所有語言











分享
在Sora引爆視頻生成時,Meta開始用Agent自動剪視頻了
巴比特_硅星人325天前
文章來源:硅星人Pro

圖片來源:由無界AI生成
未來,視頻剪輯可能也會像視頻生成領域一樣迎來 AI 自動化操作的大爆發。
這幾天,AI 視頻領域異常地熱鬧,其中 OpenAI 推出的視頻生成大模型 Sora 更是火出了圈。而在視頻剪輯領域,AI 尤其是大模型賦能的 Agent 也開始大顯身手。
隨着自然語言被用來處理與視頻剪輯相關的任務,用戶可以直接傳達自己的意圖,從而不需要手動操作。但目前來看,大多數視頻剪輯工具仍然嚴重依賴手動操作,並且往往缺乏定製化的上下文幫助。因此,用戶只能自己處理複雜的視頻剪輯問題。
關鍵在於如何設計一個可以充當協作者、並在剪輯過程中不斷協助用戶的視頻剪輯工具?在本文中,來自多倫多大學、 Meta(Reality Labs Research)、加州大學聖迭戈分校的研究者提出利用大語言模型(LLM)的多功能語言能力來進行視頻剪輯,並探討了未來的視頻剪輯範式,從而減少與手動視頻剪輯過程的阻礙。

- 論文標題:LAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing
- 論文地址:https://arxiv.org/pdf/2402.10294.pdf
具體而言,研究者推出了視頻剪輯工具 LAVE,它具備了一系列由 LLM 提供的語言增強功能。LAVE 引入了一個基於 LLM 的規劃和執行智能體,該智能體可以解釋用戶的自由格式語言命令、進行規劃和執行相關操作以實現用戶剪輯目標。智能體可以提供概念化幫助(如創意頭腦風暴和視頻素材概覽)和操作幫助(包括基於語義的視頻檢索、故事板和剪輯修剪)。
