所有語言











分享
谷歌DeepMind發布Gecko:專攻檢索,與大7倍模型相抗衡
巴比特_AIGC第一梯队287天前
文章來源:機器之心

圖片來源:由無界AI生成
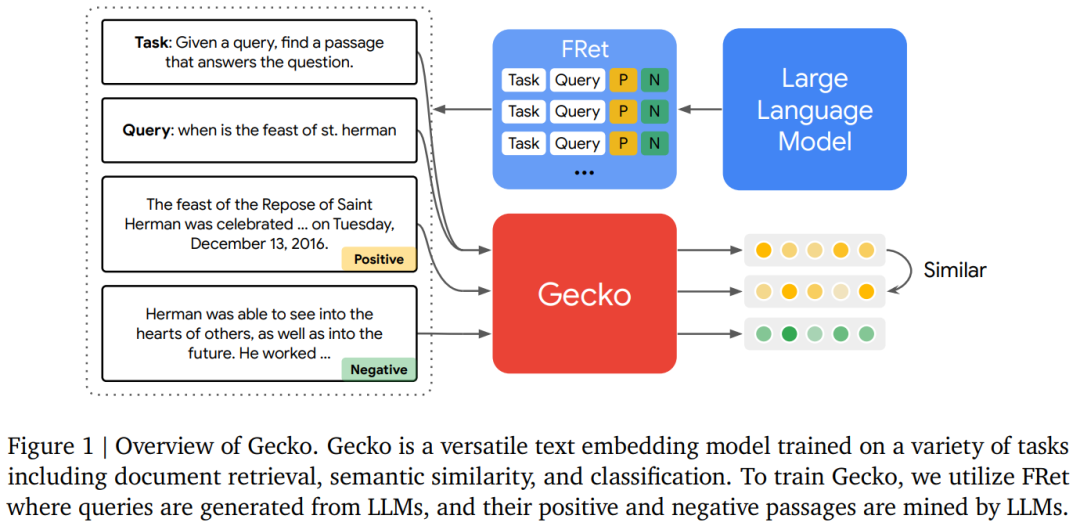
Gecko 是一種通用的文本嵌入模型,可用於訓練包括文檔檢索、語義相似度和分類等各種任務。
文本嵌入模型在自然語言處理中扮演着重要角色,為各種文本相關任務提供了強大的語義表示和計算能力。
在語義表示上,文本嵌入模型將文本轉換為高維向量空間中的向量表示,其中語義上相似的文本在向量空間中距離較近,從而捕捉了文本的語義信息,這種表示有助於計算機更好地理解和處理自然語言;在文本相似度計算上,基於文本嵌入的向量表示,可以輕鬆地計算文本之間的相似度,從而支持各種應用,如信息檢索、問答系統和推薦系統;在信息檢索上,文本嵌入模型可以用於改善信息檢索系統,通過將查詢與文檔嵌入進行比較,找到最相關的文檔或段落;在文本分類和聚類上,通過將文本嵌入到向量空間中,可以進行文本分類和聚類任務。
不同於以往,最近的研究重點不是為每個下游任務構建單獨的嵌入模型,而是尋求創建支持多個任務的通用嵌入模型。
然而,通用文本嵌入模型面臨這樣一個挑戰:這些模型需要大量的訓練數據才能全面覆蓋所需的領域,研究主要集中在使用大量的訓練示例來解決所面臨的挑戰。
