所有語言











分享
大模型時代的芯片,要如何造?
巴比特_AI第一视角268天前
文章來源:鋅產業

圖片來源:由無界AI生成
4月16日,李彥宏在百度AI開發者大會上給出了文心一言經歷2023年百模大戰後的戰況數據:
用戶數突破2億,服務企業8.5萬家,AI原生應用數超過19萬。
另外,他還透露,百度內部每天新增代碼有27%是由Comate(AI代碼助手)生成。
作為國內布局大模型最激進的互聯網巨頭之一,百度給出的這組數據,印證了大模型對於互聯網公司帶來的巨大影響。
實際上,大模型帶來的影響遠不止於此,李彥宏說,“未來開發應用將會像拍短視頻一樣簡單。”
或許是身處這波變革的漩渦之中,也或許是錯失過雲計算那波時代紅利,李彥宏針對大模型發表的言論一直都很激進。
無論大模型能否像李彥宏預期的那樣顛覆互聯網時代的生產模式,一個不可忽視的事實是,這波大模型浪潮背後,本質上依然是算力之爭。
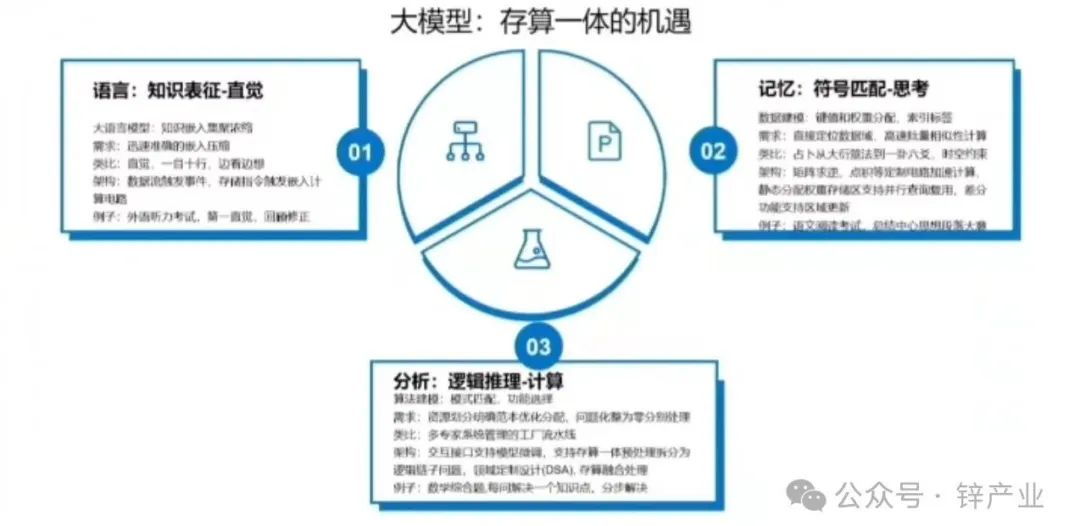
要想在緩緩開啟的大模型時代獲得先機,訪存密集、近存計算、類腦計算、存算一體等先進制式芯片的研發,是繞不開的競爭焦點。
就在上周,在第十三屆吳文俊人工智能科學技術獎頒獎典禮的系列活動上,進行了一場關於大模型時代芯片產業發展的圓桌討論。
在這次圓桌上,中國科學院自動化所研究員&中科南京人工智能創新研究院副院長程健、中國科學院微电子所研究員尚德龍、上海科技大學教授哈亞軍、北京憶芯科技有限公司首席架構師黃好城四位芯片領域專家就:
1、大模型需要怎樣的雲邊端芯片?
2、機器人需要怎樣的芯片來實現通用人工智能?
3、大模型在芯片設計中有怎樣的應用?
4、芯片產業需要怎樣的生態?
這四個關鍵問題展開了一場激烈討論。
本文就此次圓桌討論內容進行了不改變原意的整理,以供大家參考學習。
01
大模型時代的雲邊端芯片
問:大模型時代,雲、邊、端芯片分別具有怎樣的發展機遇和挑戰?
程健:要回答這個問題,我們先要看,今天所謂的大模型和過去傳統模型到底有什麼區別。
這其中有很多區別,但是沒有太多本質區別,特別是在芯片架構上沒有太多區別。
首先是雲端芯片,我們看今天英偉達的GPU,它是通過不斷堆顯存、拓寬帶寬來提升性能,除了工藝改進外,更多是通過增加硬件成本來提升算力。

