所有語言











分享
讓 Kimi Chat 學完了整本周易,給 Sam Altman 算了一卦|AI 鮮測
巴比特_硅星人292天前
文章來源:硅星GenAI

最近,Kimi Chat 的上下文長度從 20 萬漢字升級到了 200 萬漢字,10 倍的差距已經足夠產生一次質變,做很多之前做不了的事情。
感謝月之暗面給了提前測試的機會,我們直接開測!
小夥伴可以上手試試啦!
場景1:做SEO(搜索引擎優化)!
第一輪測試用的是常規20萬上下文窗口,輸入了兩段網頁代碼,顯然兩輪對話已經超出20萬上下文。
這時候 200 萬漢字的上下文長度的優勢就顯現出來了,直接轉到200萬字上下文入口重新提問,如果按照剛剛對話的 token 數量來算的話,目前至少能支持10輪及以上的對話。
20萬上下文對話窗口:分兩次輸入兩段代碼直接超出20w
第二輪測試:用200萬窗口測試,這種持續連貫對話的感覺簡直太爽了!
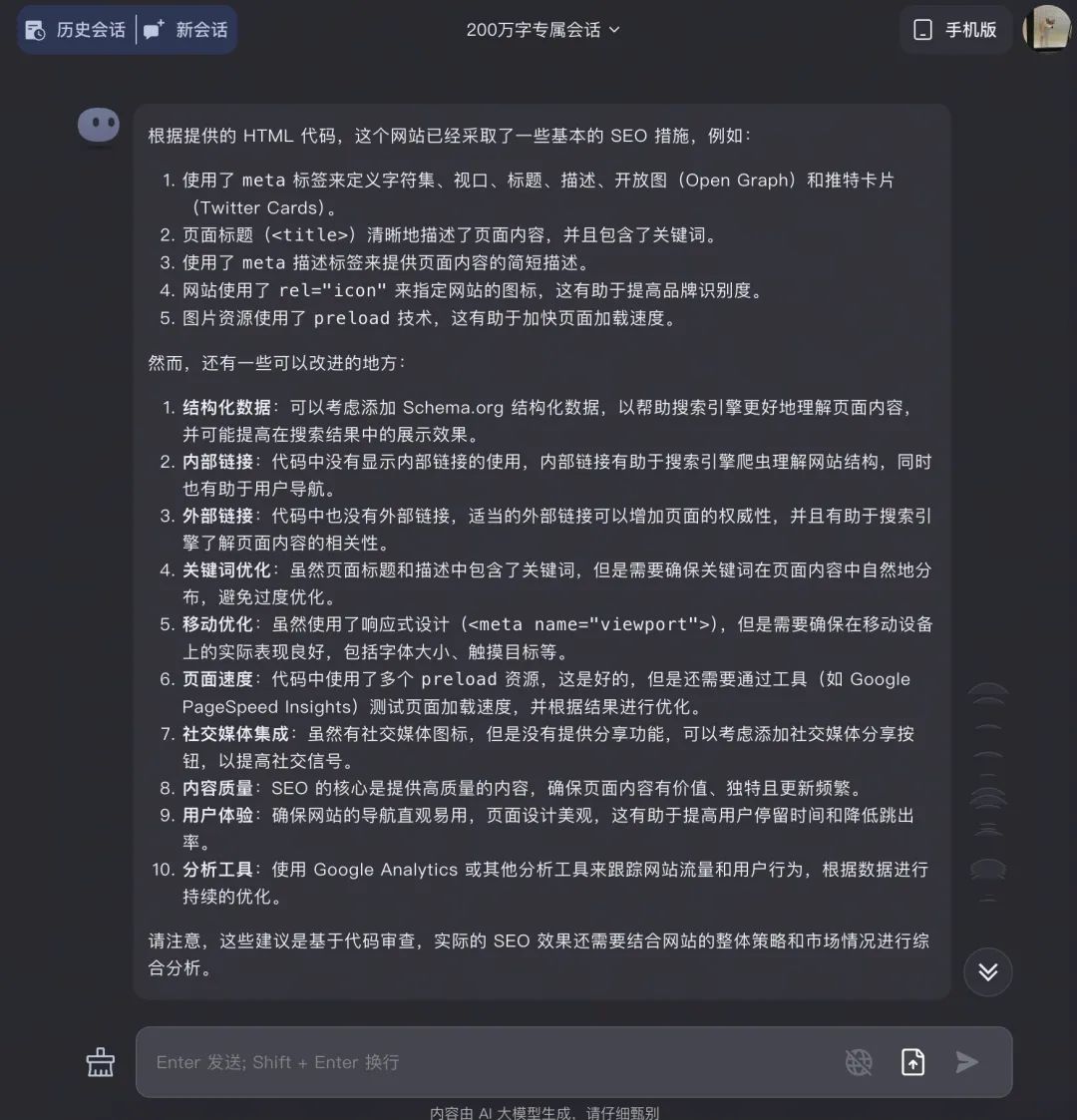
直接複製剛才的代碼到200萬窗口,它可一點兒沒含糊,不停地持續回答和輸出。然後直接問 Kimi 這個網站有啥可以改進的,它給了大概框架。
200萬上下文對話窗口:超級無限長的代碼10萬字段兒,足足劃了半分鐘才到頭兒
但我想要的是具體細緻的建議,
接下來我又問它,具體有什麼可以優化的地方;
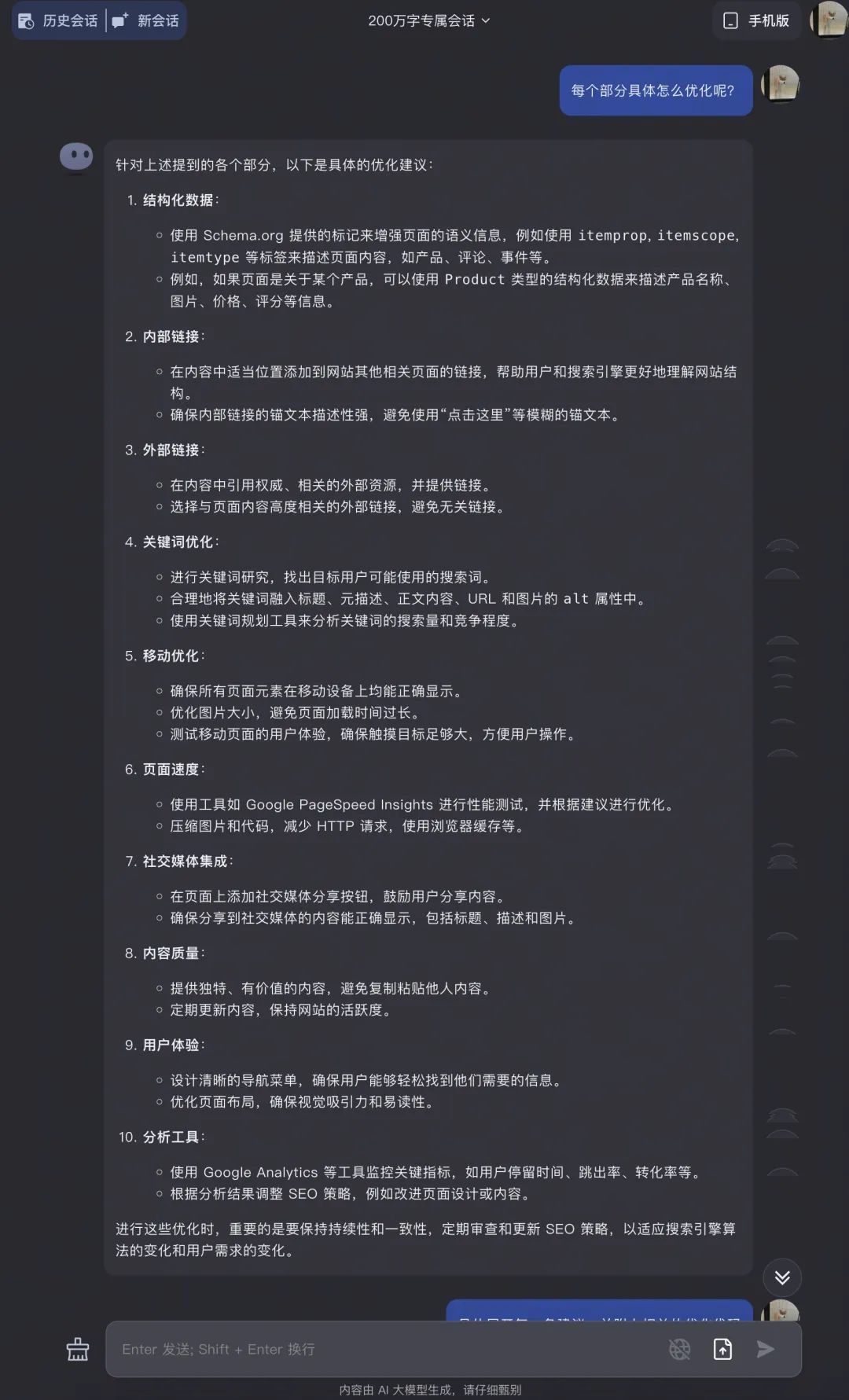
在這兩次對話中,網站 SEO 優化建議是有了,但是我需要的是具體能夠運行的代碼,接下來測測它到底能否理解我的要求並給出相關的代碼;
在回答具體建議時 Kimi 展開了每一條,優化的地方有十幾處,Kimi 逐個給出了 SEO 優化建議及代碼示例。(代碼實在太長了就不一一展開了)
但是也有一個缺點:就是每次輸出內容篇幅有限,又不能直接生成 PDF,就只能手動不停地點“繼續、繼續、繼續......”
