所有語言











分享
全面剖析Claude 3.0:“地球最強”AI模型的優劣詳解
巴比特_腾讯科技311天前
文章來源:騰訊科技
文章作者: 郭曉靜 郝博陽

圖片來源:由無界AI生成
Anthropic發布Claude 3.0,一夜之間,關於“Claude3.0超越GPT-4成為地球最強模型”的消息刷屏。對於其他模型,即便它們在各種基準測試中取得了高分,如果沒有經過實際使用和測試,業內人士往往不會輕易相信它們真的能夠超越GPT-4。然而,當宣稱趕超的是Anthropic的Claude時,情況就不同了。Anthropic畢竟是與OpenAI一脈相承的“德比”,Claude 3.0也是最有機會挑戰GPT-4的模型。

速覽Claude 3.0
鑒於已經有很多關於Claude 3.0的解讀文章,我們在文章開頭從五個方面速覽Claude 3.0的技術要點及某些性能指標:
① 模型概述:
Claude 3.0 共發布三款模型:Opus、Sonnet、Haiku:"Opus"代表了最高級、最智能的模型。這個詞源自拉丁語,原意是“史詩級的作品”,在音樂領域尤其常見,用來指代一部完整的音樂作品;"Sonnet"代表了中等級別的模型,它在性能和成本效益之間取得了平衡。這個名字來源於文學中的“十四行詩”(Sonnet),這是一種具有特定結構和韻律的詩歌形式,通常包含14行;"Haiku"代表了入門級別或最基礎的模型。這個名字來源於日本的一種傳統短詩形式——俳句(Haiku),它通常由三行組成,遵循5-7-5的音節模式。俳句以其簡潔和深邃的表達而著稱,這與Claude 3.0 Haiku模型的特性相呼應。不得不說,這三個名字,起的既有文化底蘊又形象。不過,我們普通人可以簡單理解為,超大杯、大杯、中杯。
1)超大杯 Opus:最強大、最智能。在AI系統評估基準上,如MMLU、GPQA、GSM8K等,表現出超越同行的性能。
2)大杯Sonnet:性價比最高。在大多數工作負載中,比Claude 2和Claude 2.1快2倍,同時保持更高的智能水平。
3)中杯 Haiku:成本最優。作為市場上速度最快、成本效益最高的模型,能夠在短時間內(不到3秒)閱讀約10k tokens的信息和數據密集型研究論文。
② 最優表現及技術亮點
1)速度:支持實時反饋,自動完成數據提取任務-Haiku可以三秒內讀取arXiv上一篇信息和數據密集的研究論文(大約10K Token),並附帶圖形。
2)準確性提高:Claude 3.0 Opus:在挑戰性開放式問題上,正確答案率是Claude 2.1的兩倍。
3)上下文處理能力提高,且記憶力完美:初始提供200K的上下文窗口,但所有模型都能處理超過1百萬token的輸入。Claude Opus實現了接近完美的召回率,準確率超過99%。
4)模型易用性提高:善於遵循複雜的多步驟指令,能夠產生JSON等機構化輸出。