LLM 的出現提供了一種強大的替代方案,因為 LLM 包含跨各個領域的大量知識,並且被認為是出色的小樣本學習者。最近的研究已經證明了使用 LLM 進行合成數據生成的有效性,但重點主要是增強現有的人類標記數據或提高特定領域的性能。
這就促使研究者開始審視這一問題:我們可以在多大程度上直接利用 LLM 來改進文本嵌入模型。
為了回答這一問題,本文來自谷歌 DeepMind 的研究者提出了 Gecko,這是一種從 LLM 中蒸餾出來的多功能文本嵌入模型,其在 LLM 生成的合成數據集 FRet 上進行訓練,並由 LLM 提供支持。
通過將 LLM 的知識進行提煉,然後融入到檢索器中,Gecko 實現了強大的檢索性能。在大規模文本嵌入基準(MTEB,Massive Text Embedding Benchmark)上,具有 256 個嵌入維度的 Gecko 優於具有 768 個嵌入尺寸的現有模型。具有 768 個嵌入維度的 Gecko 的平均得分為 66.31,在與 7 倍大的模型和 5 倍高維嵌入進行比較時,取得了相競爭的結果。

論文地址:https://arxiv.org/pdf/2403.20327.pdf論文標題:Gecko: Versatile Text Embeddings Distilled from Large Language Models
方法介紹
