所有語言











分享
模型上下文長度達到10000000,又一批創業者完蛋了?
巴比特_硅星人319天前
文章來源:硅星人Pro
作者:油醋

圖片來源:由無界AI生成
沒有疑問,Gemini 1.5 Pro的隆重推出被Sora搶了風頭。
社交平台X上OpenAI介紹Sora的第一條動態,現在已經被瀏覽了超過9000萬次,而關於Gemini 1.5 Pro熱度最高的一條,來自谷歌首席科學家Jeff Dean,區區123萬人。
或許Jeff Dean自己也覺得鬱悶。Gemini 1.5 Pro和Sora共同發布的一周后,他在X上點贊了沃頓商學院副教授Ethan Mollick認為人們對大模型的注意力發生了偏差的觀點。
Ethan Mollick幾乎是教育界最早公開推崇生成式AI的人之一,他在2023年2月公開呼籲學生應該都應該開始用ChatGPT寫論文。而這一次他的觀點是,考慮到大模型在圖像生成方面所體現出的有限價值,它實在是引起了過多的討論了。
“對於大模型的實驗室來說,圖像生成更像是一個聚會上的節目......做為內核的LLM才是價值所在。但社交媒體更樂於分享照片。”
——沒說的是,社交媒體也更樂於分享Gif,以及視頻。
人類是視覺動物,所以Sora才會這麼搶眼。或許我們太高估了Sora,又太忽視了Gemini 1.5 Pro。
Gemini 1.5 Pro展現出的眾多能力中有一點很特殊,它已經是一個具備處理視頻語料輸入的多模態大模型。Sora能將文字擴展成視頻,Gemini 1.5 Pro的野心是把理解視頻的能力開放出來。在對模型能力的考驗上,很難說後者就弱於前者。
這背後的基礎性工作在上下文輸入長度上。Gemini 1.5 Pro的上下文長度達到1M Token,這意味着一小時的視頻、3萬行代碼或者JK·羅琳把小說從《哈利波特與魔法石》寫到《哈利波特與鳳凰社》,遠高於包括GPT、Claude系列在內的目前市面上所有的大模型。而谷歌甚至透露,1M Token並不是極限,谷歌內部已經成功測試了高達10M Token的輸入,也就是說,它已經能一口氣看完9個小時的《指環王》三部曲。
上下文長度抵達10M Token到底意味着什麼,等到Sora帶來的激情稍褪,人們逐漸回過味兒來。
X、Reddit......越來越多的討論場開始關注到10M Token所展現出的可能性,其中最大的爭議在於,它是否“殺死”了RAG(Retrieval Augment Generation,檢索增強生成)。
大模型從概念走向商業應用的過程中,本身的問題逐漸暴露,RAG開始成為貫穿整個2023年最火熱的技術名詞。
一個被普遍接受的描述框架給這項技術找到了最精準的定位。如果將整個AI看作一台新的計算機,LLM就是CPU,上下文窗口是內存,RAG技術是外掛的硬盤。RAG的責任是降低幻覺,並且提升這台“新計算機”的實效性和數據訪問權限。
但本質上這是因為這台“新計算機”仍然又笨又貴,它需要更多腦容量、需要了解更具專業性的知識,同時最好不要亂動昂貴又玻璃心的那顆CPU。RAG某種程度上是為了生成式AI能夠儘早進入應用層面的權宜之計。
10M Token的上下文輸入上限,意味着很多RAG要解決的問題不成問題了,然後一些更激進的觀點出現了。
曾構建了評測基準C-EVAL的付堯認為,10M Token殺死了RAG——或者更心平氣和的說法是,長文本最終會取代RAG。
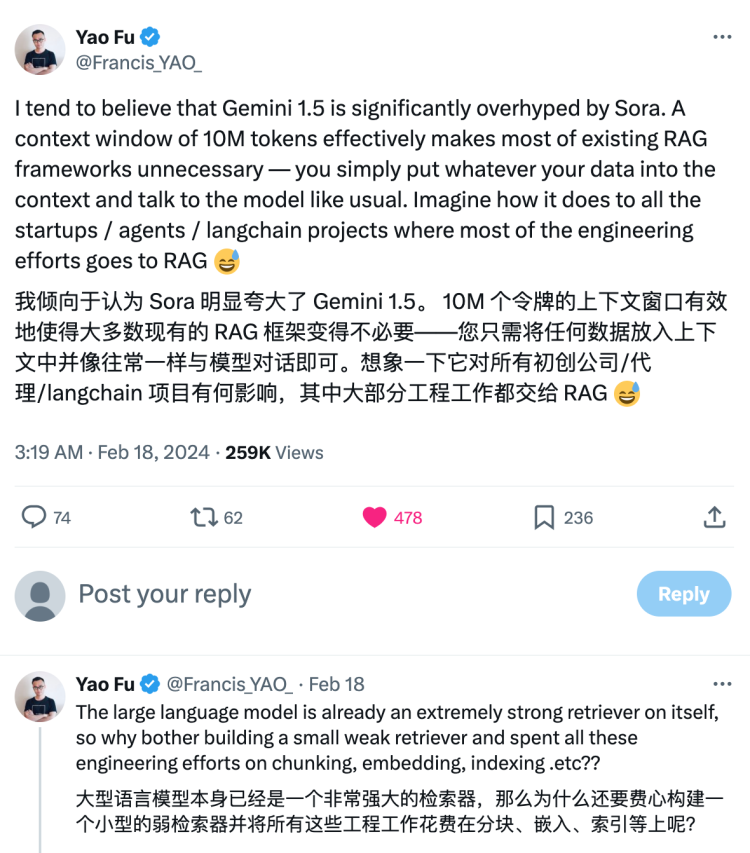
這個觀點引發了巨大討論,他也隨後對這個看起來“暴論”式的判斷所引發的反對觀點做了進一步解釋,值得一看。
其中最重要的,是長文本相比於RAG在解碼過程中檢索上的優越性:
“RAG只在最開始進行檢索。通常,給定一個問題,RAG會檢索與該問題相關的段落,然後生成。長上下文對每一層和每個Token進行檢索。在許多情況下,模型需要進行即時的每個Token的交錯檢索和推理,並且只有在獲得第一個推理步驟的結果后才知道要檢索什麼。只有長上下文才能處理這種情況。
針對RAG支持1B級別的Token,而目前Gemini 1.5 pro支持的上下文長度是1M的問題:
“確實如此,但輸入文檔存在自然分佈,我傾向於相信大多數需要檢索的案例都在百萬級以下。例如,想象一個處理案例的層,其輸入是相關的法律文件,或者一個學習機器學習的學生,其輸入是三本機器學習書籍——感覺不像1B那麼長,對嗎?”
“大內存的發展並不意味着硬盤的淘汰。”有人持更溫和的觀點。
出於成本和效率上的考慮,超長文本輸入在這兩方面顯然並不成熟。因此哪怕面對10M Token的上下文輸入上限,RAG仍然是必須的,就像我們時至今日仍然沒有淘汰掉硬盤。

