所有語言











分享
突發!Stable Diffusion 3,可通過API使用啦
巴比特_AI第一视角266天前
文章來源:AIGC開放社區

圖片來源:由無界AI生成
4月18日,著名開源大模型平台Stability.ai在官網宣布,最新文生圖模型Stable Diffusion 3 (簡稱“SD3”)和 SD3 Turbo可以在API中使用。
據悉,本次繼續由知名API管理平台Fireworks AI提供服務。與前兩代相比,SD3除了生成的圖片質量更高之外,可以更好地理解提示文本中嵌入到圖片中的文字。
例如,一個色彩繽紛的魔法世界,天空的中央寫着“歡迎來到魔法世界”。
前兩個模型版本可能無法將“歡迎來到魔法世界”精準嵌入到圖片的指定位置或出現扭曲的文字,而SD3可以輕鬆實現。
此外,SD3的模型權重將很快向Stability AI會員提供,可以在本地部署、運行SD3。
API地址:https://platform.stability.ai/docs/api-reference?_gl=1*1ldjred*_ga*ODY1NjAxMzA1LjE3MDcyNTYwMTM.*_ga_W4CMY55YQZ*MTcxMzM5NDE4OS40NC4xLjE3MTMzOTQyNTUuMC4wLjA.#tag/Generate/paths/~1v2beta~1stable-image~1generate~1sd3/post

Stable Diffusion 3架構簡單介紹
今年2月22日,Stability.ai在官網首次展示了SD3並開啟候補測試。隨後3月5日在arxiv上公布了其論文。
根據其論文介紹,SD3與前兩代相比最大技術創新在於,使用了MM-DiT和Flow Matching兩種方法來增強模型的輸出、訓練、優化等,同時支持文本或圖像作為提示實現多模態能力。

通常多數文生圖模型在生成的過程中,只考慮圖像本身而沒有充分利用文本信息,所以,輸出結果時經常出現“驢頭不對馬嘴”的情況,甚至是一些無法理解的亂碼或者扭曲的圖像。
而MM-DiT通過結合Transformer的自注意力機制強大的文本和圖像序列處理能力,幫助模型在生成圖像時能與文本實現更好的匹配。
當用戶輸入文本或圖像提示時,首先被轉換為嵌入表示。文本通過預訓練的文本模型編碼,而圖像則通過預訓練的自動編碼器轉換為潛在空間表示。
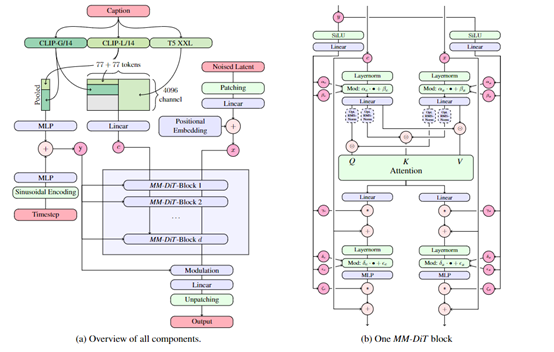
MM-DiT會使用一種調製機制來整合時間步和文本條件信息,會將時間步和文本嵌入與圖像的潛在表示進行整合。
接着,MM-DiT會利用一系列的調製注意力和多層感知力進一步混合文本和圖像特徵。這些塊允許模型在保留各自模態特徵的同時,進行跨模態的信息交流。
為了幫助SD3更好地處理多模態數據,MM-DiT採用了多頭注意力機制,允許模型在不同的表示子空間中并行處理信息。
這也是SD3能深度理解文本提示中的嵌入文字主要原因,MMDiT不僅能將文字轉換成圖片,還能確保圖片能夠反映出文字中的所有細節。
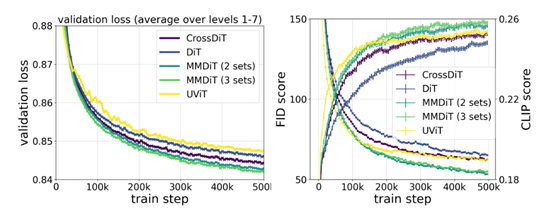
根據測試數據显示,與DiT、CrossDiT、UViT等方法相比,MM-DiT所有指標上表現都非常出色,並且在內部共享權重集。
Flow Matching是一種用於訓練Rectified Flow模型的方法,通過最小化生成路徑上的誤差來改善模型性能,同時幫助模型學習從隨機噪聲快速轉換到目標圖像。
在訓練過程中,Flow Matching會先定義一個從數據分佈到噪聲分佈的前向過程,這個過程通過一系列的時間步驟來模擬,每個步驟都對應着數據向噪聲的逐漸轉變。
接着,通過對每個時間步的噪聲樣本生成一個向量場,可以在概率空間中模擬數據到噪聲的轉換。
最後,Flow Matching通過最小化一個目標函數來優化生成向量場。該目標函數的作用是幫助模型預測的向量場和真實向量場之間的差異。優化的過程中會盡量減小這個差異,從而提高模型的生成圖像預測準確性。
關於SD3更詳細的技術解讀,小夥伴們可以查看論文。
SD3生成圖片展示
根據Stability.ai展示的效果,SD3生成的圖片有一些甚至比Midjourney更好,尤其是文字嵌入方面。
一座白色建築頂部放着一張紅色沙發。塗鴉強上寫着“城市最佳景觀”。

一個印有“他們說在這裏思考不好”的紙板箱,紙板箱很大,放在劇場舞台上。

半透明的豬,肚子里有一隻更小的豬。

一隻奶酪製作的螃蟹,在盤子中。

在山頂上有一位巫師創作了一幅令人驚嘆的藝術作品,他用魔法創造了文字"Stable Diffusion 3 API"。

本文素材來源Stability.ai官網、SD3論文,如有侵權請聯繫刪除