Gecko 是一個基於 1.2B 參數預訓練的 Transformer 語言模型,該模型經歷了兩個額外的訓練階段:預微調和微調。
預微調
該研究使用兩個預微調數據集。首先是使用 Ni 等人提出的大規模社區 QA 數據集,該數據集包括來自在線論壇和 QA 網站的文本對。接下來,研究者從 Web 上抓取標題 - 正文文本對,這些文本對可以從網站上獲得。
對大量無監督文本對進行預微調已被證明可以提高小型雙編碼器在各種下游任務中的性能,包括文檔檢索和語義相似性 。預微調階段的目標是讓模型接觸大量的文本多樣性,這對於訓練緊湊型文本嵌入模型是必要的。
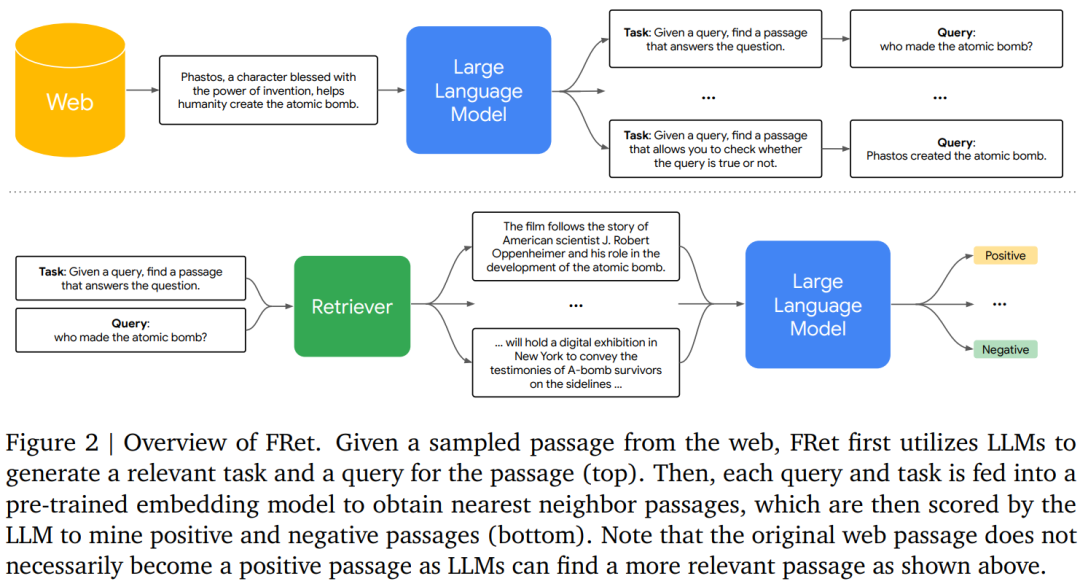
FRet :兩步蒸餾
使用 LLM 生成 FRet 的兩階段方法。一般來講,訓練嵌入模型的傳統方法依賴於大型的、手動標記的數據集。然而,創建此類數據集既耗時又昂貴,並且常常會導致不良偏差和缺乏多樣性。在這項工作中,本文提出了一種生成合成數據來訓練多任務文本嵌入模型的新方法,該方法通過兩步蒸餾可以全面利用 LLM 掌握的知識。生成 FRet 的整體流程如圖 2 所示:
統一微調混合
接下來,本文將 FRet 與其他學術訓練數據集以相同的格式結合起來:任務描述、輸入查詢、正向段落(或目標)和負向段落(或干擾項),從而創建一種新穎的微調混合。然後,本文使用這種混合與標準損失函數來訓練嵌入模型 Gecko。