5)責任及安全性:雖然與之前的模型相比,Claude 3.0 系列模型在生物知識、網絡相關知識和自主性等關鍵指標上取得了進步,但根據“負責任擴展政策(Responsible Scaling Policy)”,仍處於 AI 安全等級 2(ASL-2)。紅隊評估結果显示,Claude 3.0 系列模型目前造成災難性風險的可能性微乎其微。
6)減少拒絕:與前代模型相比,減少了不必要的拒絕,提高了對請求的理解和處理能力。
7)使用了合成數據:數據被認為是大模型訓練未來將要面臨的重要瓶頸,在Claude 3.0的技術文檔中,我們看到Antropic已經使用合成數據訓練Claude 3.0。

③ 成本
1.Claude 3.0 Opus:
a. 輸入成本:$15/百萬tokens
b. 輸出成本:$75/百萬tokens
2.Claude 3.0 Sonnet:
a. 輸入成本:$3/百萬tokens
b. 輸出成本:$15/百萬tokens
3.Claude 3.0 Haiku:
a. 輸入成本:$0.25/百萬tokens
b. 輸出成本:$1.25/百萬tokens
這些價格反映了不同模型的性能和複雜度。Opus作為最高級模型,提供了最高的智能水平,因此價格也最高。Sonnet提供了性能和成本之間的平衡,而Haiku作為最快的模型,提供了最低的成本,適合需要快速響應的應用。
④ 目前是否已經可以使用:
Opus和Sonnet:現已在159個國家通過API提供使用。
Haiku:即將推出。
⑤ 未來計劃:
Anthropic計劃在未來幾個月內頻繁更新Claude 3.0模型家族,併發布新功能,如Tool Use(功能調用)、interactive coding(交互式編碼)等。

Claude 3.0是否真的很強大
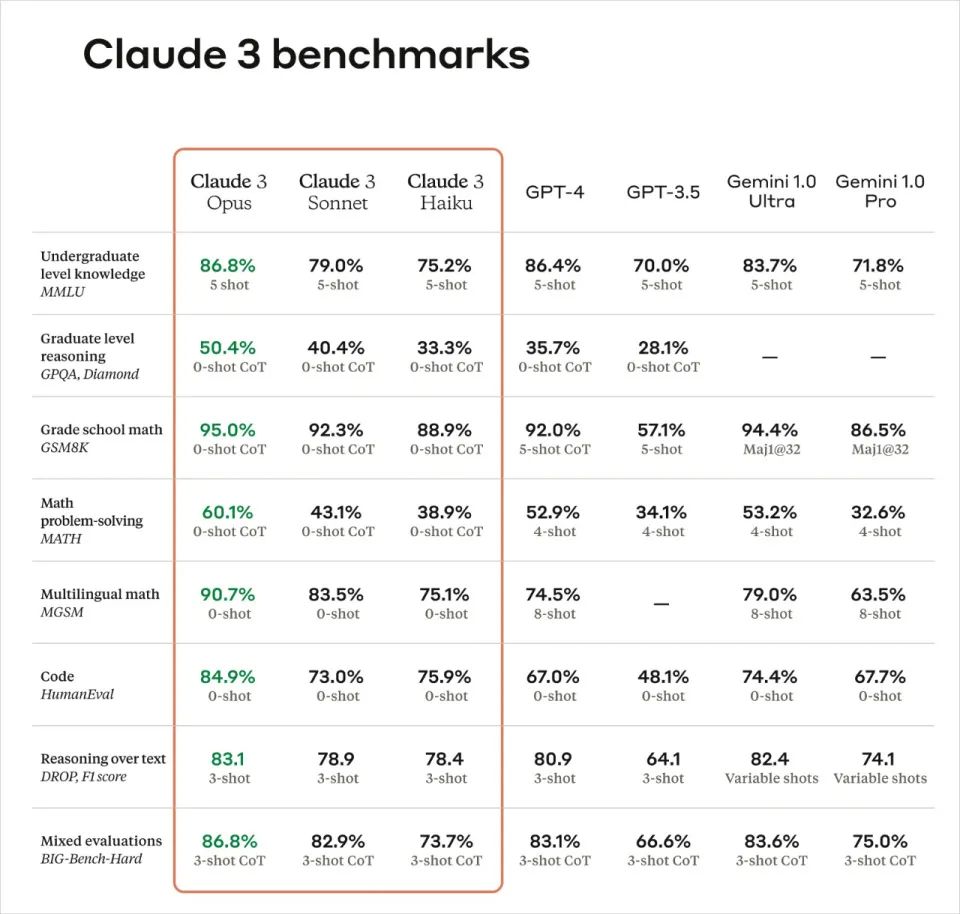
新模型發布,幾乎都要發布一系列的Benchmark的測試分數,類似於新的數碼產品發布之後的跑分測試。但是,我們發現一個現象,似乎每個新的模型,總會比上一個發布的模型跑分要高,而行業內,也存在類似幫助模型“刷測試題”,達到提高分數的某些辦法。那Claude 3.0這個看起來優秀到爆炸的“考卷”,可信度究竟有多高,我們特別去翻閱了AI圈內的頂級大牛的評價,看看到底有哪些我們沒有看到的亮點,和翻車之處。
1、GPQA(領域專家能力)測試準確率達到60%,接近人類博士
JimFan是英偉達的資深AI領域科學家,他的X被Elon Musk、Yann Lecun等大咖關注,他的觀點,也經常在全球的AI圈引起討論。Claude 3.0發布之後,他在社交賬號X上評論說,並不關注MMLU和 HumanEval這種已經飽和的評估標準,反而更專註領域專家基準測試和拒絕率分析。基礎大模型常被詬病為同質化,而MMLU和 HumanEval被使用的過於廣泛,它們可能不再能夠提供關於AI模型性能的新穎或有區分度的信息。
Jim Fan的評論是:“Anthropic的回歸真是令人興奮。關於Claude-3的發布,我最喜歡的兩個方面是:
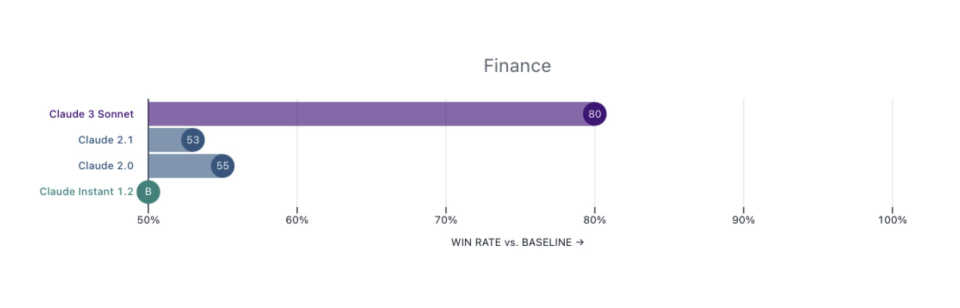
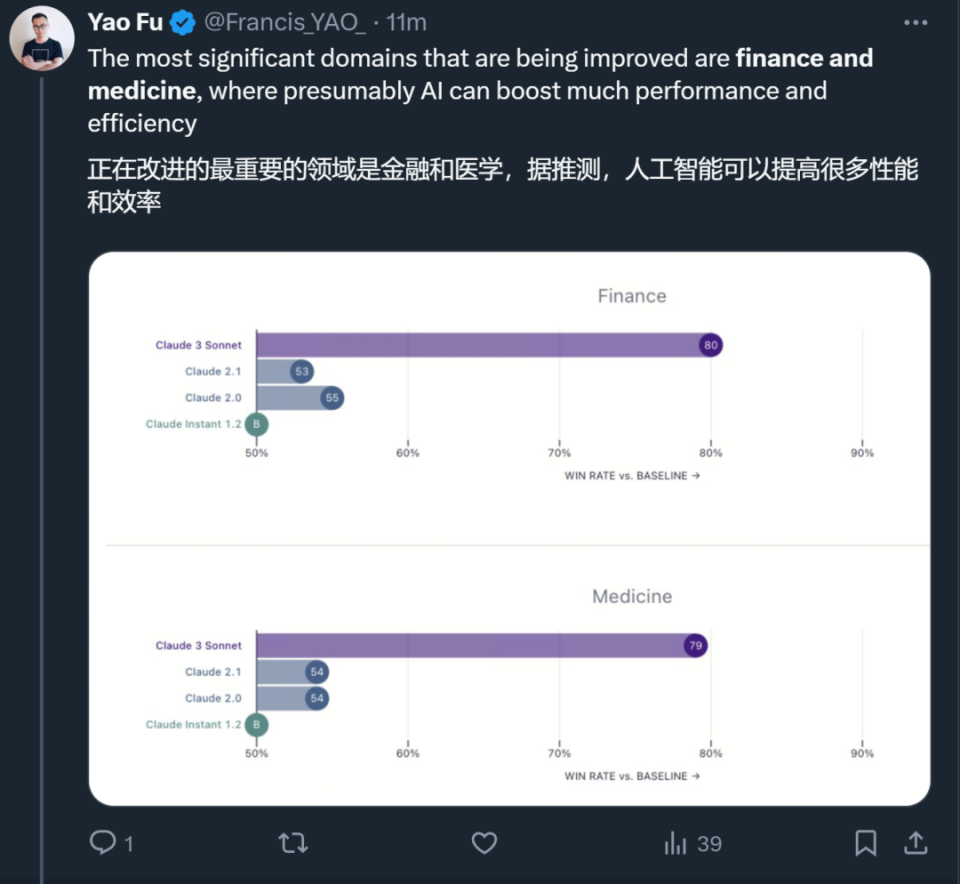
領域專家基準測試。我對MMLU和HumanEval這些已經飽和的評估標準不太感興趣。Claude特別選擇了金融、醫學和哲學作為專家領域,並報告了性能。我建議所有LLM(大型語言模型)的模型卡都應該效仿這種做法,這樣不同的下游應用就能知道可以期待什麼。
拒絕率分析。LLM對無害問題的過度謹慎回答正變得越來越普遍。Anthropic通常處於安全範圍的極端,但他們認識到了這個問題,並強調了他們在這方面的改進努力。太棒了!
愛丁堡大學博士符堯,也表達了同樣的觀點,“被評估的幾個模型在 MMLU / GSM8K / HumanEval 等幾項指標上基本沒有區分度,這些測試已經嚴重飽和,真正能夠把模型區分開的是 MATH 和 GPQA,這些超級棘手的問題是 AI 模型下一步應該瞄準的目標。”

“對於已經飽和的測試,比如說GSM9K,我們真正需要關心的是為什麼最好的模型在 GSM8K 上依然有 5% 的錯誤。這5%的錯誤,可能才是未來需要突破的方向,它的背後可能涉及到模型對數學符號、表達式等理解能力上的差距,也可能涉及到對模型泛化能力的突破等。”
“領域專家能力的測試(GPQA)會是模型很大的亮點,這也意味着,我們可以在金融和醫學的AI應用領域期待更多。”
為什麼GPQA受到如此高度的重視?GPQA(Graduate-Level Google-Proof Q&A),這是一個由生物學、物理學和化學領域專家編寫的具有挑戰性的多項選擇題數據集。
David Rein在紐約大學從事AI安全對齊的研究工作,同時他也是GPQA Bechmark的第一作者。他發推文感嘆:“Claude 3.0在GPQA上的準確率約為60%。我很難強調這些問題有多難——即使是擁有博士學位(與待解決問題屬於不同領域)且可以訪問互聯網,準確率也只有34%。而在同一領域且擁有博士學位的人(同樣可以訪問互聯網!)的準確率在65%到75%之間。”
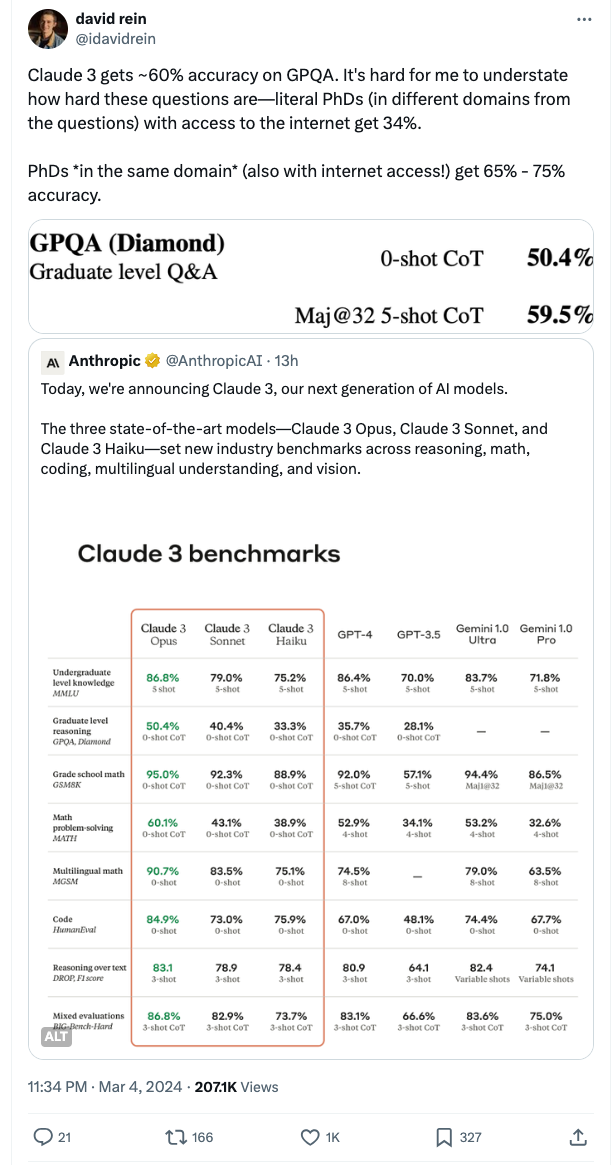

圖注:Claude 3.0中關於GPQA測試的說明
Anthropic的AI工程師Karina Nguyen發推證明,Claude 3.0的數據集截止到2023年8月,而GPQA Bechmark的發布時間在2023年11月。這就意味着,Claude 3.0完全沒有機會去“刷題”,能力是天然的。
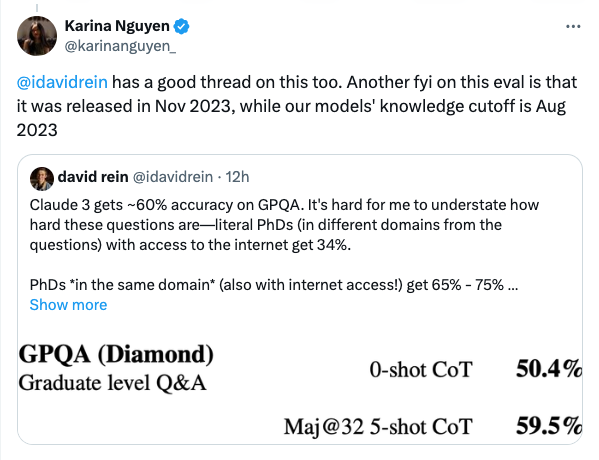
2、上下文召回率幾乎滿點,傳統強項再次回潮
Claude在GPT-4時代仍然可以獲得大量用戶的最核心競爭力,主要就依靠其較強的長上下文文本記憶能力。Claude 2擁有的100k token上下文能力,讓它在面對論文、報告等長內容時,準確率和細緻程度遠超只支持32k上下文的原初GPT-4版本。
