所有語言











分享
ChatGPT和Sora其實限制了我們對大模型的想象?
巴比特_硅星人285天前
文章來源:硅星人pro
作者|王兆洋

圖片來源:由無界AI生成
最近一份美國市場研究機構發布的報告火了。報告詳細分析了OpenAI部署Sora所需的硬件資源,計算得出,在峰值時期Sora需要高達72萬張英偉達H100 來支持,對應成本是1561億人民幣。
同時,還有一條新聞也在刷屏。一名微軟的工程師爆料,為了訓練GPT-6而搭建了10萬個H100,結果卻把電網直接搞崩了。
而且這些新聞讓關心大模型的人們開始嘀咕:
費這麼大勁把地球資源都耗盡了,就為生成幾個文字,生成幾個視頻,真的值得嗎?
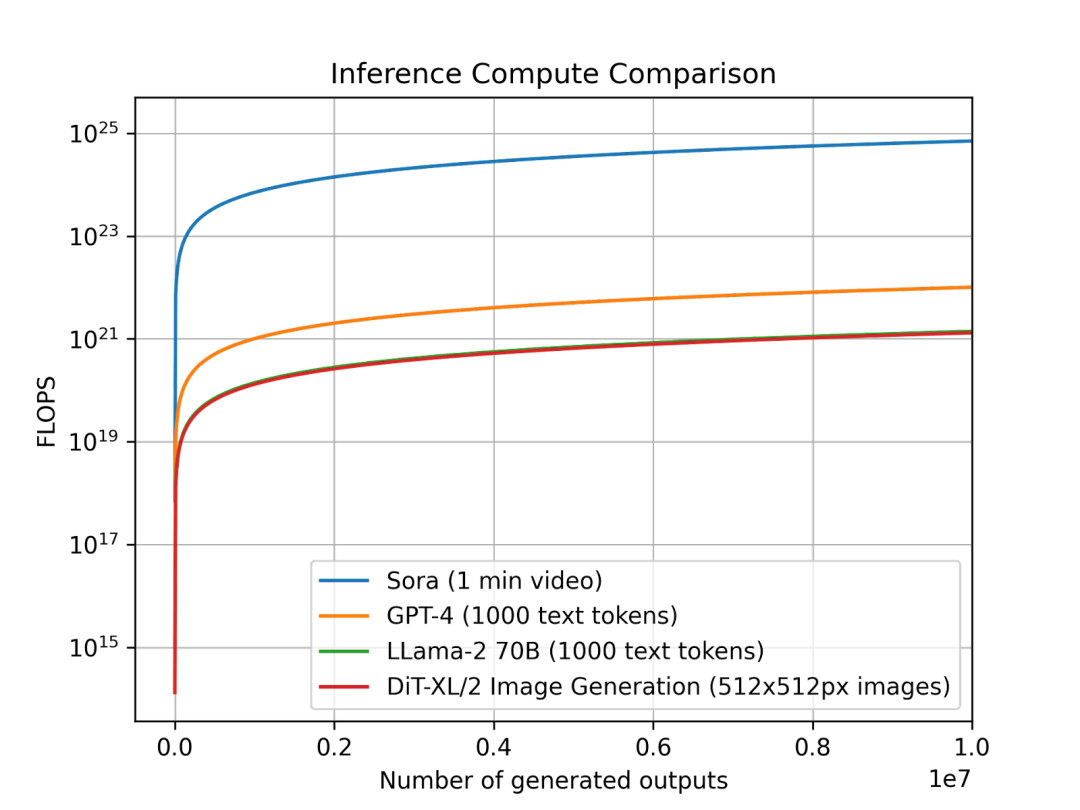
(圖源:Factorial funds)
其實,某種程度上,ChatGPT和Sora限制了人們對大模型的想象力——
生成文字可以“通過預測下一個token就理解世界”,生成視頻可以變成“理解物理世界的引擎”,於是所有資源都投入到生成文字與圖像上去。
但,大模型的想象力就這樣了嗎?