為了使這些智能體的操作順利進行,LAVE 使用視覺語言模型(VLM)自動生成視頻視覺效果的語言描述。這些視覺敘述使 LLM 能夠理解視頻內容,並利用它們的語言能力協助用戶完成剪輯。此外,LAVE 提供了兩種交互視頻剪輯模式,即智能體協助和直接操作。雙重模式為用戶提供了靈活性,並允許他們按需改進智能體操作。
至於 LAVE 的剪輯效果怎麼樣?研究者對包括剪輯新手和老手在內的 8 名參与者進行了用戶研究,結果表明,參与者可以使用 LAVE 製作出令人滿意的 AI 協作視頻。
值得關注的是,這項研究的六位作者中有 5 位華人,包括一作、多倫多大學計算機科學博士生 Bryan Wang、Meta 研究科學家 Yuliang Li、Zhaoyang Lv 和 Yan Xu、加州大學聖迭戈分校助理教授 Haijun Xia。
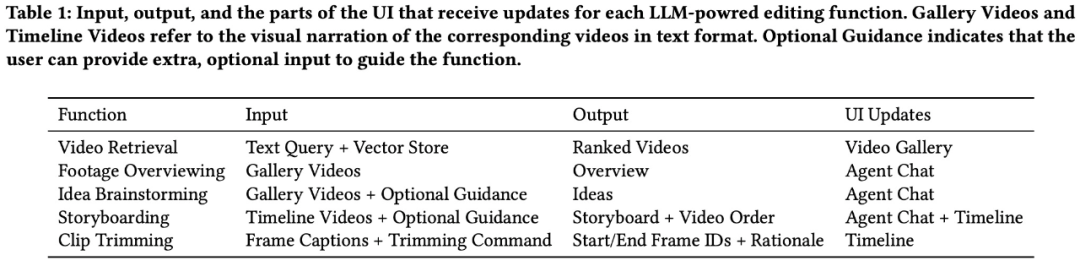
LAVE 用戶界面(UI)
我們首先來看 LAVE 的系統設計,具體如下圖 1 所示。
LAVE 的用戶界面包含三個主要組件,分別如下:
- 語言增強視頻庫,显示帶有自動生成的語言描述的視頻片段;
- 視頻剪輯時間軸,包括用於剪輯的主時間軸;
- 視頻剪輯智能體,使用戶與一個會話智能體進行交互並獲得幫助。
設計邏輯是這樣的:當用戶與智能體交互時,消息交換會在聊天 UI 中显示。當進行相關操作時,智能體對視頻庫和剪輯時間軸進行更改。此外,用戶可以使用光標直接對視頻庫和時間軸進行操作,類似於傳統的剪輯界面。
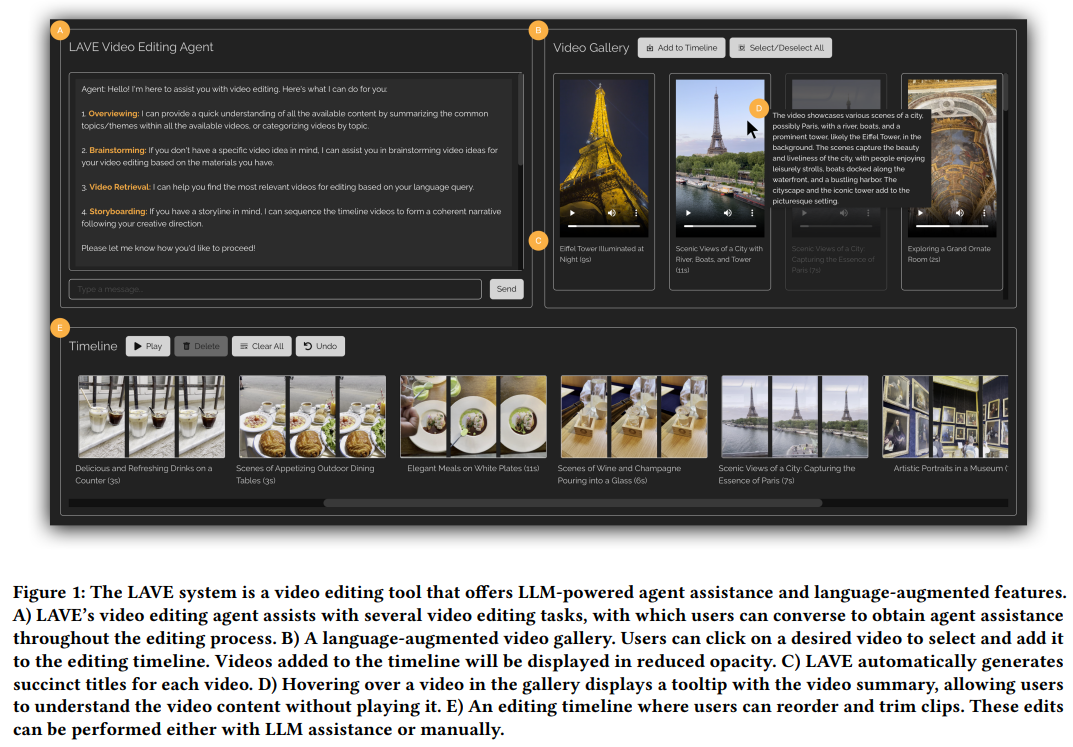
語言增強視頻庫
語言增強視頻庫的功能如下圖 3 所示。
與傳統工具一樣,該功能允許剪輯播放,但會提供視覺敘述,即為每個視頻自動生成文本描述,包括語義標題和摘要。這些標題可以幫助理解和索引剪輯,摘要則提供了每個剪輯的視覺內容的概述,幫助用戶形成自身編輯項目的故事情節。每個視頻下方都會显示標題和時長。