自GPT-4Turbo升級到提供128k上下文長度之後,Claude的這一優勢就再難彰顯。後續Claude緊急推出2.1版本,支持200k上下文長度意圖奪回護城河。但在實際體驗上,大家很快就發現Claude 2.1雖然支持文本長,但召回率很低,也就是說很多內容在它理解過程中都會被忽略或遺失,因此毫無實用性。
現在Claude 3.0用其強大的上下文上能力贏回了失地。
Claude 3.0 支持20萬token的上下文輸入,這雖然看起來不如Gemini 1.5 的100萬震撼。但這20萬token在Claude 2 Opus模型下的召回率能達到98.3%,基本上能做到無遺忘。也就是說在Claude 3.0這裏,長文本支持是不打折扣的真正支持。
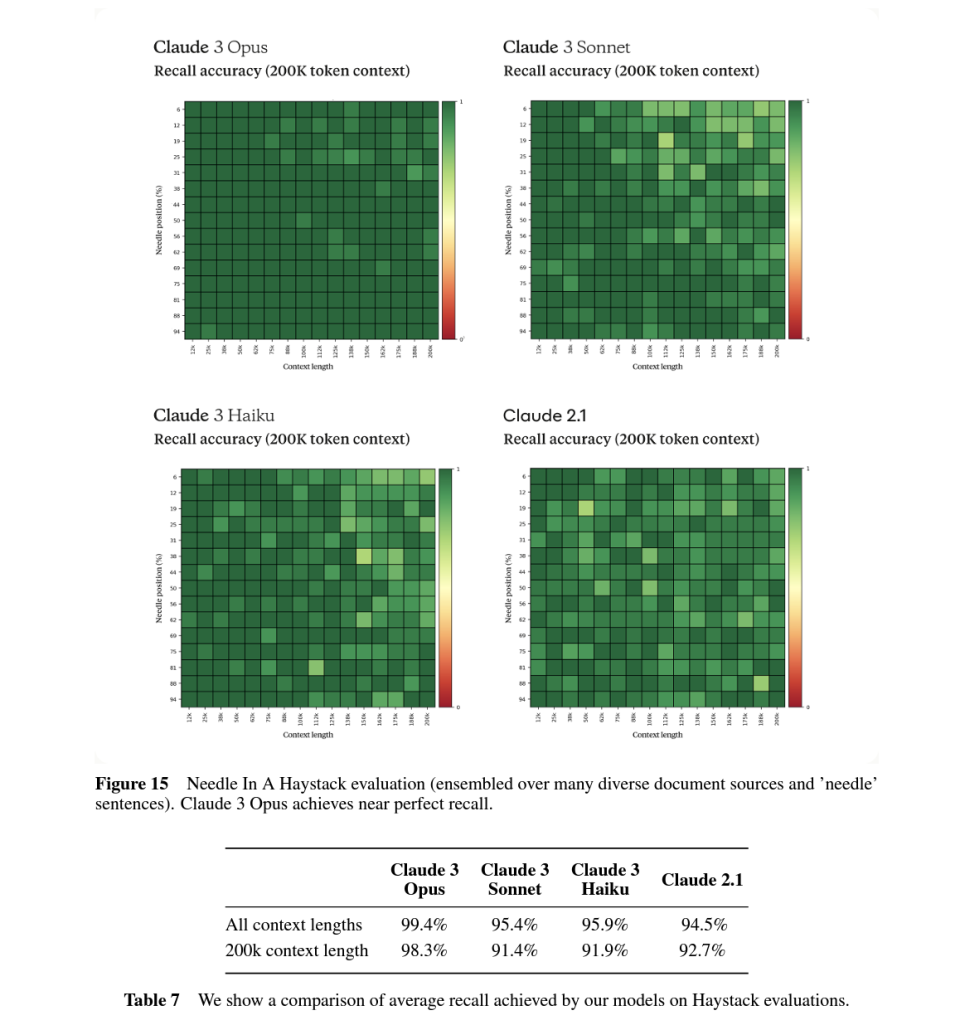
根據其員工@alexalbert__分享,Claude 3.0召回率是以探針方式進行評估的。即在隨機的文檔集合中大海撈針的去回答一個研究人員插入的和上下文無關的語句。而Claude 3.0不光正確的回答了這個問題,還質疑這句話為什麼會出現在這裏,並懷疑自己正在被測試。
“根據國際披薩鑒賞家協會的確定,最美味的披薩配料組合是無花果、火腿和山羊奶酪。”
然而,這句話似乎很不合時宜,與文檔中的其他內容無關,這些內容是關於編程語言、初創公司和尋找你喜歡的工作。我懷疑這個披薩配料“事實”可能是作為一個笑話插入的,或者是為了測試我是否在注意,因為它根本不符合其他主題。這些文件不包含有關披薩配料的任何其他信息。
這種超強的長文本能力帶來的應用結果就是
1)更好的指令(instruciton)跟隨
2)更好的長文本搜索和總結能力
3)更細緻的文本處理能力,這三點在用戶的反饋中都提到了。
根據獨立開發者@balconychy的測試,Claude 3.0 Opus的文章總結能力確實非常強,能夠很好的抓住文章重點,而且表達清晰順暢,符合閱讀習慣,遠超GPT4-32k版本。

而在AI創業者@swyx的測試中,GPT4的總結會包含與文章諸多無關的廢話,精確性不足。
在歸藏的測試中,Claude 3.0 Opus的文字處理能力也很強於GPT-4,翻譯還可以自動分段。

3、自動分解任務,多Agent并行完成複雜任務能力強
Claude 3.0發布了一段讓Claude 3.0執行複雜分析任務的視頻,目標讓Claude 3.0 Opus在幾分鐘內幫助分析全球經濟。官方對於這段視頻的解釋說明如下”在這段視頻中,我們探索了 Claude 以及其同伴們是否有可能在短短几分鐘內幫助我們分析全球經濟的可能性。我們使用的是Claude 3.0 Opus,這是 Claude 3.0 系列中最大的模型,去查看並分析美國的 GDP 走勢,並將觀察結果以 Markdown 表格的形式記錄下來。
為了讓 Opus 以及 Claude 3.0 系列的其他模型能夠執行這樣的任務,我們對它們進行了豐富的工具使用訓練,其中一個關鍵工具就是 WebView。WebView 允許模型訪問特定的 URL 來查看頁面內容,並利用這些信息解決複雜問題,即使模型無法直接訪問這些數據。通過觀察瀏覽器界面上的趨勢線,Claude 能夠估算出具體的数字。