不看不知道,行業大模型已經有多強
最近行業里流傳的一系列有趣的案例,大大突破了ChatGPT和Sora提供的樣本,給大家看到了生成式AI更多的想象空間。
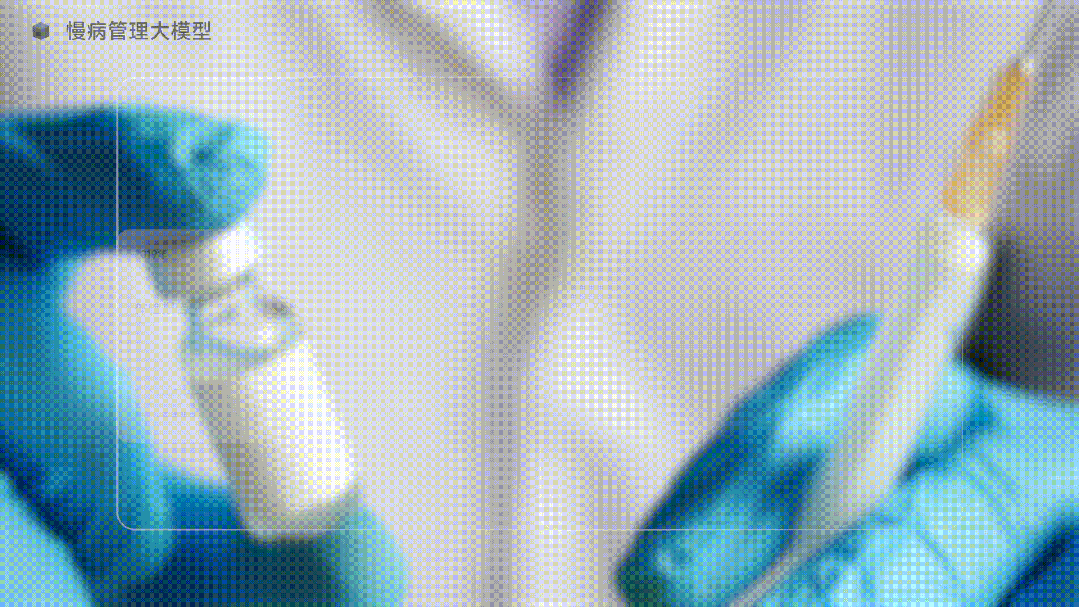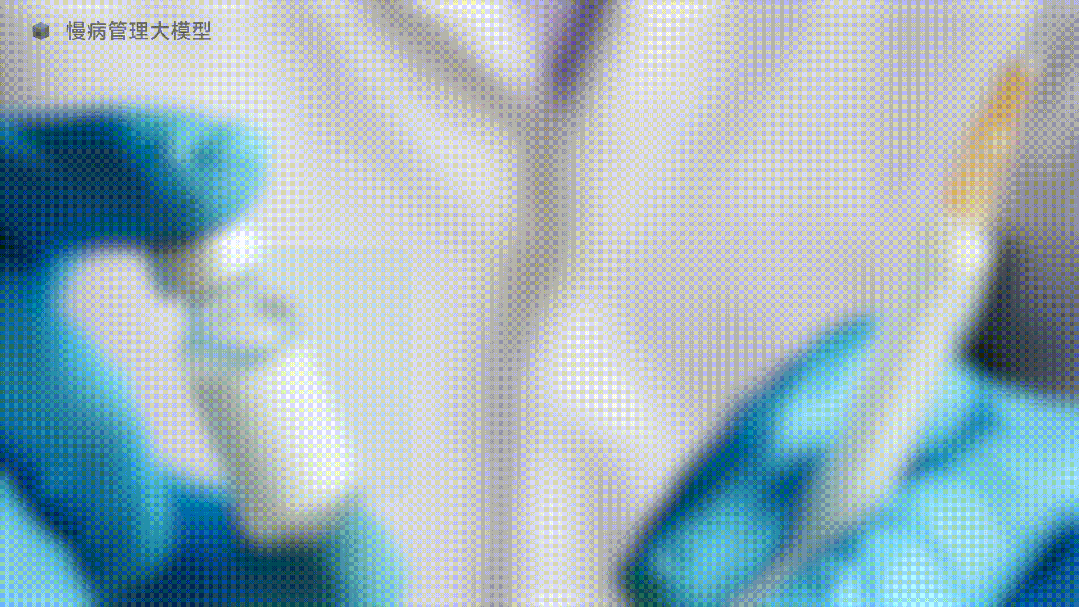