此外,LAVE 使用戶可以利用語義語言查詢來搜索視頻,檢索到的視頻會在視頻庫中显示並按相關性排序。這一功能必須通過剪輯智能體來執行。
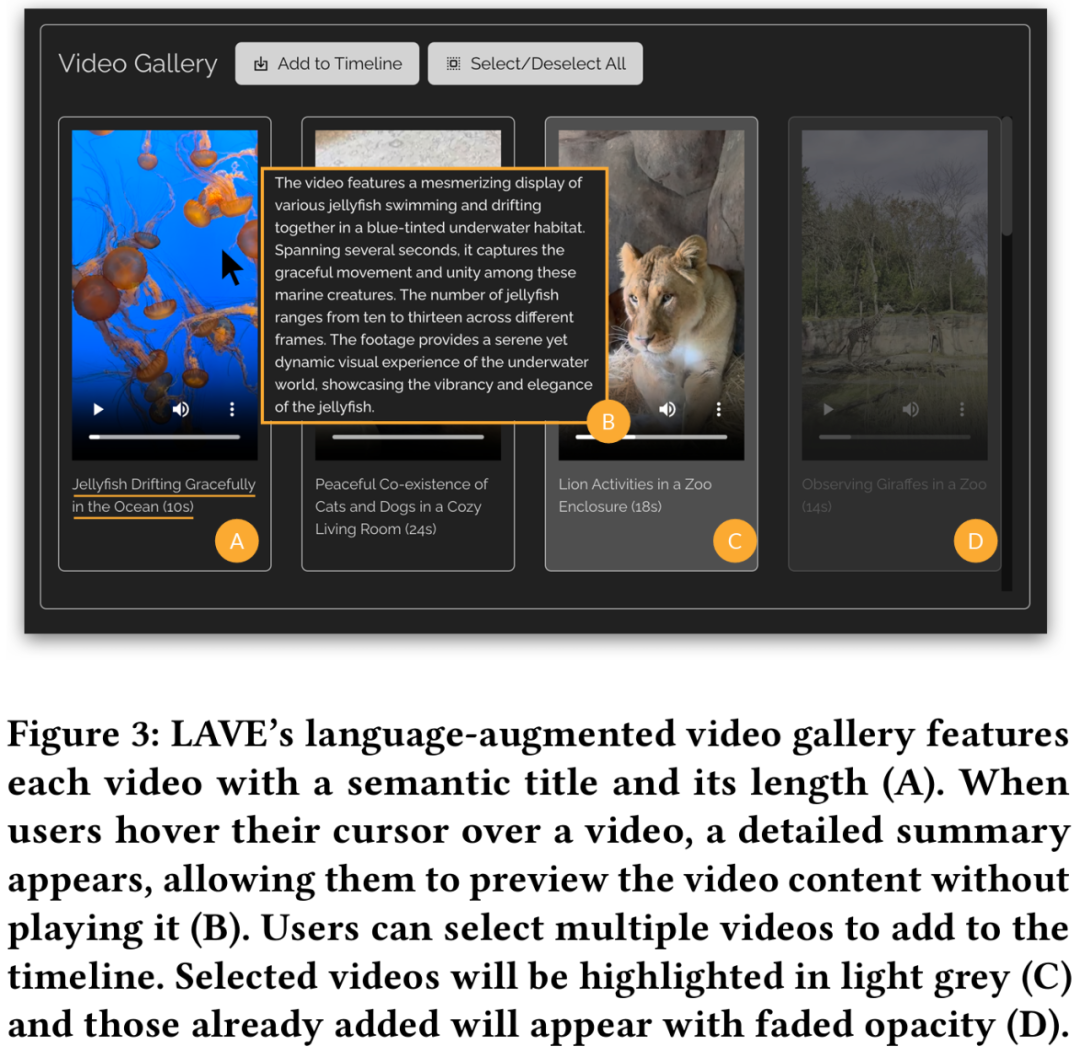
視頻剪輯時間軸
從視頻庫中選定視頻並將它添加到剪輯時間軸后,它們會显示在界面底部的視頻剪輯時間軸上,如下圖 2 所示。其中,時間軸上的每個剪輯都由一個框表示,並显示三個縮略圖幀,分別是開始幀、中間幀和結束幀。
在 LAVE 系統中,每個縮略圖幀代表剪輯中一秒鐘的素材。與視頻庫一樣,每個剪輯的標題和描述都會提供。LAVE 中的剪輯時間軸具有兩個關鍵功能,即剪輯排序和修剪。
其中在時間軸上進行剪輯排序是視頻剪輯中的一項常見任務,對於創建連貫的敘述非常重要。LAVE 支持兩種排序方法,一是基於 LLM 的排序利用視頻剪輯智能體的故事板功能進行操作,二是手動排序通過用戶直接操作來排序,拖放每個視頻框來設置剪輯出現的順序。
修剪在視頻剪輯中也很重要,可以突出显示關鍵片段並刪除多餘內容。在修剪時,用戶雙擊時間軸中的剪輯,打開一個显示一秒幀的彈出窗口,如下圖 4 所示。

視頻剪輯智能體
LAVE 的視頻剪輯智能體是一個基於聊天的組件,可促進用戶和基於 LLM 的智能體之間的交互。與命令行工具不同,用戶可以使用自由格式的語言與智能體進行交互。該智能體利用 LLM 的語言智能提供視頻剪輯輔助,並提供具體的響應,以在整個編輯過程中指導和幫助用戶。LAVE 的智能體協助功能是通過智能體操作提供的,每個智能體操作都涉及執行系統支持的編輯功能。
