所有語言











分享
拿CPU搞AI推理,誰給你的底氣?
巴比特_AI领航员247天前
文章來源:量子位 | 公眾號 QbitAI
金磊 夢晨 發自 凹非寺

圖片來源:由無界AI生成
大模型的訓練階段我們選擇GPU,但到了推理階段,我們果斷把 CPU加到了菜單上。
量子位在近期與眾多行業人士交流過程中發現,他們中有很多人紛紛開始傳遞出上述的這種觀點。
無獨有偶,Hugging Face在官方優化教程中,也有數篇文章劍指“如何用CPU高效推理大模型”:
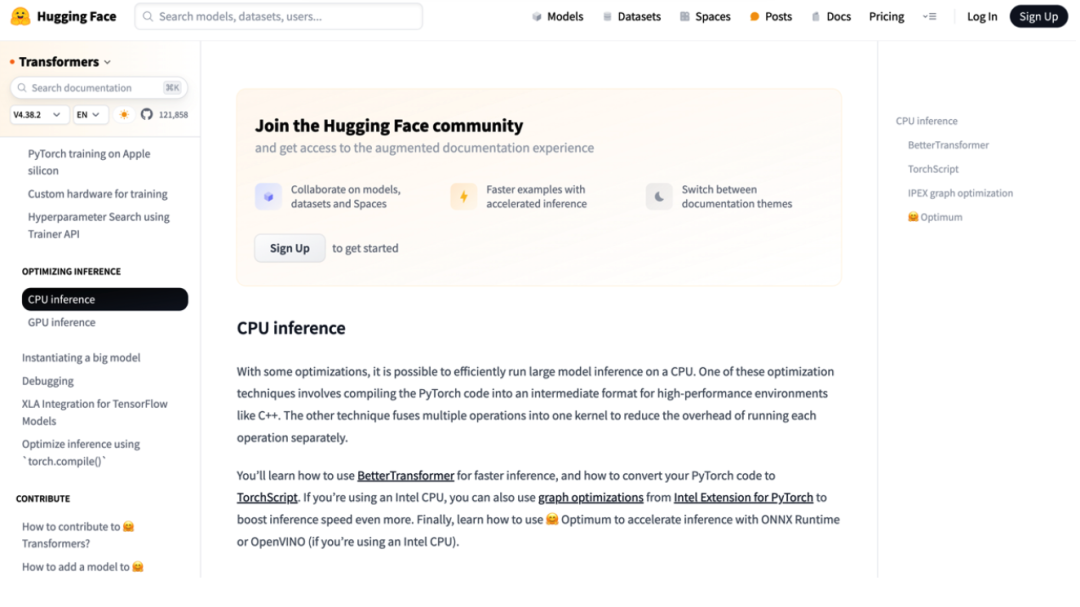
而且細品教程內容后不難發現,這種用CPU加速推理的方法,所涵蓋的不僅僅是大語言模型,更是涉獵到了圖像、音頻等形式的多模態大模型。

不僅如此,就連主流的框架和庫,例如TensorFlow和PyTorch等,也一直在不斷優化,提供針對CPU的優化、高效推理版本。
就這樣,在GPU及其他專用加速芯片一統AI訓練天下的時候,CPU在推理,包括大模型推理這件事上似乎辟出了一條“蹊徑”,而且與之相關的討論熱度居然也逐漸高了起來。
至於為什麼會出現這樣的情況,與大模型的發展趨勢可謂是緊密相關。
自從ChatGPT問世引爆了AIGC,國內外玩家先是以訓練為主,呈現出一片好不熱鬧的百模大戰;然而當訓練階段完畢,各大模型便紛紛踏至應用階段。
就連英偉達在公布的最新季度財報中也表示,180億美元數據中心收入,AI推理已佔四成。
由此可見,推理逐漸成為大模型進程,尤其是落地進程中的主旋律。
為什麼Pick CPU做推理?