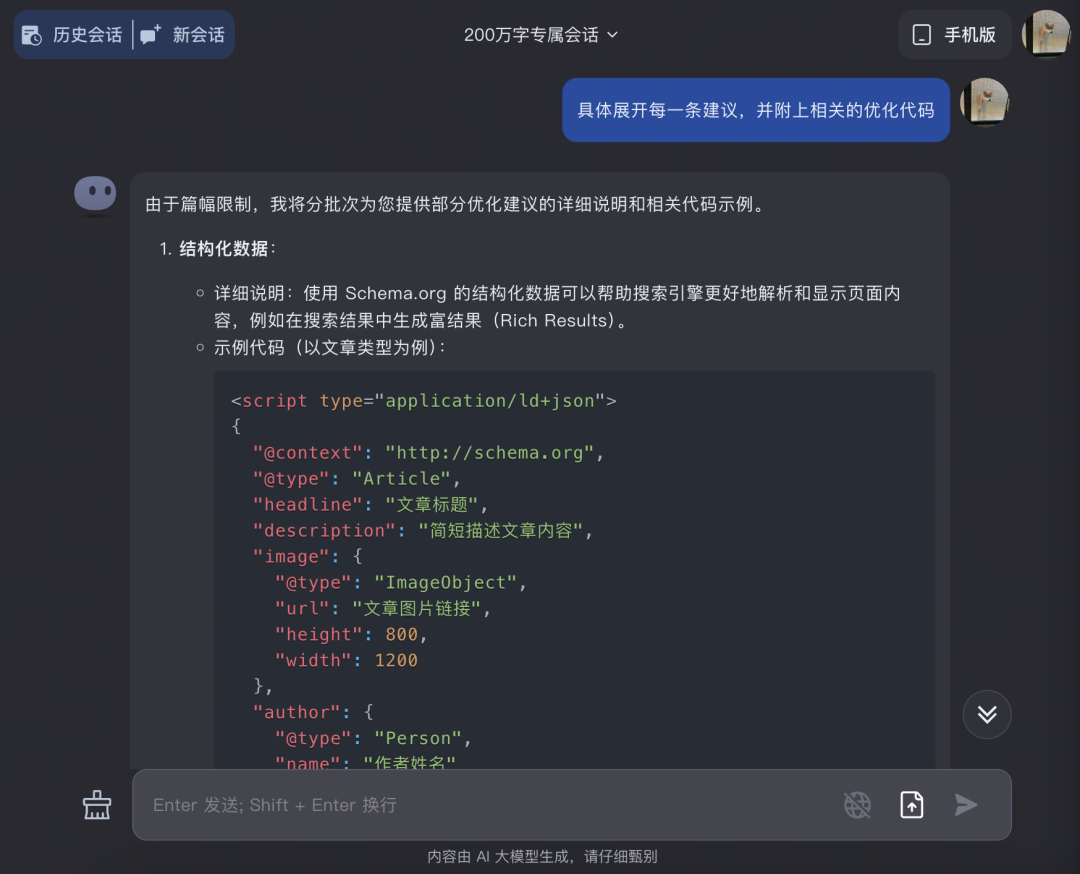
到這裏之後,在元數據上進行優化,大方向上不會破壞原來的內容,Kimi 這點理解的還是挺到位的!在優化上甚至還多加了一些我沒考慮到的點,十分周到。
在前幾次的回答中仍然不太滿意,我想要的是最終在原數據上優化后的代碼,於是再次要求它;
從理解能力和連貫性來看,Kimi 每次回答都能相對準確地聯繫上下文,同時給出相應的建議,可見它在長文本連貫性上是蠻強的!
現在我們來實際看一下,優化SEO網站之後的實際效果到底如何?