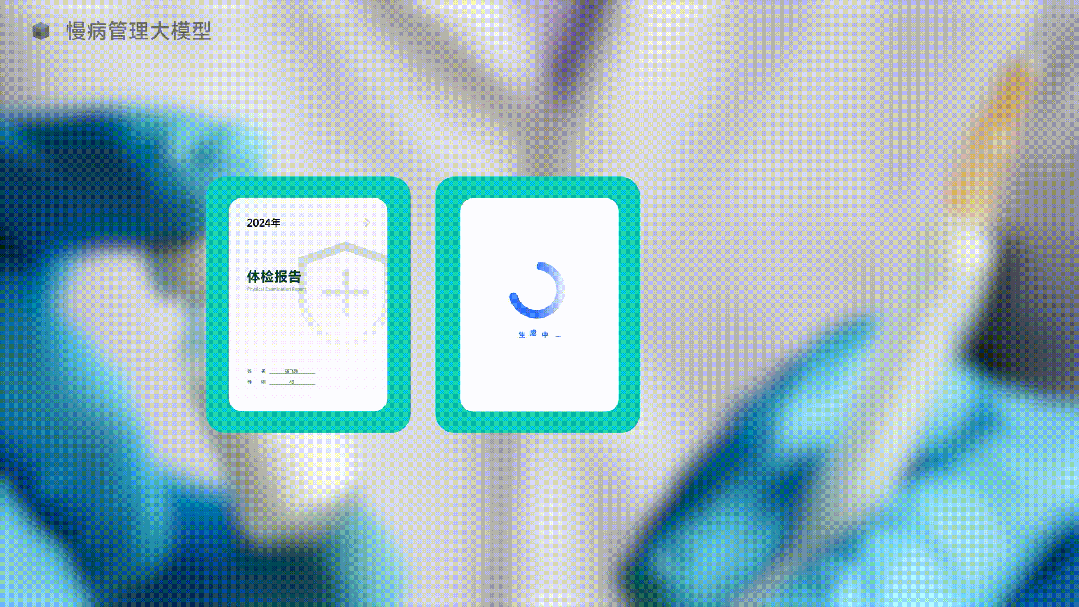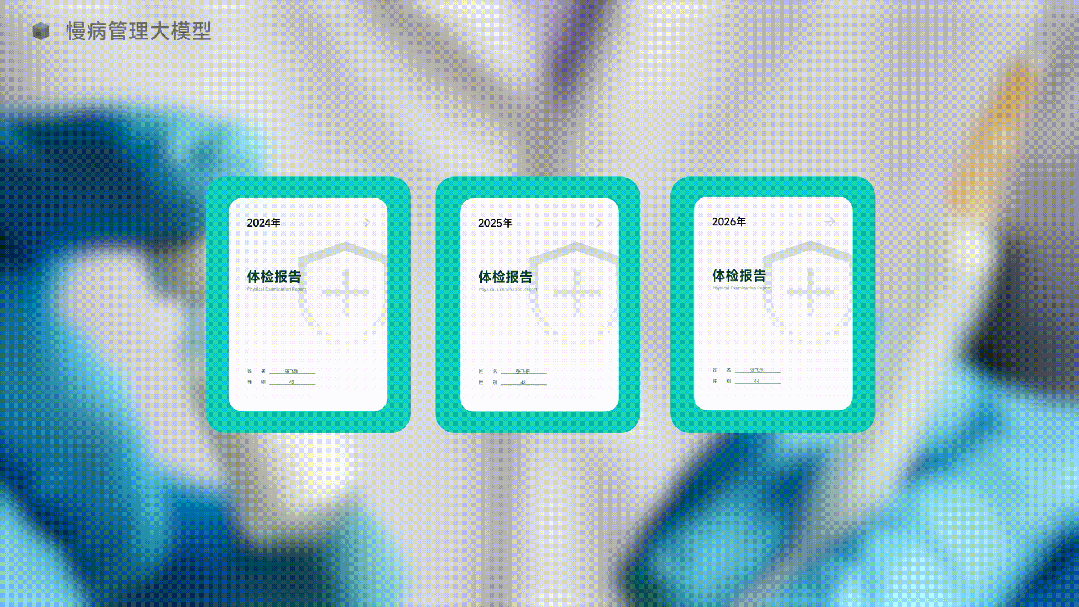
圖中是一個AI正在生成體檢報告,是的,它在生成“未來”的體檢報告。
在健康管理行業,如何更早的對人們的健康狀況作出風險預警,是個關鍵的問題。
那麼,既然生成式AI這麼強大,讓AI直接生成未來的體檢報告如何?
