是這個樣子,一開始發現說塞不進。我們從去年(2022年)開始就已經有看到大模型這件事情,那時候覺得離手機來講還是有點遠。因為那時候的模型就是ChatGPT,大概1750億參數,跟手機能夠做的實在相差很遠。不過我們還是有一直在關注這件事情,我們事實上從2019年就開始在基於Transformer模型在做一些應用,跟我們的客戶端在很多視頻及拍照場景就有落地。
所以後來看到大模型也是基於Transformer的架構,所以我們也在思考有沒有可能把這樣的東西放到端側。只是說那時候覺得距離差得很遠。
直到特別的Eureka Moment(尤利卡時刻),就是Meta發布了它的模型Llama,包含7B、13B、70B,這個看起來就近了很多,所以我們那時候就決定要全力投入,看看怎麼樣把這樣的模型能夠放到端側。大概的一個起心動念是這個樣子。
回到我們說的手機大模型,即使7B,其實跟原來的手機AI模型也差距很大。原來的手機AI模型,參數量一般來講大概是在1000萬參數以內,到目前的手機端側大模型最小的1B也已經是10億,所以基本上要加上100倍的樣子。如果你要更大一點,就要1000倍。如何把這樣的模型放到端側,研發同仁花了很多的時間去想辦法拆解,這是第一步。
第二個是整個生態系,因為它是Open(開源)的模型,非常給力,很快我們把原來浮點的運算轉換成整數運算,模型大小實際上也縮減的很快。
基於開源生態的發展,我們把生態系的東西再進一步簡化、剪枝、壓縮,然後放到手機裏面。大概是這樣一個過程。
當然這個放進去,就像把大象放到冰箱是第一步而已。第二步是放到冰箱到底要幹嗎?跑起來要順暢,所以後來主要專註的事情就是怎麼樣讓它能夠跑得順、跑得准。放進去是第一件事情,然後再就是跑得順、跑得准。
騰訊科技:跑得順、跑得準是不是主要還是硬件方向?硬件和廠商一起共同合作嗎?
陸忠立:其實硬件、軟件都要,以及跟廠商合作。因為端側大模型準不準是廠商說了算,他們知道要問什麼問題或者什麼應用,以及要什麼樣的答案,那都是由廠商這邊的QC或者QA還有RD來決定。聯發科技的角度就是提供平台,提供對應的工具鏈,能夠讓客戶跑得順。如果結果準確度有什麼問題,大家一起來討論怎麼來解決這個問題。
騰訊科技:除了智能手機,您認為現在還有哪些很重要的終端可能會首先被AI大模型改變?
陸忠立:這是很好的問題。我們自己判斷會有三類重要的終端。第一是剛剛提到的智能手機;第二就是PC,現在都有所謂的AI PC的出現,也是讓你的PC更有智能,可以做更多內容的創作和生產力的提升;第三個很有潛力的是在車用,主要像新能源車,因為它能提供更好的使用者的體驗跟自然語言交互的界面,會讓你跟汽車的互動變得更方便。我們覺得大概這三個會直接受到大模型的影響或者助力。當然,隨着時間的推移,還會再傳播到其他的終端。
騰訊科技:未來在終端場景的應用,我們知道手機高頻使用的功能是拍照片、拍視頻,大家去進行語音對話。這些場景天然就是多模態的,未來端側大模型的應用將如何演進?
陸忠立:我們判斷大概分成三步走:第一步就是現在的大語言模型,主要就是文本進、文本出。第二步就是現在已經在發生的,就是所謂多模態。因為剛剛講這種大語言模型比較像人的大腦,有的時候是一本正經,有的時候也會胡說八道。不過再來就是要有更多的感官輸入,包含視頻、圖像、聲音進來。產出的內容也是一樣,不是只產生文本,也會產生視頻和圖像的輸出,這就是現在多模態在專註的事情。
因為手機本來就是多模態的設備,這樣更能夠感受到整個環境的需求,比較深刻理解目前要做的一些任務或者一些事情,也會提供更多的服務。這就是現在看到的好幾家公司都已經推出多模態的模型。
對於手機的算力來講的確會增加,因為除了原來處理文本以外,現在連圖像,甚至後面的視頻都會加進來,所以算力的需求會更大,再就是內存的容量和帶寬需求也會更大。
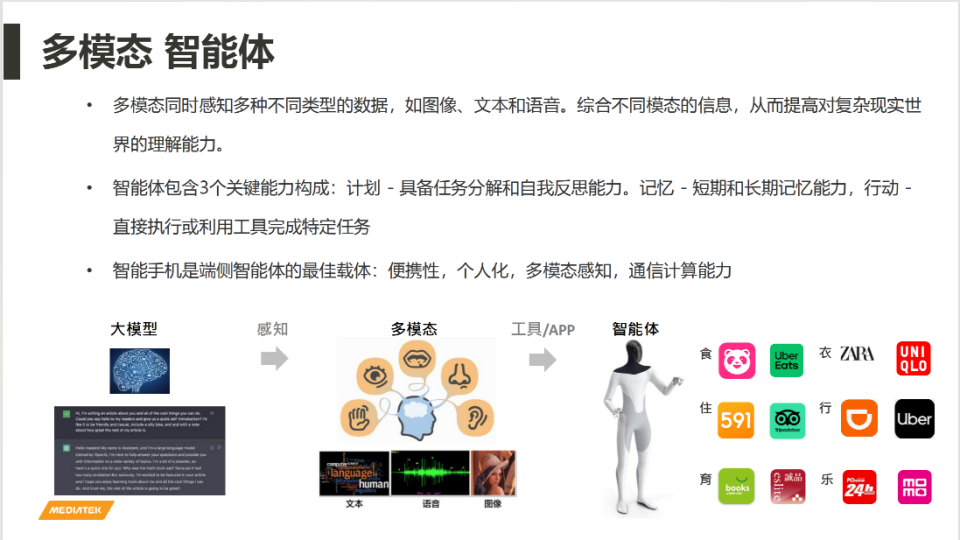
基於這些新的模型,也有一些新的做法。主要還是集中在剛剛講的兩方面,一些是硬件的演進,突破算力。第二個非常重要,甚至有時候更重要的是在算法上面的改進。這些算法的改進,就讓這些多模態的大模型能夠在端側執行。第三步就是到智能體的部分,除了剛剛講的能夠多模態進來以後,還能善用工具或者善用APP執行任務。