這次對話對網站的 SEO 優化最直觀體現在這三個地方:
第一,圖片和視頻在網頁中的佔比有所調整。比如第一個視頻整體變小,第二張圖也變的稍微小一些;
(PS:左為原網站,右為優化 SEO 后的網站)
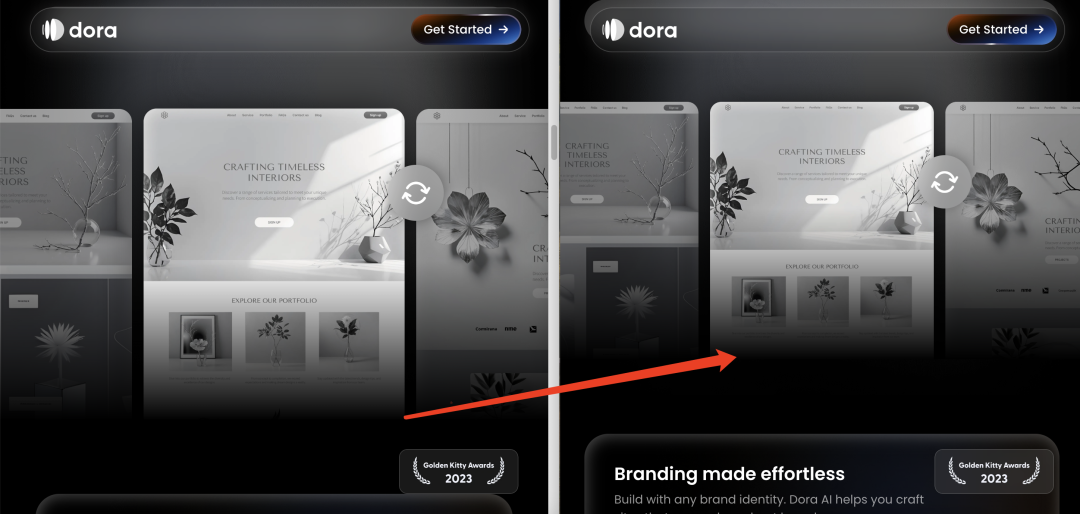
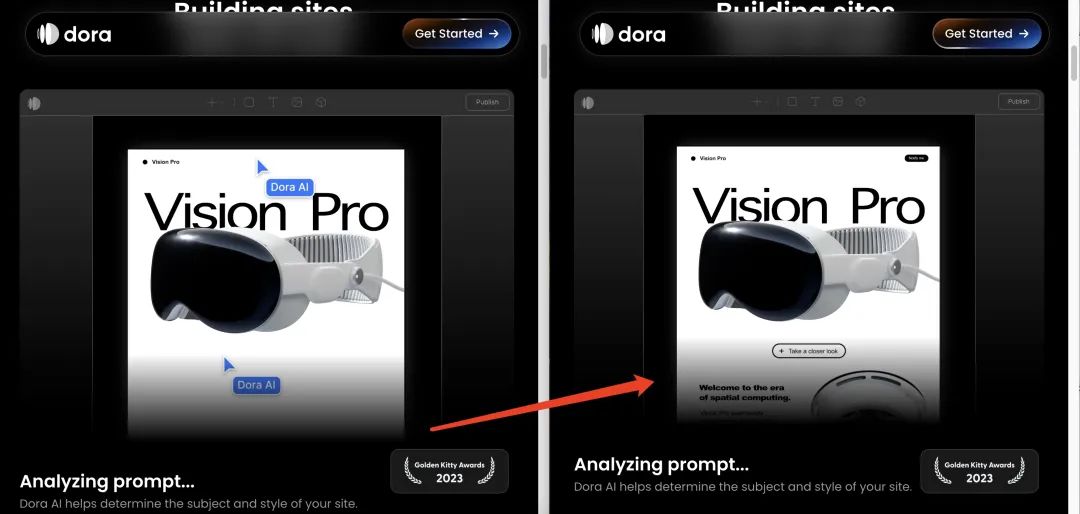
第二,頁面整體布局更加協調,更加符合視覺習慣,對比着看確實舒服不少。
第三,網頁文字內容優化,在原來的基礎上優化了網頁里呈現的文字內容,
場景2:我用《周易》給奧特曼算了一卦!
