所有語言











分享
字節模型來了!把字節當作token,統一一切,預測一切?
巴比特_硅星人305天前
文章來源:硅星人Pro

圖片來源:由無界AI生成
相信你或多或少對GPT有一定的了解,但我賭你沒聽說過bGPT。bGPT的意思是byte GPT,即字節GPT。這是一種專門設計用於處理二進制數據和模擬数字世界的深度學習模型。簡單概括,bGPT突破了傳統語言模型的局限,能夠直接理解和操作二進制數據,拓展了深度學習在原生二進制數據領域的應用邊界。
bGPT的成果來自於微軟亞洲研究院、清華大學以及中央音樂學院的共同開發,等會你就知道這裏為什麼會有中央音樂學院了,希望你還沒有忘記五線譜。
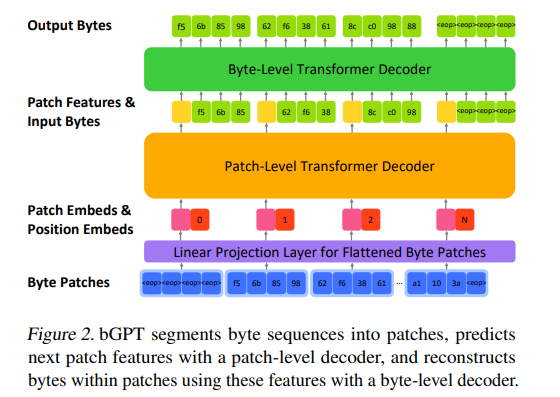
從運行邏輯來看,bGPT反而很像是在解數學題
在硅星人Pro的文章《揭秘Sora:用大語言模型的方法理解視頻,實現了對物理世界的“湧現”》中提到,大語言模型有一個核心功能是通過代碼將多種文本形式進行了統一。正是這種數據結構上的相同,才讓大語言模型實現“思考”,進而生成各種各樣的內容。但是文字的數據結構和音頻、圖像、符號、CPU狀態數據等等完全不相同,所以想要只使用一個大模型就完成對所有類型數據結構的學習,並不容易。
不過我們每一個使用电子產品的人都清楚,無論是何種類型的數據,它是由“字節”組成的。因此,研究團隊提出了一個想法,是否能用字節來代替傳統的token,使得大模型可以把所有類型的數據放在一起進行訓練推理。bGPT的技術原理是基於深度學習中的序列建模思想,通過訓練模型對連續的字節序列進行預測,以理解並生成符合特定上下文的二進制數據。
bGPT可以處理不同類型的聲音文件
如果說transformer模型的核心機制是自注意力,那麼bGPT的核心機制就是“猜”。通過深度學習訓練,學會根據當前字節序列預測接下來可能出現的字節,從而對数字世界的內在規律進行建模。即採用“下一個字節預測”的方式來模擬数字世界的各種活動。
就像大語言模型的預處理環節一樣,bGPT也有預處理,而且邏輯上和大語言模型是一致的,也是將不同類型的數據(音頻和圖像)標準化為適合模型輸入的格式。比如音頻就會被轉換為統一的WAV格式,設定採樣率為8kHz,單聲道,8位深度,並裁剪至一秒長度;而圖像數據則被設置為32×32像素、RGB顏色模式、24位深度的BMP格式。
接下來模型使用最終解碼層的補丁級特徵,通過平均池化操作提取全局特徵以供分類任務使用。這一步的作用是提取特徵,為下一步的生成式建模做準備。為了凸顯bGPT和市面上流傳的文字、圖像、視頻大模型不同,研究團隊特地選擇了音樂作為模型生成的內容。