總的來說,LAVE 提供的功能涵蓋了從構思和預先規劃到實際編輯操作的整個工作流程,但該系統並沒有強制規定嚴格的工作流程。用戶可以靈活地利用與其編輯目標相符的功能子集。例如,具有清晰編輯願景和明確故事情節的用戶可能會繞過構思階段並直接投入編輯。
後端系統
該研究採用 OpenAI 的 GPT-4 來闡述 LAVE 後端系統的設計,主要包括智能體設計、實現由 LLM 驅動的編輯功能兩個方面。
智能體設計
該研究利用 LLM(即 GPT-4)的多種語言能力(包括推理、規劃和講故事)構建了 LAVE 智能體。
LAVE 智能體有兩種狀態:規劃和執行。這種設置有兩個主要好處:
- 允許用戶設置包含多個操作的高級目標,從而無需像傳統命令行工具那樣詳細說明每個單獨的操作。
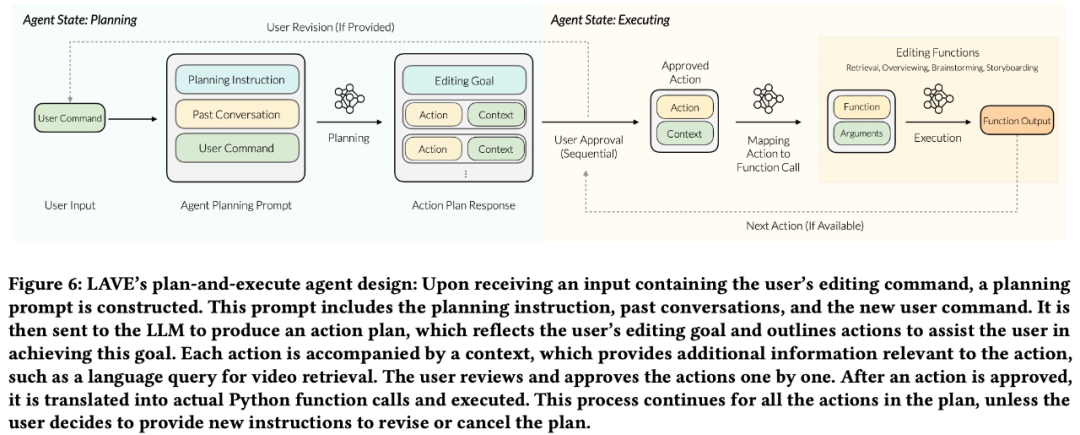
- 在執行之前,智能體會將規劃呈現給用戶,提供修改的機會並確保用戶可以完全控制智能體的操作。研究團隊設計了一個後端 pipeline 來完成規劃和執行流程。
如下圖 6 所示,該 pipeline 首先根據用戶輸入創建行動規劃。然後,該規劃從文本描述轉換為函數調用,隨後執行相應的函數。
實現 LLM 驅動的編輯功能
為了幫助用戶完成視頻編輯任務,LAVE 主要支持五種由 LLM 驅動的功能,包括:
- 素材概述
- 創意頭腦風暴
- 視頻檢索
- 故事板
- 剪輯修剪
其中前四個可通過智能體來訪問(圖 5),而剪輯修剪功能可通過雙擊時間軸中的剪輯,打開一個显示一秒幀的彈出窗口(圖 4)。

其中,基於語言的視頻檢索是通過向量存儲數據庫實現的,其餘的則通過 LLM 提示工程(prompt engineering)來實現。所有功能都建立在自動生成的原始素材語言描述之上,包括視頻庫中每個剪輯的標題和摘要(圖 3)。研究團隊將這些視頻的文字描述稱為視覺敘述(visual narration)。