對於我們來說,要想彎道超車,就要看能否通過存算一體、三維堆疊等方式,探索出一些新的路徑。
雲端追求的是奧運精神,更快、更高、更強,在邊緣和終端側,和雲端又有着不同的場景和需求。
在邊緣和終端側,由於受到體積、成本、功耗等限制,無法追求更高、更快、更強,尤其還有不同的場景和應用需求,這時給我們做芯片其實提供了更多機會。
例如很多團隊將模型和算法做到一起,有的芯片架構也變了,例如ASIC模式等。
這其中能做的東西、需要定製化的東西很多,也有更多的機會。
尚德龍:我同意程老師的見解,大模型需要高算力,這是挑戰也是機遇。
大模型本質上是生成式AI模型,生成式AI模型的一大缺陷是不能生成知識,不能生成知識要如何展現通用智能,這是我要提出的一個問題。
從雲邊端的機遇上來看,不能只看芯片,還要結合算法來研究。
類腦計算本身是一個非常大的系統,我們是否可以從現有的算法和類腦算法融合來實現通用人工智能,這是一個值得思考的問題。

另一方面,類腦計算的一個重要出發點是高效,人腦的功率不到20瓦,一個饅頭頂一天沒有問題;
一台機器的功率有幾百瓦、上千瓦,我們是否可以從算法設計理念上,通過融合來實現雲邊端的一些創新設計思路。
現在來看,無論是先進的架構、先進的封裝,還是Chiplet,即便是將眾多芯片封裝在一起,功耗依然是個問題,在雲邊端用起來還會有一些限制。
這就需要一些新的設計方法、設計理念,來促進這些領域的發展。
哈亞軍:我們現在進入到了一個通用智能時代,很多時候,大家希望用一個平台解決通用的問題。
實際上,在各類模型出現之前,計算架構也曾有過同樣的問題——究竟應該用一個通用的計算平台,還是用專用的計算平台來解決問題?
從我的經驗來說,通用芯片市場很大,難度也很高,所以只有大公司、大團隊、大資本有能力進入這條賽道,因為很多東西搞通用的話,你需要有生態、工具和應用。

專用芯片的好處是應用比較明確、對象場景比較清晰,你可以找到一些約束條件,針對約束條件不斷做優化,對生態等方面的要求相對少一些,這更適合高校和小公司來做。
從過去計算平台的發展經歷來看,玩通用活下來的都是大公司,小公司在專用計算平台上有更多機會。
同樣的經驗也適用於大模型技術發展。
大模型強調通用,但是從模型設計角度來看,一個通用大模型很難通吃天下,在很多場景下,一些專用(小)模型依然會有一席之地。
黃好城:我們公司成立於2015年,從存儲芯片做起。
隨着大模型的出現和AI技術的發展,我們每款芯片都嵌入了一些AI相關功能,例如存算一體的融合,這項技術的出現為我們公司和國內很多非大模型方向的芯片公司帶來了機遇和挑戰。
就機遇來看,大模型對所有計算、存儲和傳輸有了更高的要求,例如存儲的數據量變大,包括雲端、邊緣端存儲的內容都變多了,帶寬要求也更高了,延時要求也更高了。
就挑戰來看,一方面,大模型對服務器的主控芯片要求很高,消耗的能源、資源、碳排放量都很大,這反饋到芯片設計中,就成了究竟要以怎樣的方式設計芯片的架構和每個模塊。
從我們企業來看,在功耗設計上,每一款芯片從工藝選擇、IP選型,再到每個模塊的低功耗設計,對我們都提出了更高的要求,由此降低的能耗,也將提升我們的產品競爭力。
與此同時,隨着大模型應用的研發,我們對存儲內容的安全性也有了更高的要求。
我們存進去的資料是否有被很好地加密保護,是否能被竊取、能被探測到,我們研發芯片在做數據安全保護時,也隨着國密一級、二級、三級的提出,相應的要求也越來越高。
02
通用機器人,需要怎樣的芯片?
問:如何設計機器人智能芯片,推動通用人工智能發展?
程健:設計芯片,首先要知道芯片要解決的問題是什麼。
機器人需要解決的是感知、規劃、決策、控制幾方面的問題。
這幾個方面遇到的問題、需要的算法和軟件有一些區別。
例如,我們原來很多機器人中做控制都是基於MCU來做的,進行一些簡單的計算,決策很多都是由人工編好的,所以也很簡單。