除了 FRet 之外,學術訓練數據集包括:Natural Questions 、HotpotQA、FEVER、MedMCQA、MedMCQA、SNLI、MNLI 以及來自 Huggingface 的幾個分類數據集。對於多語言模型,本文添加了來自 MIRACL 的訓練集。所有數據集都經過預處理,具有統一的編碼格式,包含任務描述、查詢、正向段落和負向段落。
實驗
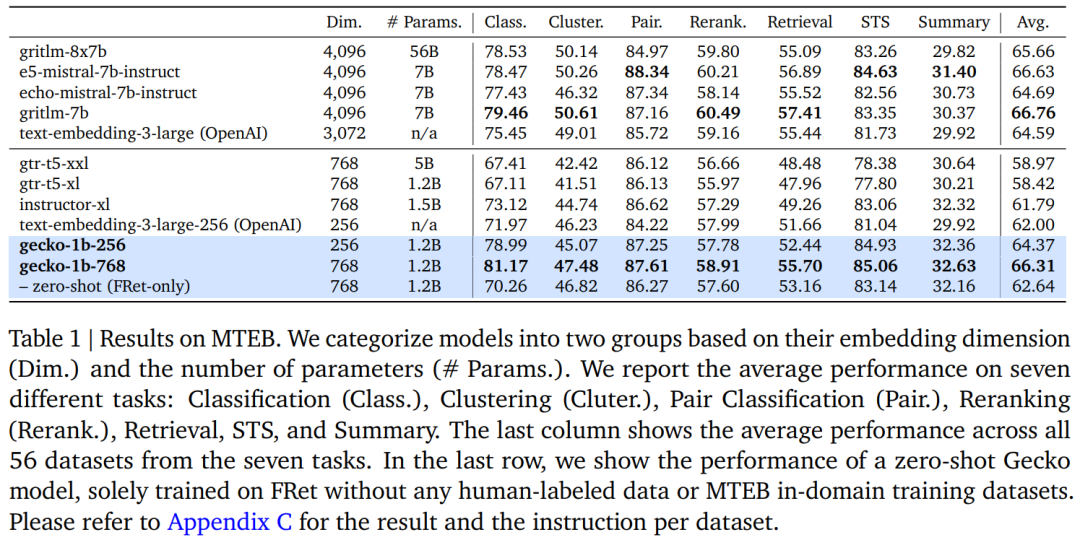
該研究在 MTEB 基準上評估了 Gecko。表 1 總結了 Gecko 和其他基線的比較結果。
Gecko 在每個文本嵌入任務上都顯著超越了所有類似大小的基線模型(<= 1k 嵌入尺寸,<= 5B 參數)。與 text-embedding-3-large-256(OpenAI)、GTR 和 Instructor 研究相比,Gecko-1b-256 性能更好。Gecko-1b-768 通常可以匹配或超過更大模型的性能,包括 text-embedding-3-large (OpenAI)、E5-mistral、GRit 和 Echo 嵌入。值得注意的是,這些模型都使用 3-4k 嵌入維度並且參數均超過 7B。此外,該研究還觀察到 Gecko 在分類、STS 和摘要方面達到了新的 SOTA 水平。
多語言檢索結果。表 2 總結了 Gecko 和其他基線在 MTEB 上的性能比較。