如果將上下文的窗口設定為1M,按現在0.0015美元/1000token的收費標準,一次請求就要花掉1.5美元,這麼高的成本顯然是無法實現日常使用的。
時間成本上,1M的上下文長度在Gemini 1.5 Pro的演示實例中,需要60秒來完成結果的輸出——但RAG幾乎是實時的。
付堯的觀點更傾向於——“貴的東西,缺點只有貴”。
“RAG 很便宜,長上下文很昂貴。確實如此,但請記住,與 LLM 相比,BERT-small 也便宜,n-gram 更便宜,但今天我們已經不使用它們,因為我們希望模型首先變得智能,然後再變得智能模型更便宜。
——人工智能的歷史告訴我們,讓智能模型變得更便宜比讓廉價模型變得智能要容易得多——當它很便宜時,它就永遠不會智能。”
一位開發者的觀點代表了很多對這一切感到興奮的技術人員:在這樣一場技術革命的早期階段,浪費一點時間可能也沒有那麼要緊。
“假設我花了5分鐘或1小時(見鬼,即使花了一整天)才將我的整個代碼庫放入聊天的上下文窗口中。如果在那之後,人工智能能夠像谷歌聲稱的那樣,在剩下的對話中近乎完美地訪問該上下文,我會高興、耐心和感激地等待這段時間。”這位在一家数字產品設計公司中供職的博客作者里這樣寫道。
在這位開發者發布這條博客之前,CognosysAi的聯創Sully Omarr剛剛往Gemini 1.5 Pro的窗口裡塞進去一整個代碼庫,並且發現它被完全理解了,甚至Gemini 1.5 Pro辨別出了代碼庫中的問題並且實施了修復。
“這改變了一切。”Sully Omarr在X上感嘆。
被改變的可能也包括與Langchain相關的一切。一位開發者引用了Sully Omarr的話,暗示Langchain甚至所有中間層玩家即將面臨威脅。
向量數據庫可能突然之間就變成了一個偽需求——客戶直接把特定領域的知識一股腦兒扔進對話窗口就好了,為什麼要僱人花時間來做多餘的整理工作呢(並且人腦對信息的整理能力也比不過優秀的LLM)?
付堯的預測與這位開發者相似,甚至更具體——以Langchain 、LLaMA index這類框架作為技術棧的初創公司,會在2025年迎來終結。
但必須強調的是,付堯對於RAG的判斷和解釋弱化了在成本和響應速度上的考慮,原因或許是他正在為谷歌工作,而這兩點仍然是讓在當下RAG具備高價值的決定性因素。而如果看向這場上下文長度的討論背後,谷歌在這場競爭中最大的優勢開始展現出來了。
他擁有目前這個行業里最多的計算能力。換句話說,對於上下文長度極限的探索,目前只有谷歌能做,它也拿出來了。
從2014年至今,谷歌已經構建了6種不同的TPU芯片。雖然單體性能仍然與H100差距明顯,但TPU更貼合谷歌自己生態內的系統。去年8月,SemiAnalysis的兩位分析師Dylan Patel和Daniel Nishball揭露谷歌在大模型研发上的進展時表示,⾕歌模型FLOPS利⽤率在上一代TPU產品TPUv4上已經⾮常好,遠超GPT-4。
目前谷歌最新的TPU產品是TPUv5e。兩位分析師的調查显示,谷歌掌握的TPUv5e數量比OpenAI、Meta、CoreWeave、甲骨文和亞馬遜擁有的GPU總和更多。文章里稱TPUv5e將會用到谷歌最新的大模型(即是後來發布的Gemini系列)訓練上,算力高達1e26 FLOPS,是GPT-4的5倍。

這個猜測在谷歌最新開源的Gemma身上得到了佐證。Gemma是Gemini的輕量化版本,兩者共享相同的基礎框架和相關技術,而在Gemma放出的技術報告中表明,其訓練已經完全基於TPUv5e。
這也不難理解為何奧特曼要花7萬億美元為新的算力需求未雨綢膜。雖然OpenAI擁有的總GPU數量在2年內增長了4倍。
“"In our research, we’ve also successfully tested up to 10 million tokens."(在研究中,我們也成功測試了多達10M Token)”
這被Sora暫時掩蓋住的一次嘗試或許在未來會作為生成式AI上的一個重要時刻被反覆提及,它現在也真正讓發明了transformer框架的谷歌,回歸到這場本該由自己引領的競爭中了。