但是今天在大模型時代,原來很多手工編寫的規劃、決策算法,今天要用大模型來生成,這就對用於機器人的芯片提出了更高的要求:
第一,端側主控芯片需要更大的算力;
基於大模型實現感知、認知,要求端側主控芯片能夠提供更大的算力。
第二,端側算力能否基於一個芯片實現;
端側要求的高算力與雲端的高算力不同,雲端需要做大量決策和規劃,端側的計算和在GPU中做張量計算不同,我們是否可以將這些端側的計算需求放在一個芯片上來實現,而不是分開用幾個芯片來實現。
第三,機器人需要更多智能性和自主性。
除了感知、規劃、決策、控制,我們看到越來越多機器人需要有更多智能性和自主性。
例如機器人現在可以不斷地和環境交互、自主學習,這就需要大量基於強化學習的計算,這樣的計算又和張量計算不同,現在強化學習有很多分支,有的基於transformer方式來實現,有的以傳統的馬爾可夫方式來實現。
這種需要大量計算、採樣、迭代的機器人應用,對於芯片提出了很多新需求。
尚德龍:具身智能機器人更強調的是擬人,現在市面上的機器人顯然不具備這樣的特性。
可以看到,酒店裡的配送機器人、園區里的清潔機器人在遇到人時,一般都會先停下來,然後再緩慢地繞行,行動非常遲緩、給人的感受很不好。

想做到更好的感受,感知、決策就要非常快,如果按照現在的計算體系,毫無疑問,我們需要的是大算力。
如果不考慮設計方法,大算力等同於大功耗,現在電池技術的發展還趕不上計算的發展,這樣的技術路徑顯然很難走下去,這就需要我們有新的創新。
類腦計算、大模型等都是在新的創新。
現在的計算、決策、智能,我自己的一個“偏見”是,這是一個計算的感知、計算的決策、計算的智能,這些都非常耗能。
是否可以做一個真正和人類似的智能體,這是機器人未來發展需要考慮的一個問題。
尤其是未來的具身智能機器人,例如,未來如果居家老人對康養機器人的體驗非常不好,這種機器人市場也不會很好。
我是做類腦計算的,我還是很推崇將現有的計算體系和類腦計算體系融合起來,以此尋找一條新的突破口。
哈亞軍:針對這個問題,我提兩點感受:
第一,通用智能要與機器人結合,就意味着芯片研究的前沿重點要慢慢從雲端向邊緣端發展,邊緣端芯片的研究會變得越來越重要。
因為機器人本質上是一個邊緣端平台。
從最近產業界的發展可以看到,很多企業,特別是原來做算法的企業都在布局芯片產業,相信機器人廠商未來在邊緣端也會有更多布局。
第二,雖然大模型似乎可以解決機器人遇到的所有問題,但是我個人並不這麼認為,無論是機器人還是無人車,算法無法解決它們遇到的所有問題。
機器人對決策的準確性要求有時會很高,即便機器人做到了99.9%的決策準確度,但在機器人真正與人打交道時,某些場景我們對準確度的要求可能是100%。
這時,我們就不能完全依賴智能計算。
在智能計算出來之前,我們還是要有傳統算法。
我的看法是,傳統算法不能丟,未來世界中,傳統算法和智能算法將會共存,一起通過各種方式提高決策準確性。
黃好城:人類的聰明程度依賴於之前學習到的知識,我們大腦里會將之前學到的知識存儲為記憶,是否可以將之前的記憶用好決定了人類的聰明程度。
例如,當老人患上老年痴呆症、失去記憶后,他的智能也就無法體現。
我們在智能機器人上會不斷感知周圍環境,做圖像、視頻學習,在這個過程中,存儲的大量數據有沒有被很好地利用,在雲端和邊端有沒有被很好地訓練,這關乎機器人是否足夠智能。
機器人在很多應用場景或處理突發情況時,不是一開始就能很好地模擬和訓練出來,每一個端側設備,特別是智能機器人設備,要想進入千家萬戶,就需要不停地學習和進步,通過對本地存儲資源高效利用實現智能化。