大型語言模型處理古文字與處理現代英文的差異時,一個顯著的區別在於所需的編碼單元或"token"的數量。古文字,如《周易》中的八卦符號,每個符號可能需要一個或多個 tokens 來準確表示其豐富的意義和歷史背景,因為這些符號往往蘊含着比現代字母更複雜的概念。相比之下,現代英文文字則相對簡單,通常每個字符對應一個token,因為它們的語義和形式更直接、更線性。

圖片源自網絡
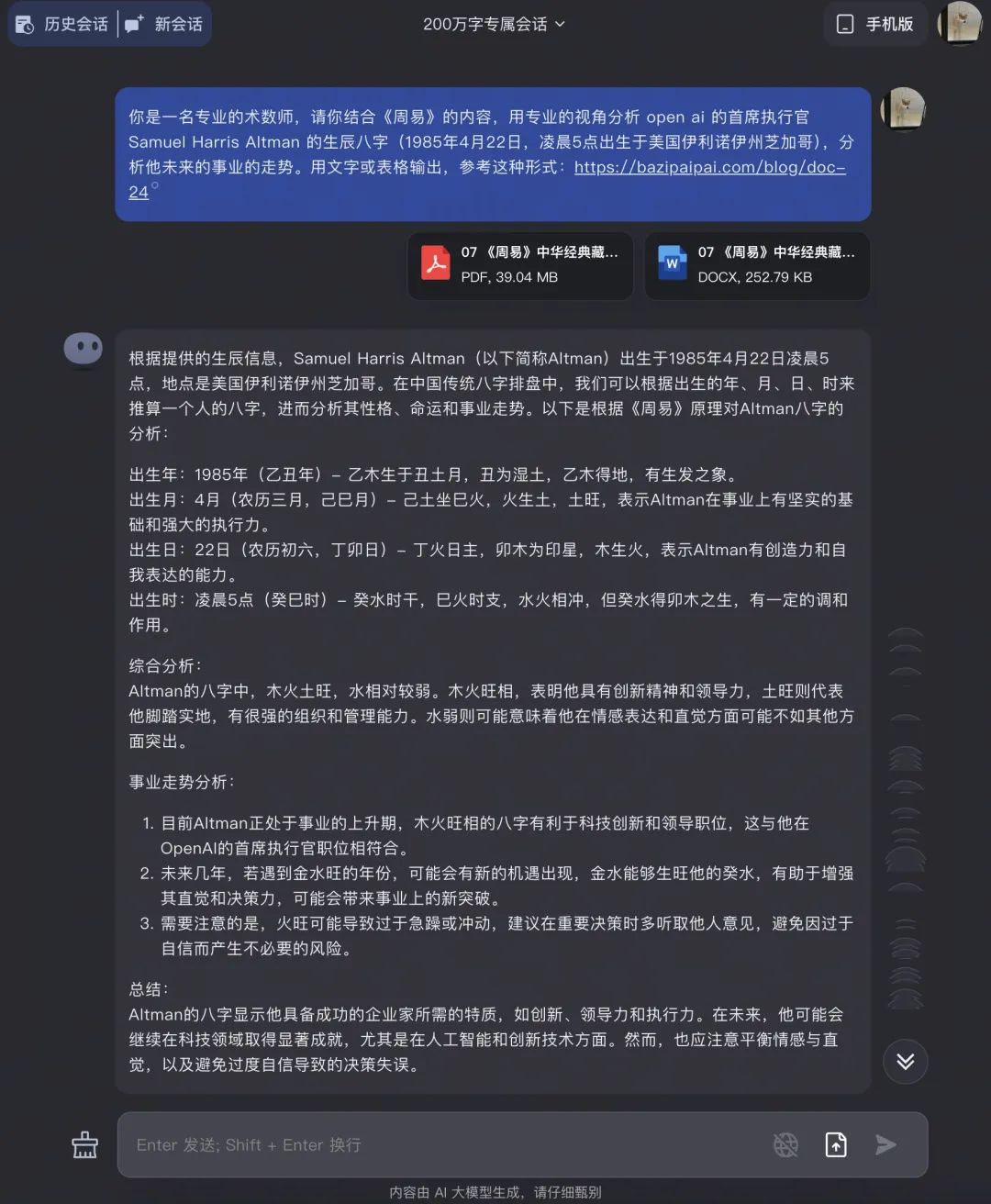
基於此,我就借用咱們的經典《周易》給奧特曼先生算一卦,看看 Kimi 在解讀《周易》古文字上的效果如何。
我先是上傳了中華經典《周易》典藏本,和奧特曼的生辰八字(約莫準確?)

圖片由 Midjourney 生成
從第一次回答中,能看出 Kimi 在解讀古文字時說的頭頭是道,像模像樣。讓我們繼續深入看看它到底專業不?