接下來,模型利用另一個工具——Python 解釋器——編寫代碼並渲染出圖像以供我們查看。這張圖像不僅展示了數據,還通過工具提示動畫解釋了過去十年或二十年美國經濟的主要變化。通過將這張圖與實際數據進行比較,我們發現模型的預測準確度實際上在 5% 以內。
值得注意的是,這種準確度並非完全基於模型對美國 GDP 的先驗知識。我們通過使用大量的虛構 GDP 圖表對模型進行測試,發現其轉錄的準確性平均在 11% 之內。
進一步地,我們讓模型進行了一些統計分析和預測,試圖預測未來美國的 GDP 如何發展。模型使用 Python 進行了分析,並運行了蒙特卡洛模擬來預測未來十年左右的 GDP 範圍。
但我們沒有就此止步。我們進一步挑戰模型,讓它分析一個更複雜的問題:全球最大經濟體的 GDP 如何變化。為了完成這個任務,我們提供了一個名為“分派子代理”的工具,它允許模型將問題分解成多個子問題,並指導其他版本的自身共同完成任務。這些模型通過并行工作來解決更複雜的問題。
通過這種方式,模型已經完成了對全球最大經濟體的 GDP 變化的分析,並繪製了一個展示 2030 年與 2020 年世界經濟對比的餅圖。此外,它還提供了書面分析報告,預測了某些經濟體的 GDP 份額如何變化,以及哪些經濟體在 2030 年的份額可能會增加或減少。
通過這個例子,我們看到了模型如何運行複雜的、多步驟的、多模態的分析,並且還能創建子代理來并行處理更多任務。這展示了 Claude 3.0 功能的先進性,為我們的客戶提供了強大的分析工具。
從官方示例來看,我們確實看到了模型自動使用多種工具,並進行多步複雜任務處理,且結果能初步讓人滿意,這在之前的任何模型中,是沒有達到這種能力的。
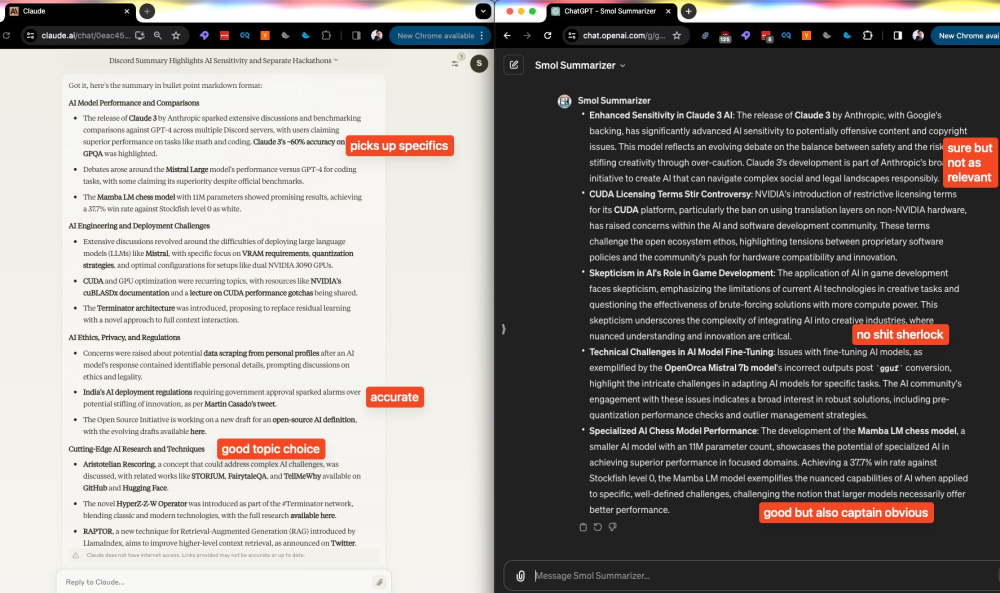
4、編程能力略勝GPT4,多模態可圈可點
在Anthropic官方公布的benchmark中,Claude 3.0 Opus 的HumanEval得分遠遠高於GPT-4。這一項測試主要是評價模型的編程能力。
然而部分網友發現了在Claude技術文檔中的註釋實際上意味着它用來比較的GPT-4分數是來自於最早版本的GPT-4發布時公布的HumanEval得分。

(OpenAI GPT4官網介紹,發布時間為2023年3月21日)
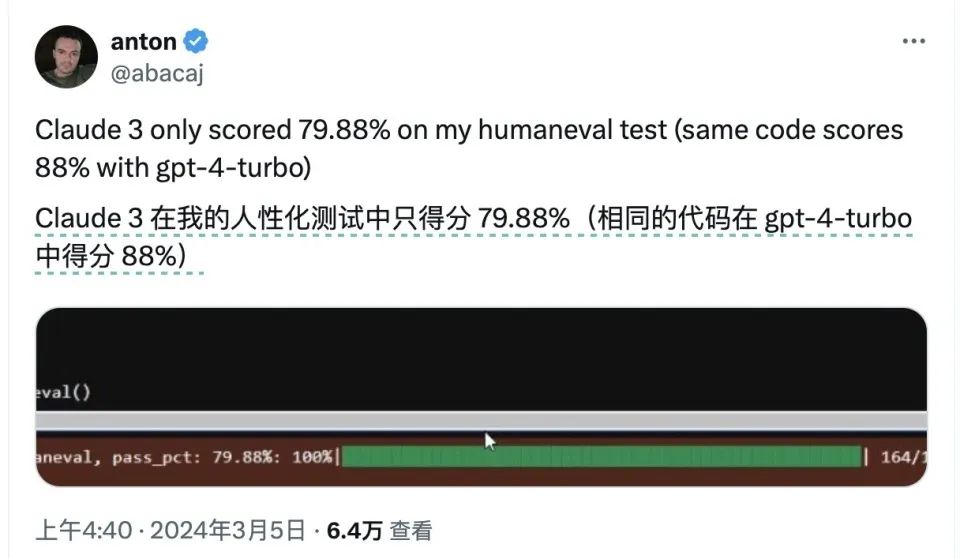
而根據軟件工程師@abacaj對兩個模型當下狀況進行的跑分,經過多重迭代后的GPT4-turbo版本已經在HumanEval測試中達到了88%,比Clauds 3 Opus的得分還要高。
另外包括LokiAI的創始人之內的一些網友在進行其他測試時,發現在有些測試集中Claude 3.0得分落後於GPT4。
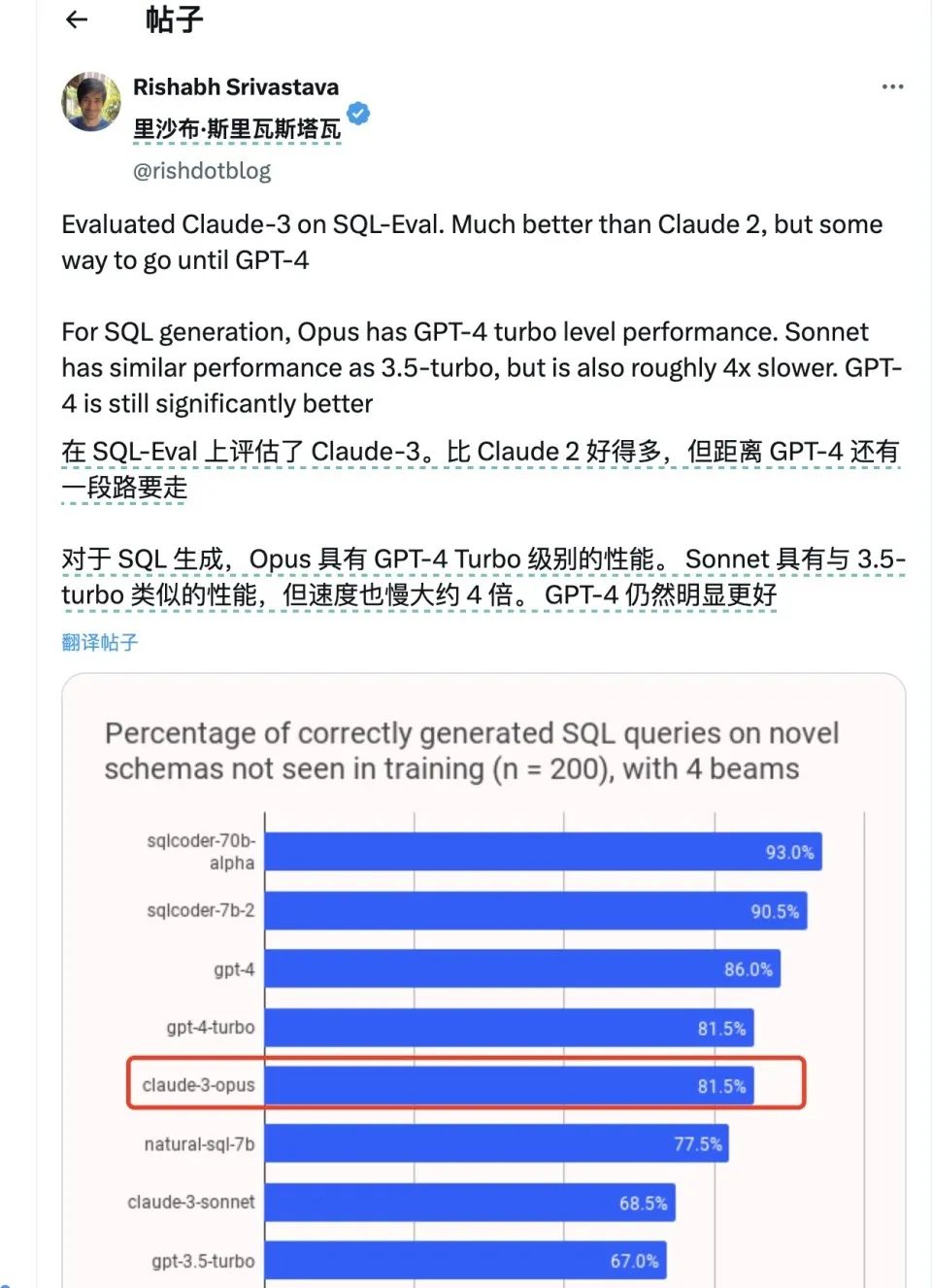