我們之前提到的近存計算,通過對邊緣端存儲的數據進行再分類和預處理,甚至將一些類決策放到邊緣端、靠近存儲的計算芯片中,一方面可以帶來更低的功耗收益,讓機器人續航有更好的表現,另一方面可以減少機器人對主計算單元依賴。
03
將大模型用到芯片設計里
問:AI算法如何應用到芯片設計中?
黃好城:我們確實看到AI已經開始輔助工程師寫代碼,不過,在芯片設計流程中,現在的AI技術不是取代工程師寫代碼,而是輔助工程師寫代碼。
AI技術從設計方法學上帶來了很多輸入,工程師省掉了寫細節的、重複模塊的代碼,可以換成AI幫你生成。
工程師更多使用AI輔助工具后,就會有更多精力參与到更高級的工作中,兼任一些架構師的角色。
他們不再需要做設計驗證的角色,更多是做A、B、C方案的綜合篩選,把每個芯片設計的模塊化做多套方案比較,這樣可以做更好的PPA(Performance、Power、Area)評估,而不是放到最後,等架構師拿到芯片設計方案后,再去做數據流、性能的仿真驗證。
這對芯片前端設計有很好的提升。
當然,芯片不只有前端設計,還有後端物理實現。
在後端物理實現上,AI也有很多應用,因為物理實現上有很多自動布局布線的工作,原來都是靠EDA軟件來實現的。

我們現在在和國內一些廠商一起做AI算法融合,用來提升我們自動布局布線效率,嘗試各種擺放方式,讓芯片面積做得更好更合理。
哈亞軍:這個問題總結而言就是,AI for IC、IC for AI。
我們看到,現在國內外很多EDA公司確實在整個EDA flow的各階段考慮讓人工智能改變此前的設計方法或工具,我們可以看到很多這樣的例子。
另外,IC也可以加速智能EDA工具發展。
尚德龍:我是國內比較早接觸EDA工具的人。
實際上,新技術發展一直都在不斷融合到芯片設計流程中,現在人工智能技術的發展也會融合到IC設計流程中。
不過,包括IBM、Intel,他們核心的X86芯片並不是基於EDA工具來做的,而是他們7-8人的一個小團隊來做的。
所以我的觀點是,AI可以賦能IC,從技術發展角度來看,AI也確實逐漸在增強EDA工具的效率和水平,但是如果要讓AI去替代設計者做包羅萬象的芯片設計工作,還有待時日。
程健:我比尚老師更激進,我個人認為,AI技術至少在芯片設計領域一定會完全取代人類。
之所以這麼說,是因為,參考人工智能技術發展經歷,AI能夠做好的是下圍棋、打遊戲這樣有明確規則的事。
以下圍棋為例,AI不僅會下圍棋,甚至連對手怎麼下的都看得一清二楚,這類場景,AI往往比人做得更好。
我們再來看芯片設計,芯片設計的目標也很明確,關鍵就是面積、功耗、功能,這些都是可以規則化、量化的目標,而芯片的布線、布局也有清楚的要求。
從這個角度來看,我認為,AI做芯片設計必然會取代人類,而且一定會比人類做得更好,當然,這需要時間。
我們現在AI做布局、布線已經做得很不錯了,但是做芯片設計還有些問題,有哪些問題呢?
我舉三個例子:
第一,基於神經網絡或transformer的AI模型,現在在執行任務的精確性上還有欠缺。
芯片設計往往需要很高的精確度,中間有一個小BUG,整個芯片就廢掉了,將來如何將精確性在AI芯片設計中體現,讓它越來越精確,這是個有待解決的問題。
第二,需要將工程師的經驗、知識轉化為可量化的數據。
做芯片設計很多是靠工程師長期積累的經驗,這些經驗有些是知識,是可以描述的,有些是不能描述的,這就需要將這些經驗、知識轉化為可以讓AI學習的可量化、可規則化的數據。
第三,芯片設計的數據難獲取。
AI下圍棋下得好,是因為DeepMind在設計AlphaGo的時候收集了大量棋譜,可以說,沒有AlphaGo沒學過的棋譜。