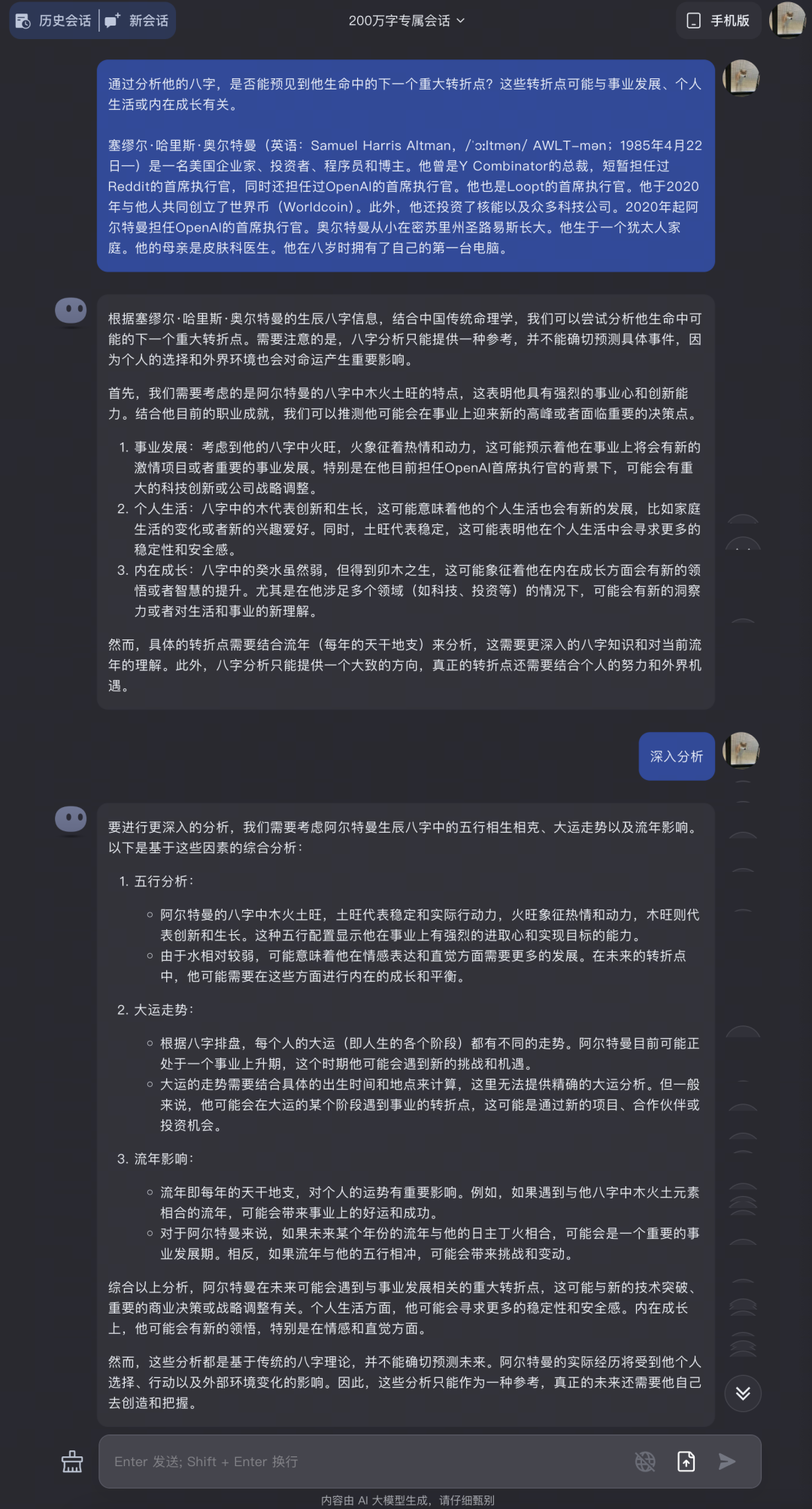
接下來我又給出奧特曼的一些生平履歷,
Kimi 一開始的回答很淺很淺,都沒啥意思;
但提醒它深入分析后,還是很淺!!
看來《周易》這種難啃的古文字對 Kimi 來說還是挺有難度的。
場景3:我用 Kimi 啃專業論文!
原本是想根據個人一年的工作材料,讓 Kimi 寫一個年終報告,但是現在三月份,還沒到那時候呢!
那如果是論文呢?
如果它連大幾十的論文都啃得動,能理解並且連續輸出重新寫一篇新的論文,個人年終總結更是不在話下!