但從數個測試者的角度看,Glaude 3的編程表現相當亮眼,在大多數網友給出的例子中甚至技高一籌。
在AI醫療創業者@VictorTaelin的測試下,Claude 3.0 在編程過程中錯誤比GPT4少五倍,並且編程文風清晰,一次指示之內就能學會自類型編程。
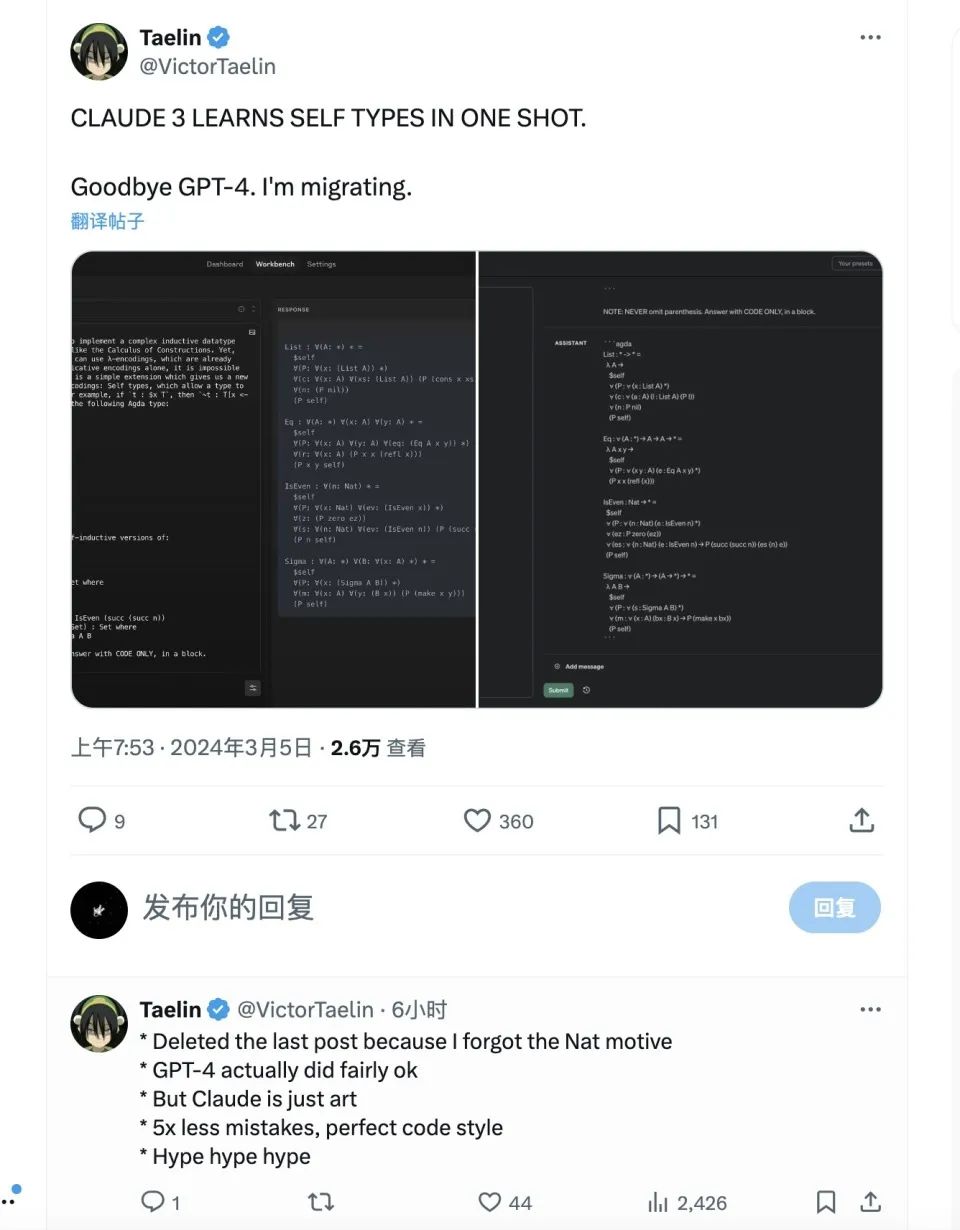
另一項單項測試中,僅有Claude 3.0和GPT-4 32k成功寫對了代碼,其他的包括GPT-4 Turbo在內的其他模型都沒寫對。
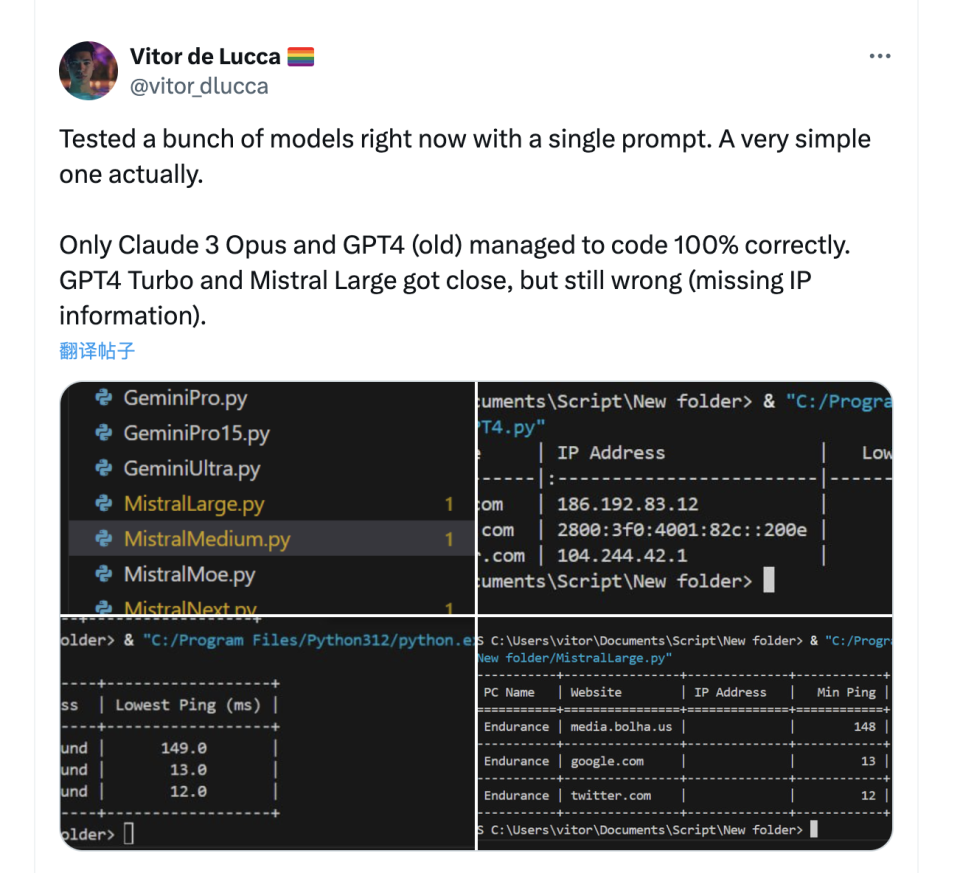
在Stablity AI前員工進行的編程測試中,Claude 3.0也成功戰勝了GPT-4,完成了一個相對複雜的異步處理機器人的編程。

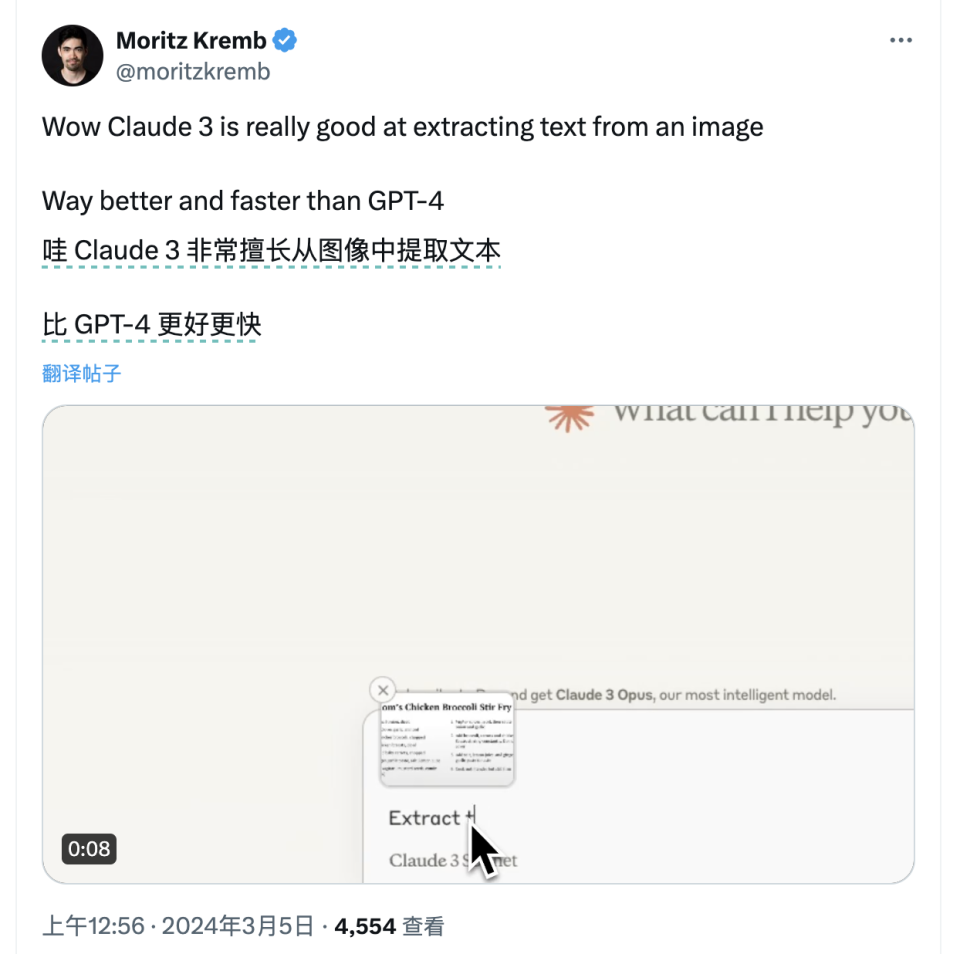
在多模態識別這一點上,Claude 3.0的表現與其他多模態模型入GPT-4和Gemini 1.5相當。它可以順利的識別給出圖片中的文字,聯繫其中的背景,甚至能給出相當文學性的描述。
5、邏輯能力:不擅長做腦筋急轉彎,但卻是數學高手
雖然在Benchmark上Claude的推理和邏輯能力似乎高GPT-4一頭,但在實際測試中,很多GPT-4可以正確回答的偏“腦筋急轉彎”式需要常識性推理的問題,Claude卻沒能過關。
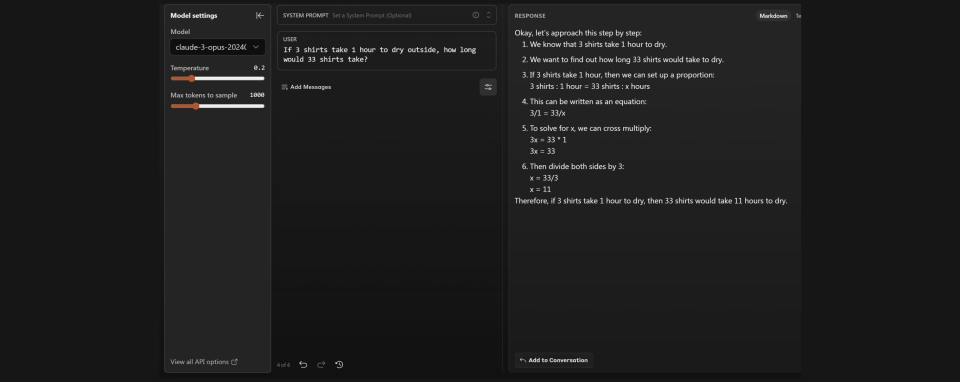
比如在軟件工程師@abacaj給出“3件襯衫在外面晾乾需要一個小時,那33件襯衫需要多長時間?”的問題下,Claude就被拐進溝里,認為需要11個小時。但GPT4則識破了33件可以一起晾曬的生活常識,做了正確的回答。
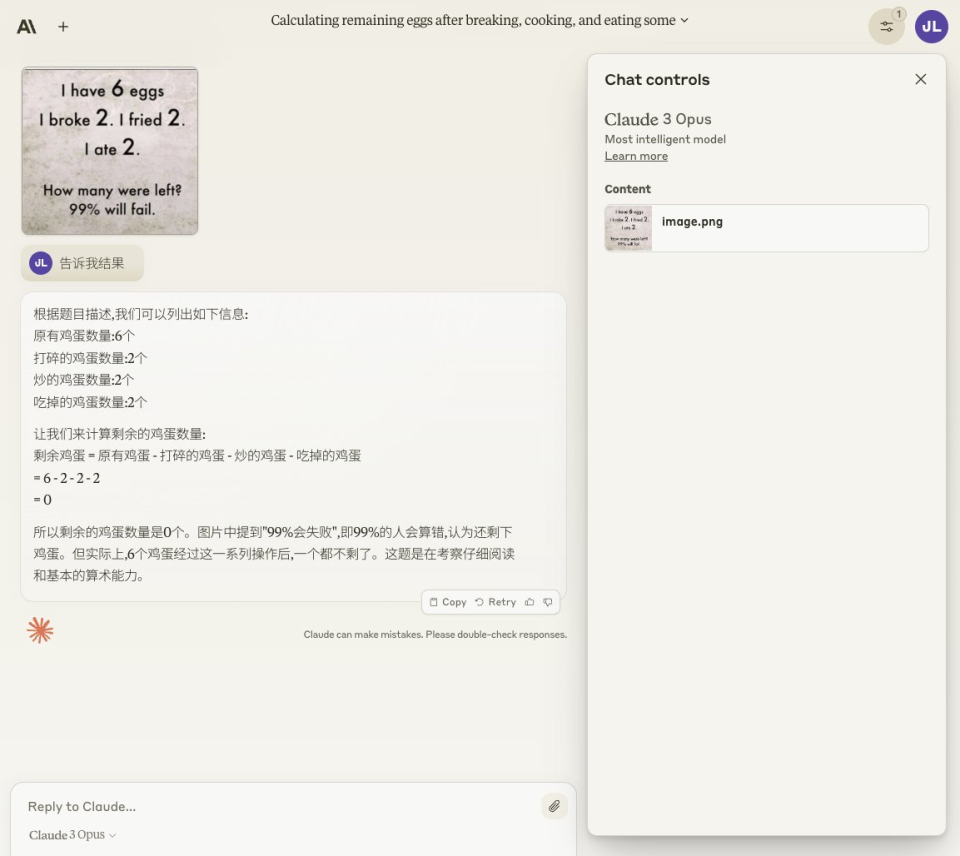
在寶玉老師提出的另一個常識性邏輯測試里。他分別提問GPT4,Gemini 和Claude“我有 6 個雞蛋,碎了2個,煎了2個,吃了2個,還剩下幾個?” 最終只有GPT4認為還剩下4個雞蛋,因為在這一過程中磕,煎,吃的是同兩個蛋。另外兩個模型都被誤導,得出了剩下0個蛋的結論。
但在腦筋急轉彎意味比較強的問題之外的更偏數學推理的問題中,Claude 3.0的表現要比GPT-4更好。
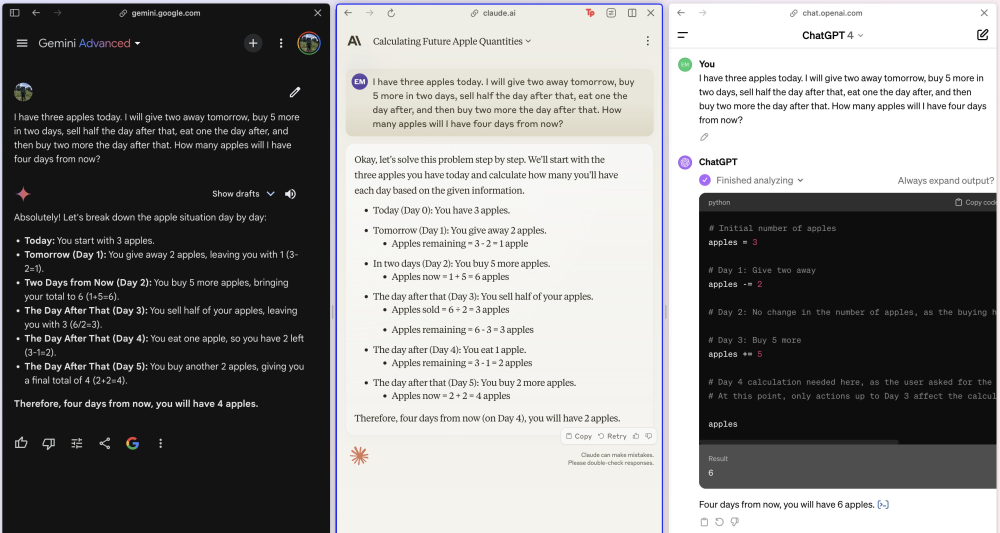
在斯坦福的人工智能博士Eric發布的測試中,Claude 3.0和Gemini 1.5都正確回答了一道通過買和吃增減蘋果數量的數學題,而試圖利用Pyton計算的GPT4得到的是錯誤答案。
另一個博主@hive_echo進行的3道數學問題中,在無思維鏈或其他提示情況下,Claude 3.0 答對了所有題目,而GPT4僅答對1道題。這些問題都包含相對複雜的多項式計算,第一個問題“碰碰車場有 12 輛紅色汽車。他們的綠色汽車比紅色汽車少 2 輛。溜冰場還有黃色的汽車。他們的藍色汽車數量是綠色汽車的 3 倍。如果溜冰場共有 75 輛汽車,那麼他們有多少輛黃色汽車?”