在芯片產業中,很多數據是無法在互聯網上檢索到的,開源的項目也很少,很多芯片公司也只能拿到一部分數據,這對於AI學習來說會是一個很大的問題。
我認為,如果能將這三個問題解決掉,未來AI一定可以取代人類做芯片設計。
04
AI芯片,重在生態
問:如何從技術創新、人才培養、市場需求三方面,共同促進芯片生態建設?
黃好城:我認為,最重要的是市場需求。
客戶、消費者對產品有需要才會花錢買單,有了這些資金的支持才能推動企業發展,帶動產學研合作,大家也才有一個良好的就業環境,這是一個供需關係。
國內現在一個很好的趨勢是,各大甲方都更願意用國內的芯片和存儲類產品了,已經不僅僅是嘗試,而是會有大規模出貨。
對芯片公司而言,我們研發新一代主控芯片時,也很願意用國內IP公司提供的IP產品,我們現在的控制器、Chiplet技術,甚至RISC-V CPU已經在用國內供應商。
我們用了國內供應商的CPU后,也在幫他們調教他們的CPU,給他們提了很多建議。
就學校而言,每年有更多優秀畢業生帶着在學校掌握的AI技術進入公司,對於企業來說也是很好的資源,這才能讓我們整個生態不斷髮展起來。
哈亞軍:我重點說一下人才培養。
無論是芯片還是人工智能,這兩個產業有一個特點是,某種意義上都是產業界領先於學術界,對人才培養有很多特殊的要求。
就人才培養而言,過去是將更多注意力放到培養學生上,而要將這件事做好,其實教師也需要培養,所以我們需要建立一整套新工科培養體系,這套體系裡既能培養學生,也能培養老師。
從教師培養角度來說,要每隔幾年,讓老師到企業中待幾個月,了解企業實際進展和需求,包括老師在學校講課的講義,學校的企業導師可應該及時給出反饋,讓他們看看現在這些教材是否符合企業需求。
從學生培養角度來說,要能增加流片的機會,增大學生去企業實習、增加學校和企業一起做項目的機會。
學校和企業的定位還是有很大不同的,企業追求盈利,學校追求科研,雙方合作也需要一個成熟的合作模式。
尚德龍:這個問題我感觸很深,但是我想強調的只有兩個字——生態。
產品的生態,科研的生態,人才培養的生態,一個良好的生態才能真正把這件事做起來。
程健:接着尚老師講的生態,我想說,其實芯片從設計、生產、應用到反饋,形成一個正向反饋很重要。
這其中一個很重要的環節是要有人用,只有用起來才能有正向迭代。
芯片越沒人用越難用,越難用越沒人用,這會形成一個惡性循環。
如何用起來?
這個問題不是哪一家企業、哪一所高校,甚至哪一個環節能解決的,這是一個需要從整個生態全局考慮的問題。
需要我們從人才培養,教育界、企業界一起聯合起來,給我們國產芯片一些機會。
我們的硬件生態是否可以通過國家和企業一起推動,將芯片很便宜或者免費送給高校做人才培養用起來,這是從生態層面我認為值得考慮去做的一個問題。
第二,任何行業要做好人才培養,很重要的是要“有利可圖”。
今天這麼多人做AI,其實本質上是因為今天大家在AI領域有很多工作機會,企業也能賺到錢。
芯片其實更需要錢,需要更多時間,擔更多風險,走更長的路才可能做好。
所以一定要有資金投入,企業和個人都能在這個過程中賺到錢,才能將這件事做好。
我想,只有BATH,以及國企央企,這些真正有資源、有應用場景的企業加入進來,才能做好大模型時代的芯片。