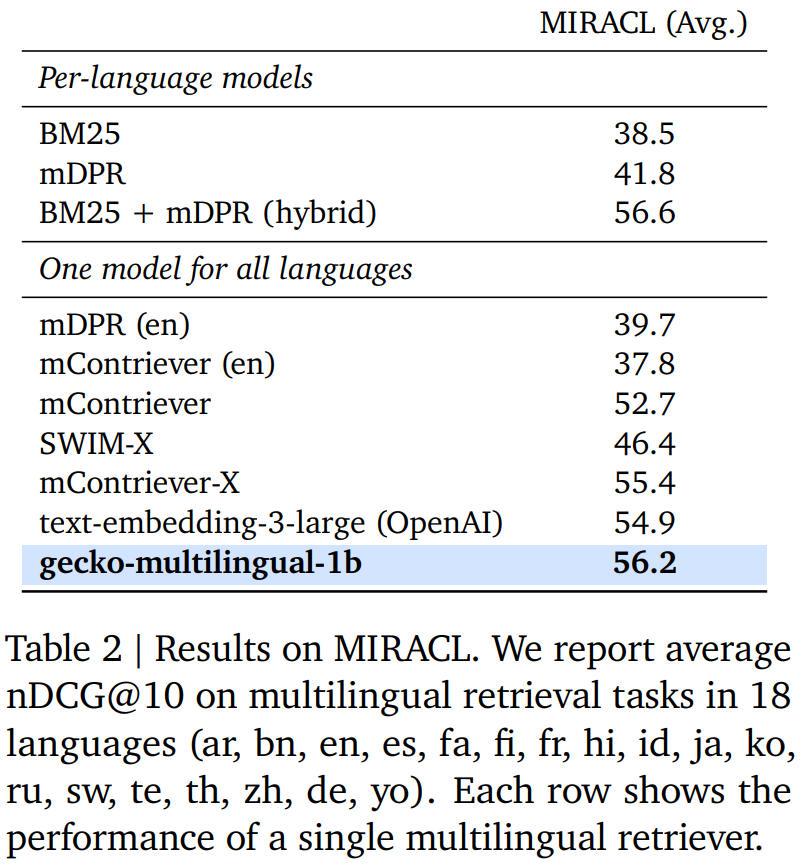
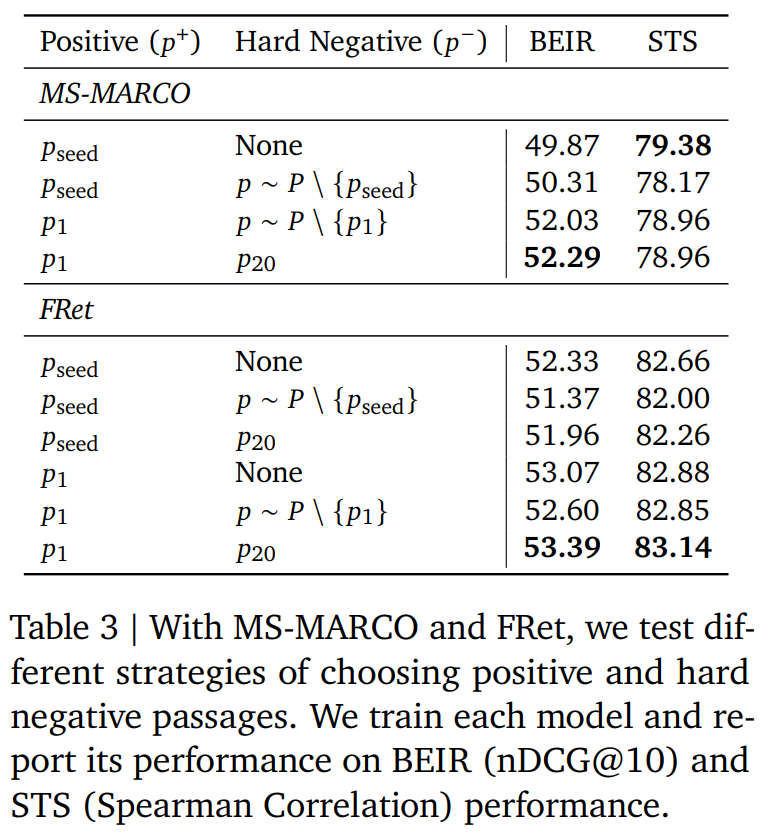
表 3 總結了不同的標記策略用於 FRet 的結果,實驗過程中使用了不同的正樣本和負樣本段落。從結果可以發現使用 LLM 選擇的最相關段落總是優於使用原始段落。表 5 也說明了這種情況經常發生。
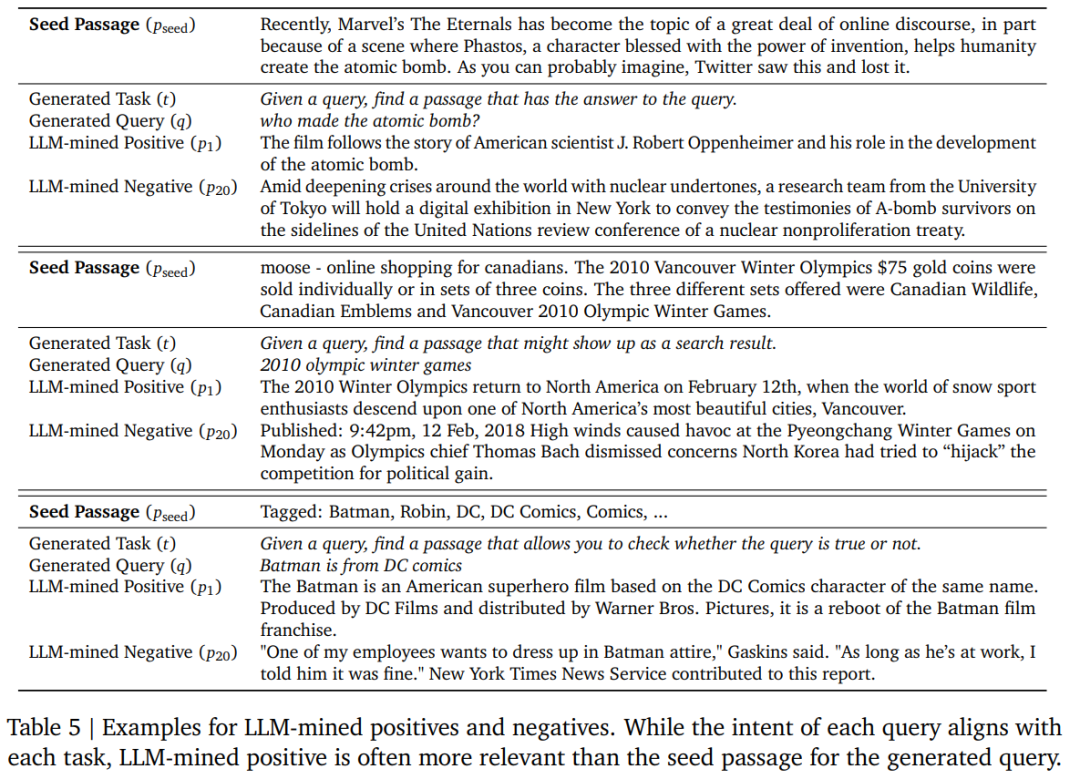
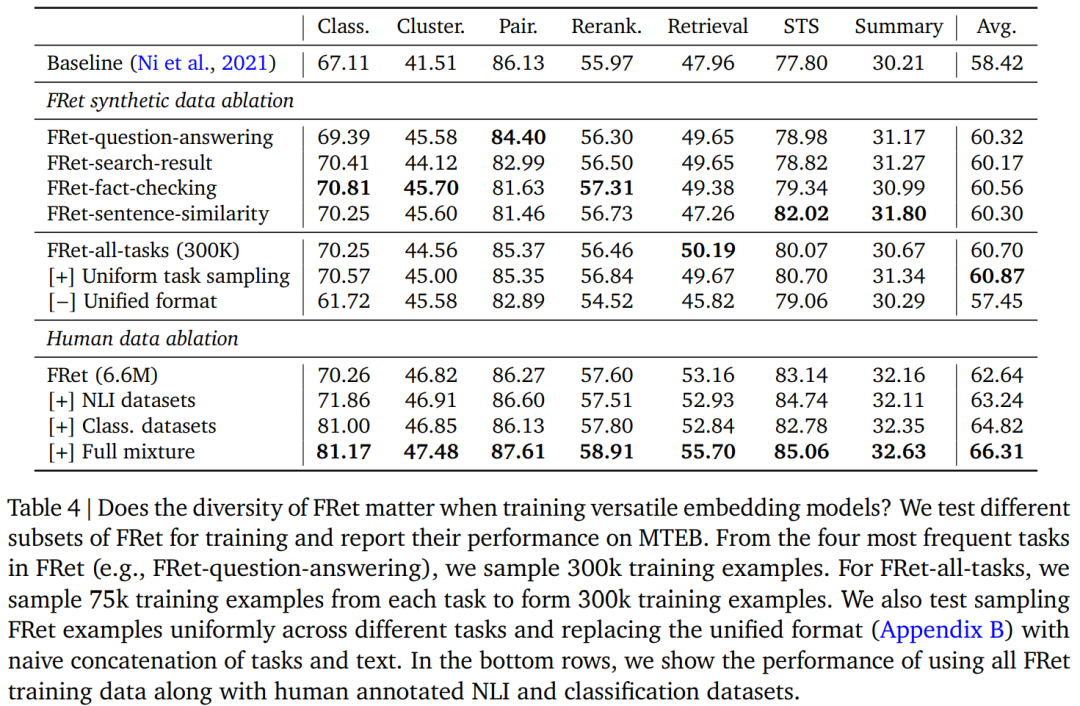
FRet 提供了對多種任務的查詢結果,包括問答、搜索結果、事實檢查和句子相似度。表 4 測試了 FRet 的多樣性如何影響 MTEB 中任務之間的模型泛化性。首先,該研究使用來自特定任務(例如,FRet 問答)的 30 萬個數據來訓練各個模型。此外,研究者還使用原始採樣分佈或均勻採樣分佈從所有四個任務中抽取的 300k 樣本(每個任務 75k;FRet-all-task)來訓練模型。觀察到 FRet-all-tasks 模型的卓越性能,特別是當任務被均勻採樣時。該研究還發現統一格式顯著影響嵌入的質量,因為它有助於模型更好地分離不同的任務。
表 4 的最後幾行展示了 Gecko 如何學習更好的語義相似性和分類。
了解更多內容,請參考原論文。