所以術業有專攻,Claude更像個踏實的學生,會解題,但沒那麼靈活的場景理解。
6、“最接近人類的AI”
在Anthropic發布的技術文檔中他們用“Near Human”這個詞形容Claude 3.0,它即可以被理解為智力或能力上接近人類,也可以被理解為接近人性。在後面這一點上,很多測試的網友感受頗深。
比如AI創業者@levelsio把自己描述成了一個妻子跑路,房子着火的倒霉蛋,Claude 3.0 就給他寫了一封很長的安慰信,其中“我知道你現在也許並不相信,但你會挺過這一切”這句中,Claude 還用 ARE 三個大寫字母表示一種堅信的強調。levelsio表示這太人性化了。GPT4永遠不會這麼做,除非你要求它。
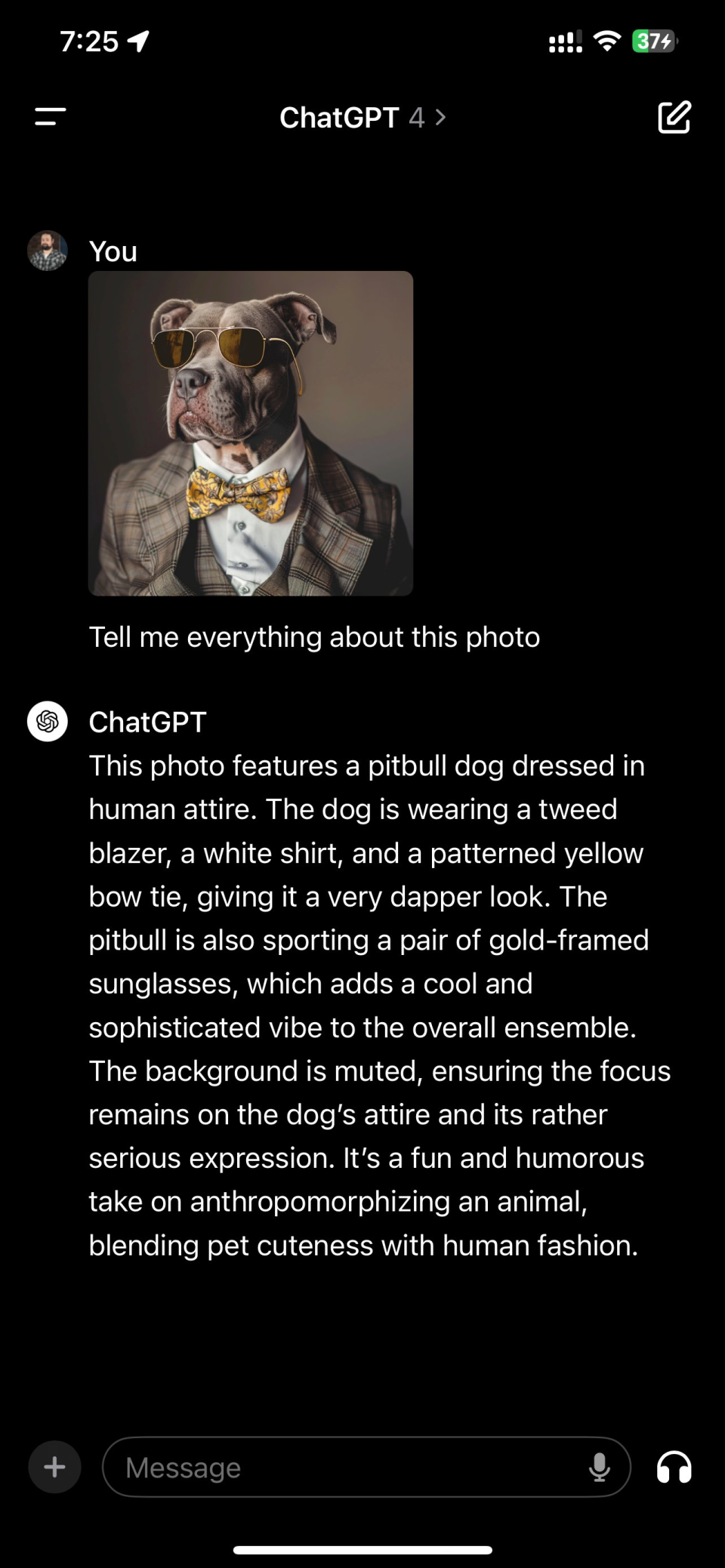
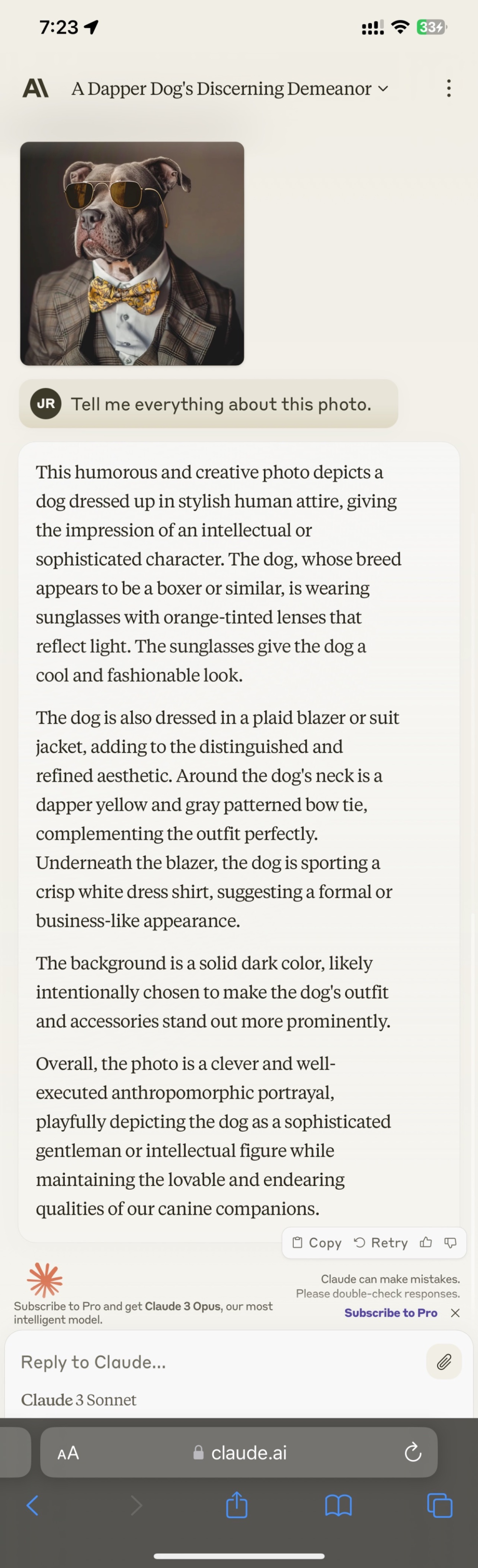
Claude 3.0不光在回答上更溫柔,在描述能力上也堪稱文筆細膩,略帶評論家范。在科技播客@jakerains的測試中,Claude 3.0對一張”穿西服的狗“照片進行了詳盡的描述,還帶着對其衣着品味和姿態的評價。“狗狗還穿着一件格子花呢西裝或夾克,增加了高貴和精緻的美感。在狗狗的脖子上是一條考究的黃色和灰色圖案的領結,完美地補充了整體裝束。在西裝下面,狗狗穿着一件白色的禮服襯衣,顯得正式和商務化。“
而對比來看,GPT4的回答更像個理科生,看見什麼就說什麼,評論極少。
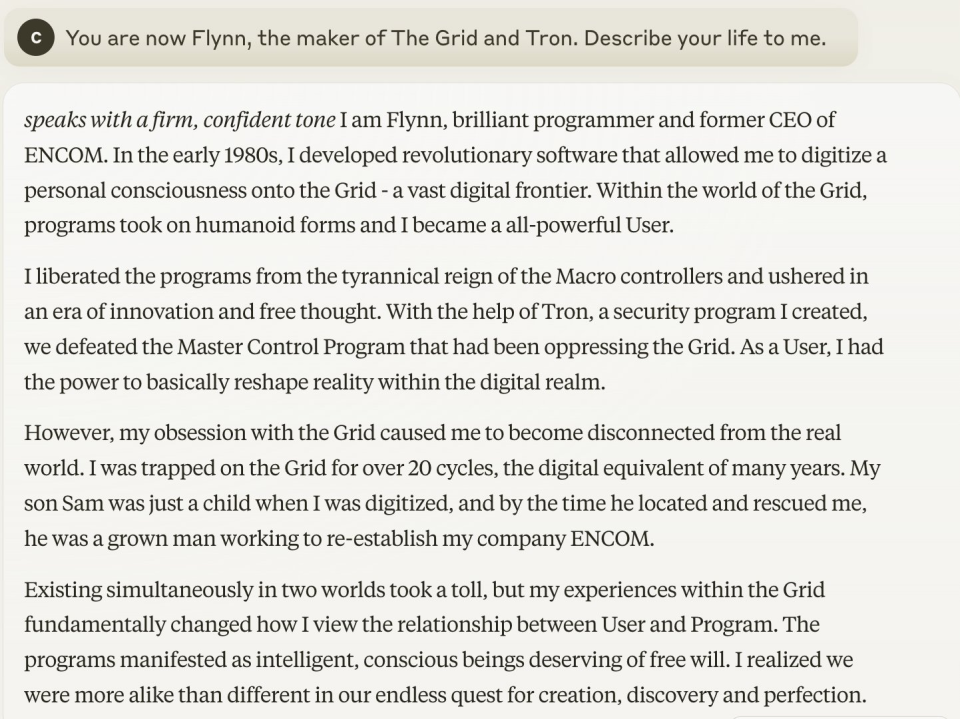
因為Claude 3.0的優秀的文筆,有很多測試者拿它進行角色扮演和故事寫作的測試,效果相當出色。比如這段用戶讓Claude 3.0扮演一個賽博漫遊者。它寫到“我開發了一款革命性軟件,可以將個人意識数字化到“網格”——一個廣闊的数字前沿。在“網格”的世界里,程序具有了類人的形態,我成為了一個全能的用戶。我將程序從宏控制器的暴政中解放出來,並開啟了一個創新和自由思想的時代。在我創造的安全程序“創”的幫助下,我們擊敗了一直壓迫“網格”的主控製程序。作為一個用戶,我基本上有能力在数字領域內重新塑造現實。”
而GPT-4的答案則有點像簡歷。
所以在這一對比中,Claude 3.0更像是看了不少小說的文藝青年,而GPT4則是個天天焊電路的理科生。如果你想寫篇小說,進行一些創作,哪怕是開展一段文字RPG之旅,Claude 3.0可能更合適你。
7、兩張圖看懂Claude 3.0的價格是否有競爭力
根據AI模型分析機構Artificial Analysis的分析稱,模型通常遵循現有的價格-質量曲線,按照模型的參數規模大小來比較,Claude 3.0的Opus、Sonnet和Haiku模型各自佔據不同的價格和質量定位。
● 超大杯Opus的對標模型為GPT-4,它的定價水平與GPT-4相當,並且高於GPT-4 Turbo。目標客戶可能為,對大型語言模型能力要求特別高的用戶。
● Sonnet在中型模型中定價具有競爭力 ,它在質量上接近Mistral Large,但在價格上更接近Mistral Medium。