AI還真的就給你生成了。未來的體檢結果讓你必須重視。

不只是人類體檢報告,AI還可以生成複雜的水電機組的未來“體檢報告”。
可以看到,AI直接給出了具體的時間,精確到分鐘的運行狀況,提示可能發生的高溫故障。
提示老師傅檢查,並調整檢測和運行的策略。
這些案例就來自AI公司第四範式在產業界的一些實踐。這些行業大模型基於一個叫做先知AIOS的行業大模型平台,涵蓋各類AI 模型的開發、納管和應用,這個平台已經進化到了 5.0版。
AI生成一切,一切AI都是生成
敏銳的讀者一定已經發現,這些神奇的案例有個共同特點:
其實它們都在“Predict the next X”。而這個X,不只是ChatGPT等大語言模型在處理的“語言”,而是更多更豐富的各個行業的X模態數據。
某種程度上,ChatGPT證明使用大量數據進行預訓練,然後以“Predict the next token”的方式,是可以產生智能的。而Sora則證明了這種“Predict the next X”的方式不應只局限在token代表的文本數據。
ChatGPT和Sora的出現,都證明了“Predict the next X”這個路線的正確。
因此進一步打開想象空間和發揮大模型價值的方向,就是讓“Predict the next X”里的X,這一未知數的指代形式不斷擴展延伸。
這個X,可能是體檢報告、水文數據,可能是監測數值和應急預案。這些行業的大模型,需要行業里很多形態的數據,很強的行業知識,最終去生成特定行業的X。
比如下面這個垂直行業從業者開發的聲效大模型。
當你要為一個音樂廳設計最佳的聲音體驗時,只需要讓這個行業大模型去生成不同方案下的聲音方案,讓它提供具體的數據,並用直觀的圖像展示出來。
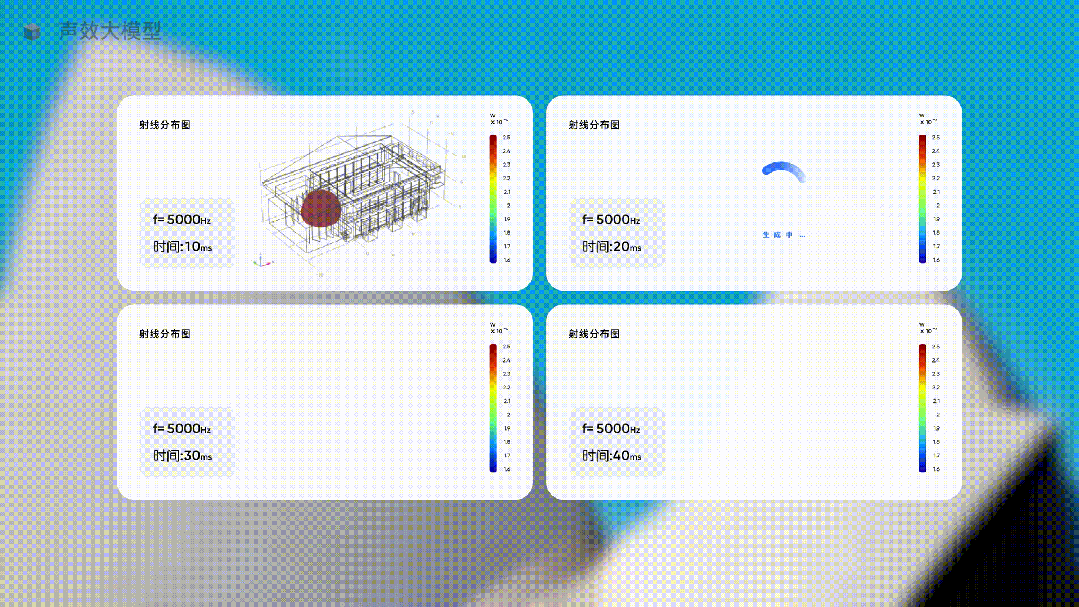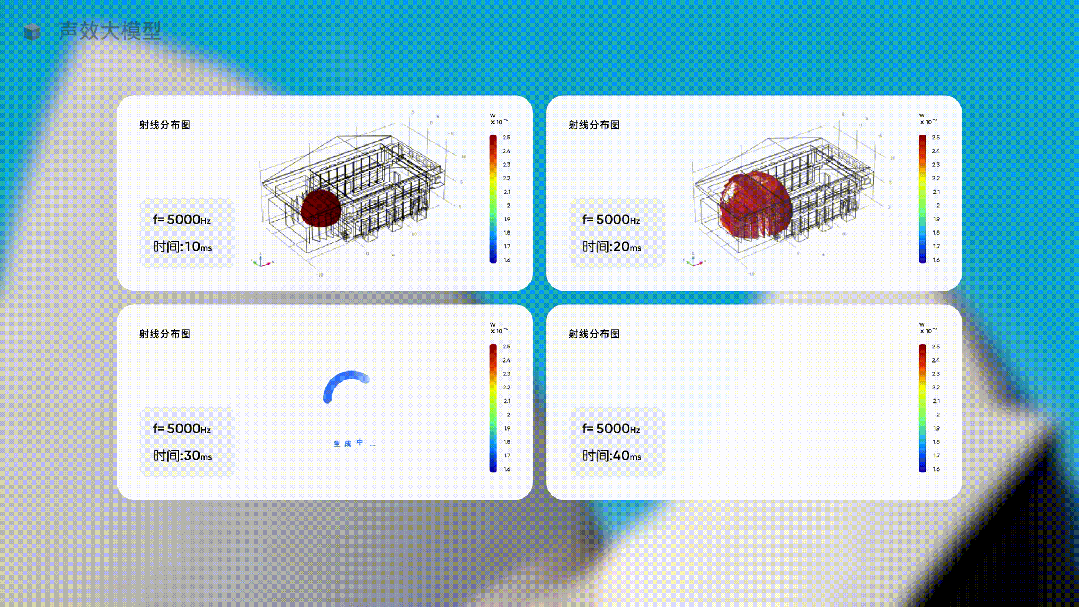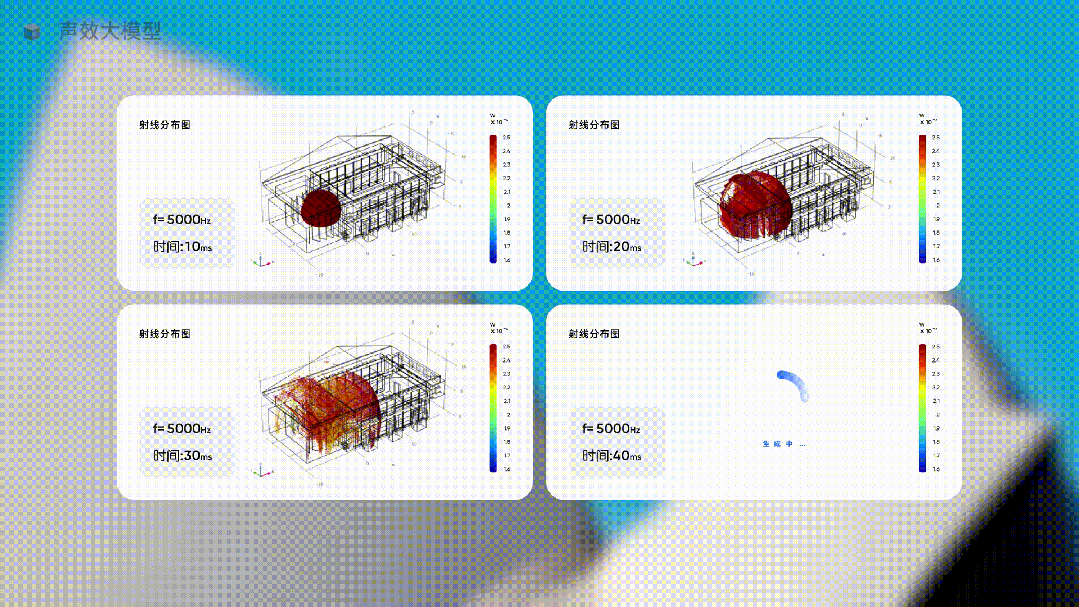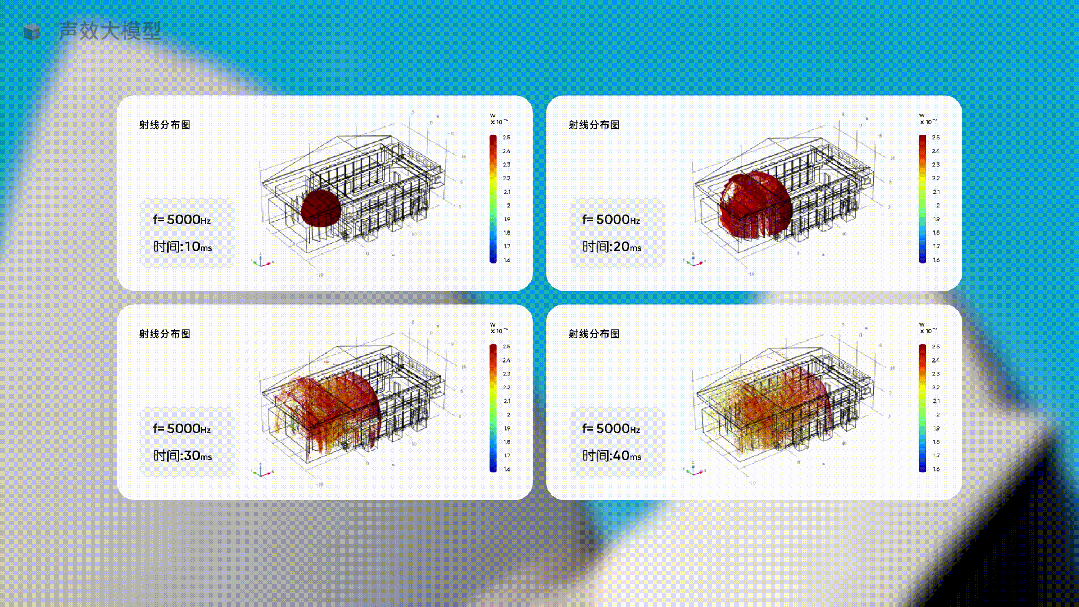
這種生成聲音體驗,完全無法用預測下一個單詞的方式,但在使用大量聲音行業的專有形態和特殊的數據訓練一個行業大模型后,就這樣被生成了。
而要開發這樣的模型,一個重要前提顯然是把主動權交給各行各業的從業者,讓專業的知識和數據發揮作用。
他們需要的可能不是一個傳統的大語言模型,不是基於大語言模型微調行業數據,而是真正基於自己行業里不同形態的數據訓練出的基座大模型。
第四範式的AIOS 5.0可以接受各種各樣的“X”,再基於這些X構建對應的垂直行業大模型,以他們的話說——“種瓜得瓜,種豆得豆。”語文模型解不了數學題。
其實,這樣的思路已經被越來越多的重要公司所接受。就連OpenAI也不認為最終會有一個萬能的大模型來解決一切問題。OpenAI COO最近在一場論壇上表示,“你當然不需要一個一體化模型來解決所有問題。人們應該根據具體使用場景動態調用不同的模型,從而更好地分配智能資源。”
所以,不要被ChatGPT和Sora 所局限了,“Predict the next X”的X應該有更多的可能性。而這些可能性只會從各個行業里發芽生長起來,當它們連成一片,AGI可能會更快到來。