論文所選取的樂譜
論文使用了兩種文件類型來做演示,第一種是ABC記譜法,第二種是MIDI。ABC記譜法是一種簡潔的人工編寫的文本格式,用來描述音樂曲目,而MIDI是一種二進制格式,記錄的是音樂演奏的具體表現細節。更直白一點,ABC記譜法就是我們人類看的操作手冊,MIDI則是機器用模擬環境來還原這份操作手冊。
bGPT首先將成對的ABC記譜法文件和對應的MIDI文件合併成連續的字節序列,並用特殊的分割符標識兩個文件之間的界限。接着,模型運用生成式建模的方法來學習這些字節序列的規律,從而實現了雙向轉換。也就是說,bGPT可以將基於文本的ABC記譜法樂譜轉換為MIDI二進製表演信號,以及將MIDI文件還原回ABC記譜法文本格式。
在實際效果上,bGPT在完成這項任務時展現了非常高的精確度。研究團隊在論文中寫到,在將ABC記譜法轉換為MIDI格式時,錯誤率低至每字節僅0.0011比特。儘管轉換過程中可能會遇到一些挑戰,比如MIDI轉回ABC時,由於MIDI不支持重複符號,導致ABC樂譜在視覺上顯得比原始版本更為冗長,裝飾音符也可能因MIDI的表現方式而在轉換回ABC時無法完全精確對應,但總體上bGPT成功地模擬了這個數據轉換的過程,證明了它在模擬和處理数字世界中不同數據格式間轉換的能力。
此外,為了評估bGPT在模擬数字過程方面的性能,研究人員還創建了一個CPU狀態數據集,通過Python腳本模擬CPU的操作,讓bGPT學習和預測CPU執行不同指令時的狀態變化,結果显示bGPT在此類硬件行為模擬上的準確性超過99.99%,進一步驗證了其在模擬数字世界複雜過程的有效性和潛力。
所謂CPU狀態集,是一個專為評估和訓練bGPT模型而構建的合成數據集,它模擬了CPU在執行一系列機器指令后內部寄存器狀態的變化情況。此數據集中每個實例都包含了1KB大小的內存塊,其中包含一定數量的機器指令,隨後是一系列16字節的CPU寄存器狀態序列,反映了每次執行指令后CPU的最新狀態。寄存器主要包括了程序計數器、累加器、指令寄存器、通用寄存器。
那麼換句話說,這CPU狀態集,其實就是想讓bGPT來模仿CPU的物理運行邏輯。研究團隊之所以選擇這種類型的數據結構,就是為了和傳統大模型進行區分。人家玩的就是時髦,玩的就是另類。
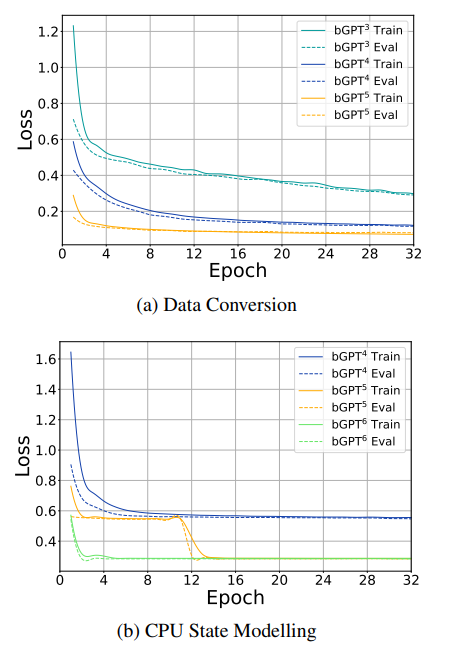
損失函數和周期的關係圖
讓我們看這兩張圖,上面的是ABC記譜法/MIDI所對應的數據轉換任務,下面就是CPU狀態建模任務。Loss代表損失函數(loss function),Epoch代表完整周期。隨着epoch數的增加,模型會不斷更新權重參數,以期在後續的Epoch中達到更低的損失水平。結果證明,模型預測輸出越來越接近實際標籤,擬合程度越來越好,預測能力越來越強。
數據轉換任務使用IrishMAN數據集進行驗證,不是我吹牛,這個數據集一般研究大模型的都不一定認識。它是一個包含了20多萬首愛爾蘭樂譜的ABC記譜法數據集。其中 99%(214122 首曲子)用於訓練,1%(2162 首曲子)用於驗證。為了確保格式的統一,所有曲調都被轉換為XML,然後使用腳本轉換回ABC記譜法,並且包含自然語言的字段(例如,標題和歌詞)被刪除。

IrishMAN數據集
bGPT是非常有創意的,因為字節是最基本的信息存儲單位,而且雖然人類用肉眼可能沒辦法理解0和1,但是不同類型的文件,它所對應的字節是截然不同的。咱們就拿音樂來說,它的字節是音頻數據、編碼格式、元數據。音頻數據是聲音振幅和頻率隨時間的變化,編碼格式是表示方法(MP3、WAV等),元數據是這段聲音的信息(歌曲名稱、表演者、所屬專輯等)。
因此這些字節是有規律可循的,它具備明顯的特徵,只不過人類識別不了罷了。藉由當下火熱的大模型技術,對這種格式的數據結構進行處理,最後成功實現。以這個邏輯來發展,是有可能發展出性能更強大的模型的。bGPT為這條道路開了個好頭。