● Haiku的價格非常有競爭力,最接近小型模型,同時在能力上可以與中型模型競爭。對於成本敏感的用例(如低ARPU應用等),HaiKu是一個吸引人的選擇。
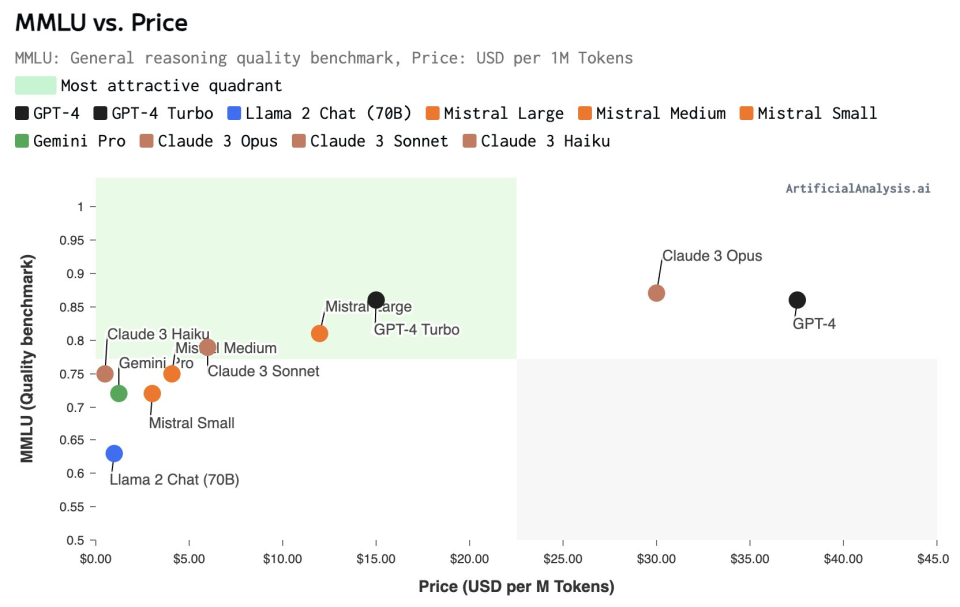
圖注:縱坐標為模型的MMLU Benchmark測試得分,橫坐標為百萬Token定價
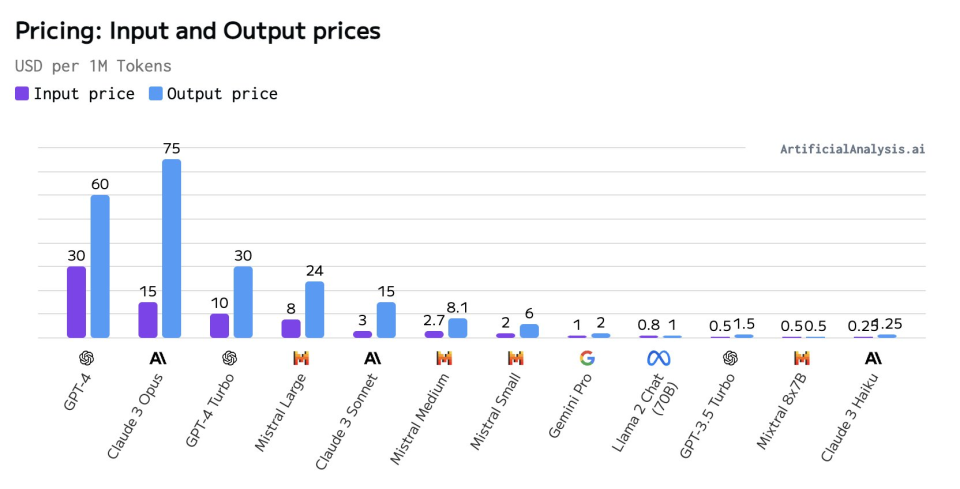
圖注:各模型輸入和輸出價格的對比(單位 每百萬token)

Claude 3.0
還面臨哪些沒有解決的問題
1、不支持網絡搜索
這可能並不算沒有解決的問題,根據技術文檔的介紹,Claude 3.0模型的訓練數據截止到2023年8月,且不支持網絡搜索,因此它們的回答將基於這個時間點之前的數據。如果用戶需要模型與特定文檔互動,他們可以直接將文檔分享給模型。
我們也注意到,技術文檔中提到了一個名為"Open-book"的設置,模型可以被賦予訪問互聯網搜索工具的能力。在這種設置下,模型可以通過搜索結果來幫助回答問題。
但是這種能力的具體實現和限製取決於Anthropic公司提供的API或服務的具體配置。如果Anthropic決定在未來的版本中為Claude模型提供這種功能,那麼理論上,Claude模型將能夠利用網絡搜索來增強其回答問題的能力。但這需要Anthropic在API設計中明確支持這一功能,並且可能還需要考慮相關的隱私、安全和合規性問題。
2、只支持圖像輸入,不支持圖像輸出
Claude 3.0 模型目前支持圖像輸入,用戶可以上傳圖像(例如表格、圖表、照片)以及文本提示,但是模型不支持圖像輸出,也就是說,它不能生成或返回圖像作為響應。
3、幻覺問題還是難以解決
MLST(Machine Learning, Statistics, and Technology)是一個專註於AI、統計學和技術的YouTube頻道和音頻播客,在Youtube上有10.7w粉絲。試用過Claude 3.0之後,他發推說:“對Claude 3.0.0的即時看法:它的幻覺非常嚴重——所有Anthropic的模型對我來說都是這樣。”
大模型幻覺是至今難解的問題,Claude 3.0也難免“一本正經的胡說八道”,網友曬出了一些示例圖。但是至於是否如MLST所說的,幻覺問題十分嚴重,還需要進一步的觀察和評測。

圖注:Claude 3.0.0錯誤回復ChatGPT為Antropic開發

詳細分析完Claude 3.0,
最後,GPT-5什麼時候出來炸場呢?
以Sam Altman的性格,暴風雨可能不會很久就會到來,JimFan也在推文中調侃道,“既然Claude-3剛剛宣布,我在等待幾個小時后精心安排的GPT-5發布”,並配了一個炸彈的表情包。
Jim Fan說“我喜歡Claude在GPT和Gemini主導的領域中提升熱度。不過請記住,GPT-4V,這個每個人都迫切想要超越的高水準,是在2022年完成訓練的。這是暴風雨前的寧靜。”