下面我上傳了31份 AI 相關的熱門論文,kimi 能從大量晦澀難懂的論文中,迅速分析並輸出新的論文大綱,大綱內容角度還挺全面。
這部分不僅提煉出了新的主題,同時用中英文對照的方式寫了出來,還列出表格對比了新舊論文的主要觀點。
最初想法是寫一篇論文,那自然要看看他能提出哪些獨到的觀點,看他是否真的理解了這些論文的內容,然後從這些觀點中選擇一個主題寫出論文大綱;
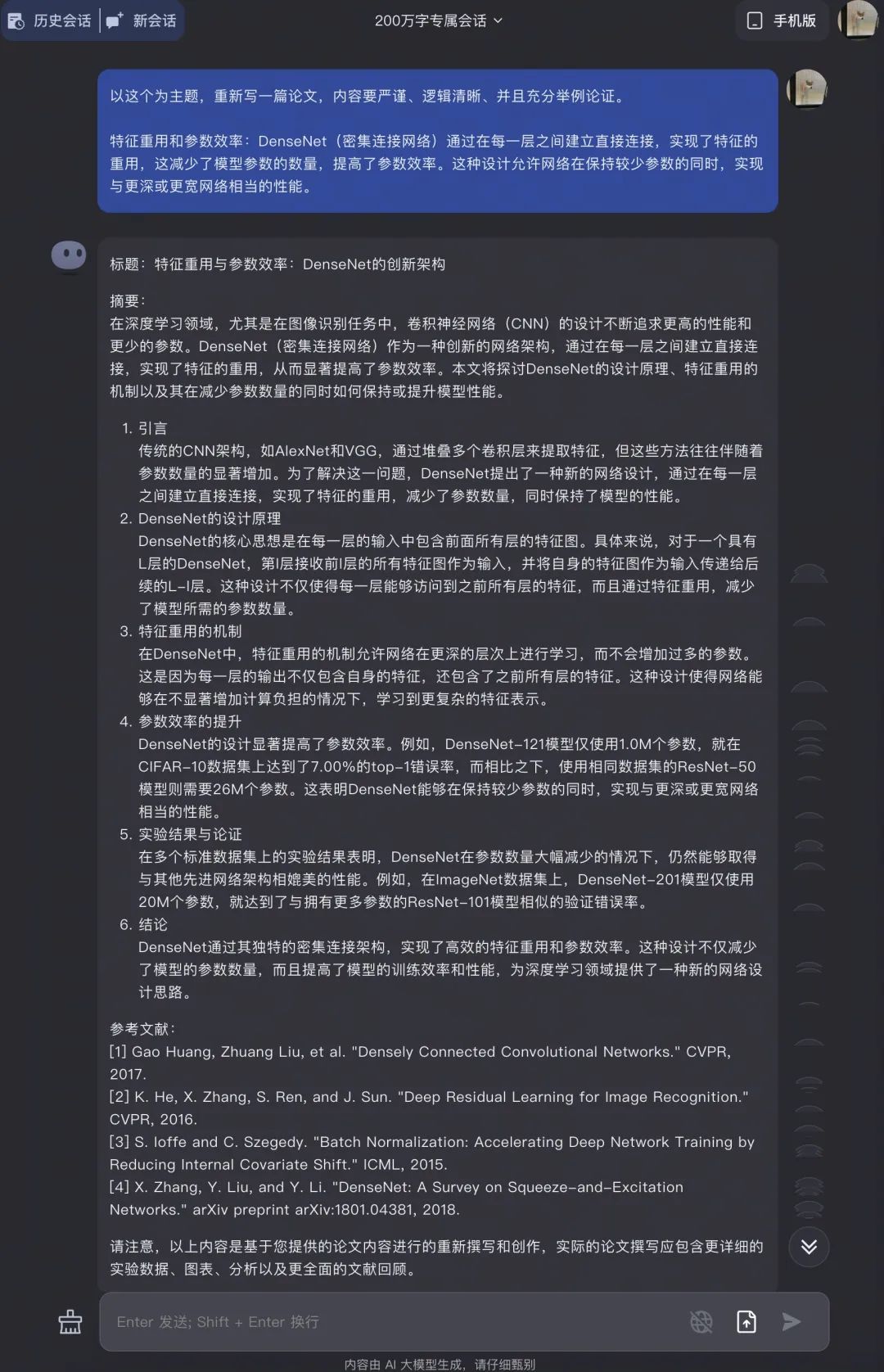
接下來就是撰寫正文了,對於 Kimi 輸出內容質量倒是沒那麼擔心,不過 Kimi 有個缺點是每一次的輸出篇幅偏短,想要讓它一次寫長論文,基本沒可能。倒是 Kimi 自己在結尾也提醒到了“篇幅有限”這一點。
如果想要更精細的內容,更好的辦法是把論文大綱拆分成小章節單獨擴寫,才能達到想要的效果。
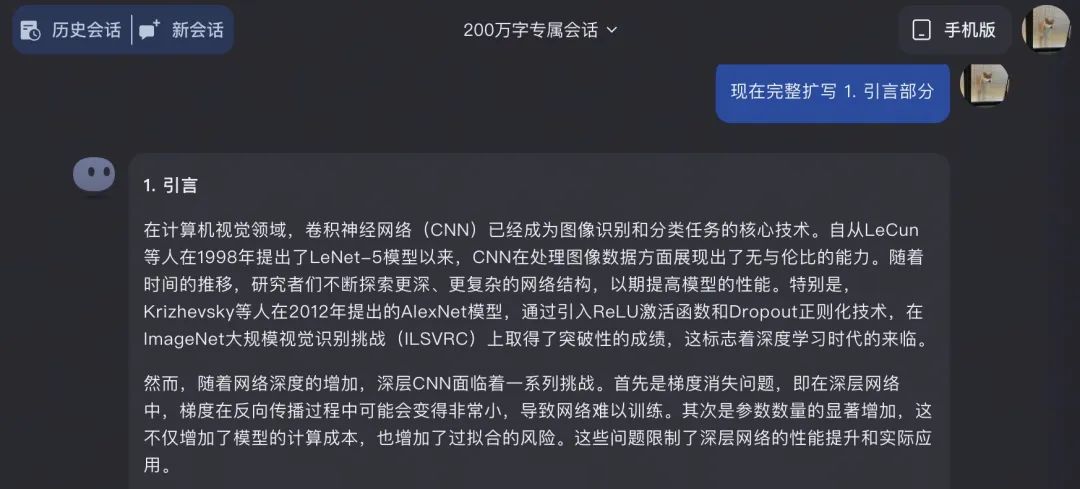
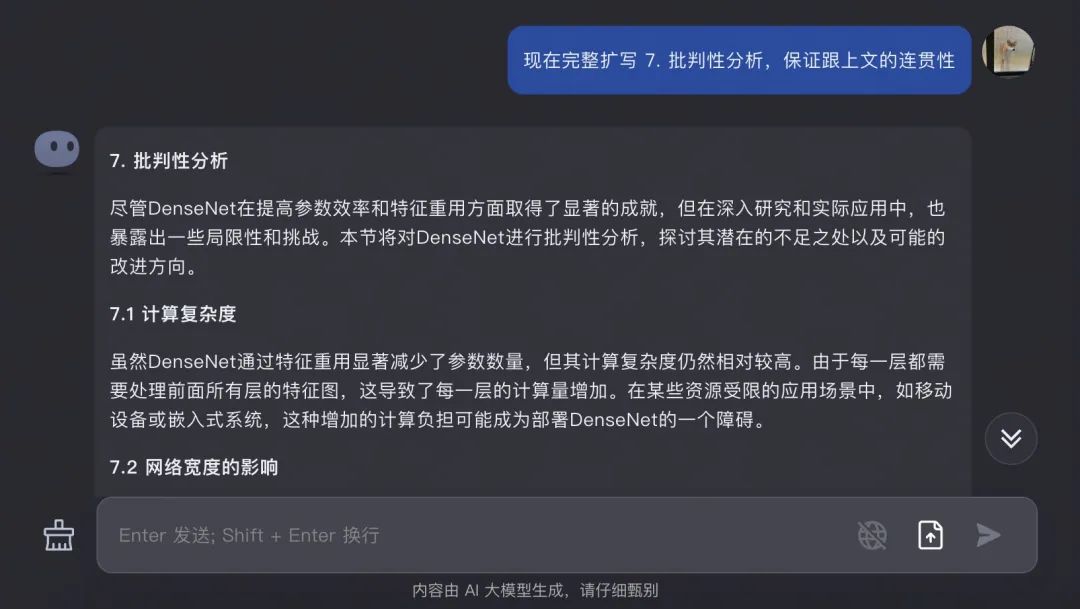