要回答這個問題,我們不妨先從效果來倒推,看看已經部署了CPU來做AI推理的“玩家”用得如何。
有請兩位重量級选手——京東雲和英特爾。
今年,京東雲推出了搭載第五代英特爾® 至強® 可擴展處理器的新一代服務器。
首先來看這款新服務器搭載的CPU。
若是用一句話來形容這個最新一代的英特爾® 至強® 可擴展處理器,或許就是AI味道越發得濃厚——
與使用相同內置AI加速技術(AMX,高級矩陣擴展)的前一代,也就是第四代至強® 可擴展處理器相比,它深度學習實時推理性能提升高達42%;與內置上一代AI加速技術(DL-Boost,深度學習加速)、隔輩兒的第三代至強® 可擴展處理器相比,AI推理性能更是最高提升至14倍。
到這裏,我們就要詳細說說英特爾® 至強® 內置AI加速器經歷的兩個階段了:
第一階段,針對矢量運算優化。
從2017年第一代至強® 可擴展處理器引入高級矢量擴展 512(英特爾® AVX-512)指令集開始,讓矢量運算利用單條CPU指令就能執行多個數據運算。
再到第二代和第三代的矢量神經網絡指令 (VNNI,是DL-Boost的核心),進一步把乘積累加運算的三條單獨指令合併,進一步提升計算資源的利用率,同時更好地利用高速緩存,避免了潛在的帶寬瓶頸。
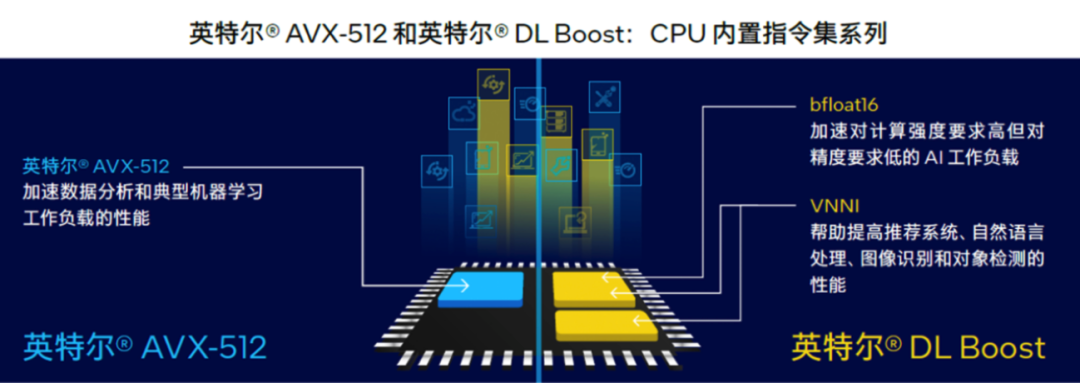
第二階段,也就是現階段,針對矩陣運算優化。
所以從第四代至強® 可擴展處理器開始,內置AI加速技術的主角換成了英特爾® 高級矩陣擴展(英特爾® AMX)。它特別針對深度學習模型最常見的矩陣乘法運算優化,支持BF16(訓練/推理)和INT8(推理)等常見數據類型。
英特爾® AMX主要由兩個組件組成:專用的Tile寄存器存儲大量數據,配合TMUL加速引擎執行矩陣乘法運算。有人把它比作內置在CPU里的Tensor Core,嗯,確實很形象。
這麼一搞,它不僅做到在單個操作中計算更大的矩陣,還保證了可擴展性和可伸縮性。
英特爾® AMX在至強® CPU每個內核上並靠近系統內存,這樣一來可減少數據傳輸延遲、提高數據傳輸帶寬,實際使用上的複雜性也降低了。
例如現在若是將不超過200億參數的模型“投喂”給第五代至強® 可擴展處理器,那麼時延將低到不超過100毫秒!