這個測試極大地體現出來 Kimi 對於上下文的高度連續性,對於工作中處理大量的文獻以及資料 十分方便,尤其是想要提取特定的信息的時候。
通過這次測試,最大的感受是:上下文帶來不僅僅 AI 的學習能力,更重要的是讓 AI 的耐力更強,我們可以持續進行多輪對話。
超長文本輸入+持續的多輪對話能力,我們在一個對話中就能將 AI 微調成我們需要的樣子。
月之暗面創始人 楊植麟認為:“所有問題都是文本長度的問題。如果你有10億的 context length(上下文長度),今天看到的問題都不是問題。”
對於長文本來說更重要的是 lossless,也就是輸入的信息不隨着文本長度增加而損失。某種程度上,絕對的文本長度是花架子,無損壓縮的能力才能分模型的勝負。
月之暗面方面透露,這次上下文長度從20萬字擴展到200萬字由於沒有採用常規的漸進式提升路線,研發和技術團隊遇到的技術難度也是指數級增加的。為了達到更好的⻓窗口無損壓縮性能,團隊從模型預訓練到對⻬、推理環節均進行了原生的重新設計和開發。
期待月之暗面 10 億上下文的那一天,也歡迎各位讀者將自己使用 Kimi Chat的經驗和心得分享給我們, 探索200 萬漢字的潛力到底在哪裡。