其次再看新一代京東雲服務器。
據介紹,京東與英特爾聯合定製優化的第五代英特爾® 至強® 可擴展處理器的Llama2-13B推理性能(Token 生成速度)提升了 51%,足以滿足問答、客服和文檔總結等多種AI場景的需求場景。
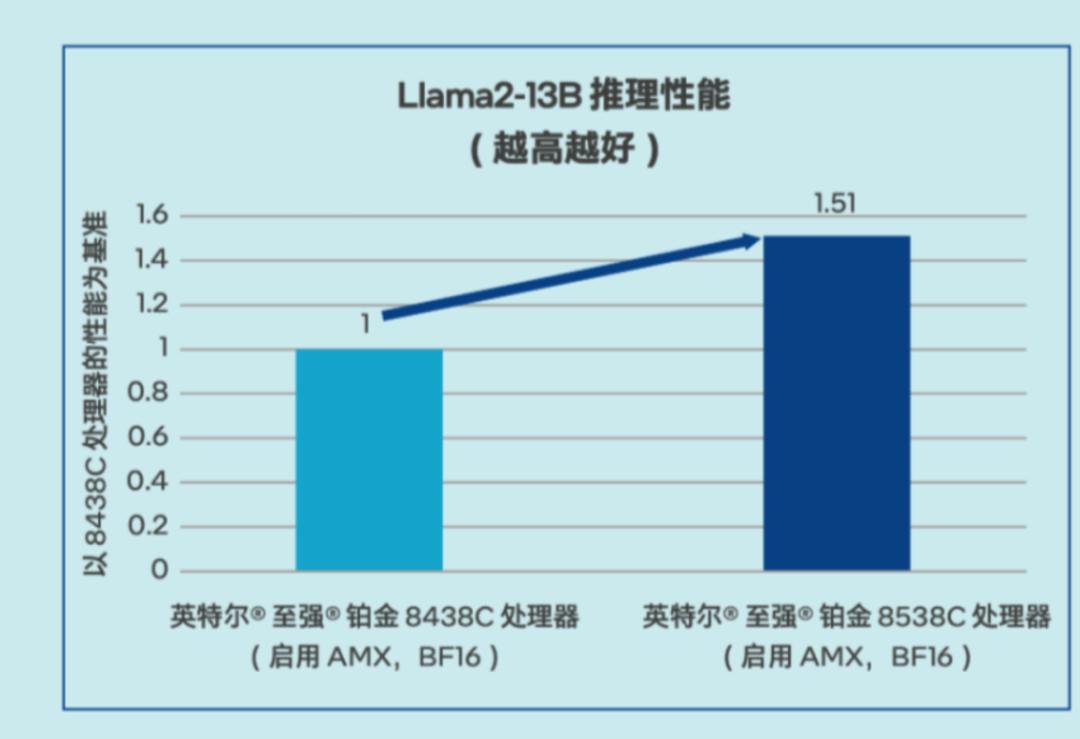
△ Llama2-13B推理性能測試數據
對於更高參數模型,甚至是70B Llama2, 第五代英特爾® 至強® 可擴展處理器仍可勝任勝任。
由此可見,CPU內置AI加速器發展到現在,用於推理已能保證在性能上足夠應對實戰需求了。
像這樣建立在通用服務器基礎上的AI加速方案,除了可用於模型推理之外,還能靈活滿足數據分析、機器學習等應用的需求,誇張點說,一個服務器就能完成AI應用的平台化和全流程支持。
不僅如此,用CPU做AI推理,也存在CPU與生俱來的優勢,例如成本,還有更為重要的——部署和實踐的效率。
因為它本身就是計算機的標準組件,幾乎所有的服務器和計算機都配備了CPU,傳統業務中也已然存在大量的基於CPU的現成應用。
這意味着選擇CPU進行推理,既容易獲取,也不需要導入異構硬件平台的設計或具備相關的人才儲備,還更容易獲得技術支持和維護。
以醫療行業為例,過去CPU已廣泛用於电子病歷系統、醫院資源規劃系統等,培養出成熟的技術團隊,也建立了完善的採購流程。
以此為基礎,醫療信息化龍頭企業衛寧健康,就利用CPU構建了能夠高效、低成本部署和應用的WiNEX Copilot落地方案,這個方案已深度集成到衛寧新一代的WiNEX產品中,任何一家已採用該系統的醫院,都能迅速上崗這種“醫生AI助手”。
僅其一項病歷文書助手功能,就可以在8小時內,也就是在醫生下班后的時間里處理近6000份病歷,相當於三甲醫院12位醫生一天工作量的總和!
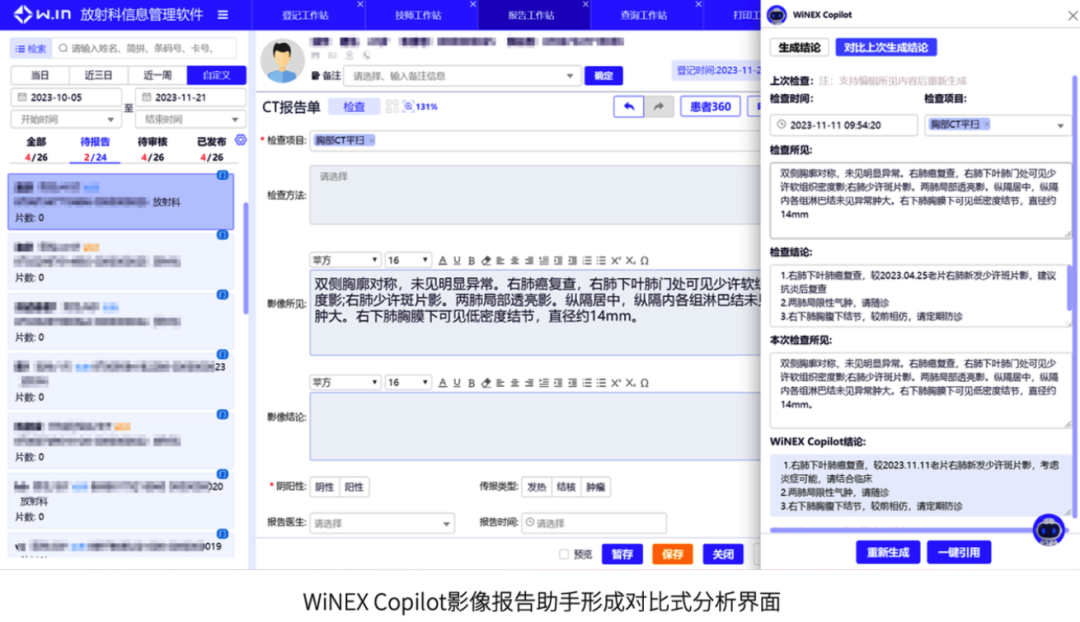
而且也正如我們剛才所提到的,從Hugging Face所提供的優化教程來看,只需要簡單的幾步,就可以讓CPU快速部署用於高效推理。
優化簡單、上手快,便是CPU真正在AI應用落地過程中的又雙叒一個優勢了。
這意味着任何或大或小的場景中,只要基於CPU的優化實現了一個單點的成功突破,那麼它很快就可以實現精準且快速的複製或擴展,結果就是:能讓更多用戶能在相同或相近的場景中,以更快的速度、更優的成本把AI應用落到實地。
畢竟英特爾不僅是一家硬件公司,同時也擁有着龐大的軟件團隊。在傳統深度學習時代就積累了大量優化方法和工具,如OpenVINO™ 工具包就在工業、零售等行業廣泛應用。
到了大模型時代,英特爾也深入與主流大模型如Llama 2、Baichuan、Qwen等深度合作,以英特爾® Extension for Transformer工具包為例,它就能讓大模型推理性能加速達40倍。
加之現在大模型所呈現的明顯趨勢就是越發地開始卷應用,如何能讓層出不窮的新應用“快好省”地落下去、用起來成了關鍵中的關鍵。
因此,為什麼越來越多的人會選擇CPU做AI推理,也就不難理解了。
或許,我們還可以再引用一下英特爾CEO帕特·基辛格2023年底接受媒體訪問時所說的話,來鞏固一下各位的印象:
“從經濟學的角度看推理應用的話,我不會打造一個需要花費四萬美元的全是H100的後台環境,因為它耗電太多,並且需要構建新的管理和安全模型,以及新的IT基礎設施。”
“如果我能在標準版的英特爾芯片上運行這些模型,就不會出現這些問題。”
AI Everywhere
回看2023年,大模型本身是AI圈絕對的話題中心。
但2024年剛開始,明顯能感覺到的趨勢就是各類技術進展,各行業應用落地進展都在加快,呈現一種“多點開花”的局面。
在這種局面下,可以預見的是還將有更多AI推理需求湧現,推理算力在整個AI算力需求中所佔的比例只會增加。
比如以Sora為代表的AI視頻生成,業內推測其訓練算力需求其實比大模型少,但推理算力需求卻是大模型的成百上千倍。
而AI視頻應用落地需要的視頻傳輸等其他加速優化,也是CPU的拿手好戲。
所以綜合來看,CPU在整個英特爾AI Everywhere願景下的定位也就明確了:
補足GPU或專用加速器覆蓋不到或不足的地方,為更多樣和複雜的場景提供靈活的算力選擇,在強化通用計算的同時,成為AI普及的重要基礎設施。

參考鏈接:
[1]https://huggingface.co/docs/transformers/v4.34.0/en/perf_infer_cpu
[2]https://huggingface.co/docs/transformers/en/perf_infer_cpu
[3]https://mp.weixin.qq.com/s/85FopWzLOVi5a8x5AocYlw
[4]https://developer.aliyun.com/article/1424070?spm=5176.26934562.main.2.4a33333aPN4UBS