所有語言











分享
「用 AI 訓 AI」這事靠譜嗎?
巴比特_AI之势224天前
文章來源:機器之心
來源:節選自 2024 年 Week04 業內通訊

圖片來源:由無界AI生成
在大語言模型領域,微調是改進模型的重要步驟。伴隨開源模型數量日益增多,針對LLM的微調方法同樣在推陳出新。
2024年初,Meta和紐約大學等機構的研究者提出了一項「自我獎勵方法」,可以讓大模型自己生成自己的微調數據。研究者對 Llama 2 70B 進行了三個迭代的微調,其生成的模型在 AlpacaEval 2.0 排行榜上優於 Claude 2、Gemini Pro 和 GPT-4 等現有大模型。
獎勵模型能幹什麼?
大型語言模型通過以逐步思考鏈格式生成解決方案,解決需要複雜多步推理的任務。許多研究關注如何檢測和減少幻覺對於提高推理能力。其中,通過訓練獎勵模型以區分期望的和不期望的輸出則是一種有效的方法,獎勵模型可以用於強化學習流程或通過拒絕採樣進行搜索。如何有效地訓練可靠的獎勵模型至關重要。
OpenAI 提出了人類反饋強化學習 (RLHF) 的標準方法在 ChatGPT 發布時引起極大關注。該技術模型可以從人類偏好中學習獎勵模型,再凍結獎勵模型並結合強化學習訓練 LLM。通過使用人類偏好數據調整大語言模型(LLM)可以提高預訓練模型的指令跟蹤性能。但 RLHF 存在依賴人類反饋的局限性。
在此背景下,Meta 提出的「自我獎勵語言模型」(Self-Rewarding Language Models, SRLMs)是一種新型的語言模型,在訓練過程中利用自身生成的反饋來自我提升。自我獎勵語言模型不是被凍結,而是在 LLM 調整期間不斷更新,避免了凍結獎勵模型質量的瓶頸。
自我獎勵模型的核心思路是什麼?對比傳統獎勵模型有什麼優勢?自我獎勵語言模型(SRLMs)的核心思想在於創建一個智能體,該智能體在訓練期間集成了所需的全部能力,而非將任務分離為獎勵模型和語言模型。這種方法允許通過多任務訓練實現任務遷移,從而在預訓練和後續訓練中跟隨指令並生成響應。
Meta 等提出的自我獎勵模型具備雙重角色:一方面,它遵循模型的指令來生成給定提示的響應;另一方面,它也能夠根據示例生成和評估新的指令,進而將其添加到訓練集中。該模型建立在假設之上,即利用基礎的預訓練語言模型和少量的人工註釋數據,可以創建一個同時具備指令遵循和自指令創建能力的模型。
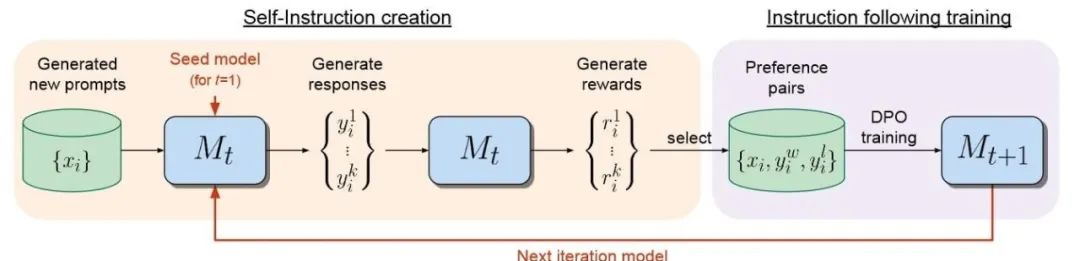
圖:自我獎勵語言模型的對齊方法含兩個步驟,(i)自指令創建:新創建的提示用於從模型 Mt 生成候選響應,該模型還通過“LLM作為法官”提示預測自己的獎勵。(ii)指令遵循訓練:從生成的數據中選擇偏好對,這些對用於通過DPO(確定性策略梯度)進行訓練,從而產生模型 Mt+1。然後可以迭代整個程序,從而提高指令遵循和獎勵建模能力。
這種自對齊能力使得模型能夠使用人工智能反饋(AIF)進行迭代訓練,提升自身組件的性能。自我獎勵模型的一個關鍵特點是其自指令創建機制,它不僅生成候選響應,還自行評估這些響應的質量,充當自身的獎勵模型,從而減少了對外部模型的依賴。這一過程通過“LLM-as-a-Judge”機制實現,即將響應評估任務轉化為指令遵循任務,而模型自身創建的 AIF 偏好數據則被用作訓練集。
在微調階段,模型同時扮演“學習者”和“法官”的角色,通過上下文微調進一步提升性能。整個過程是一個迭代的自對齊過程,通過構建一系列逐漸改進的模型來實現。
與傳統的固定獎勵模型不同,自我獎勵模型在語言模型對齊過程中不斷更新,從而避免了發展瓶頸,並提高了模型自我改進的潛力。相較於傳統獎勵模型,自我獎勵模型的優勢在於其動態性和自我迭代的能力。它通過整合獎勵模型到同一系統中,實現了任務遷移,允許獎勵建模任務和指令遵循任務相互促進和提升。
自我獎勵模型和 RLAIF 有關聯嗎?
RLAIF(Reinforcement Learning from AI Feedback)與自我獎勵模型在思路上存在明顯差異。RLAIF 採用了 AI 反饋強化學習的方法,使用 AI 而非人類來進行偏好標註,以此擴展強化學習的規模。具體來說,RLAIF 利用 LLM 生成的偏好標籤來訓練獎勵模型(RM),隨後使用該 RM 提供獎勵以進行強化學習。
Anthropic 在 2022 年 12 月發布的論文《Constitutional AI: Harmlessness from AI Feedback》中首次提出了 RLAIF 的概念,並發現 LLM 在某些任務上的表現甚至可以超越人類。而在 2023 年 9 月,谷歌發表的論文《RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback》進一步推動了 RLAIF 方法的發展。
RLAIF 的關鍵步驟之一是使用 LLM 來標記偏好。研究者利用現成的 LLM 在成對的候選項中標記偏好,例如,給定一段文本和兩個候選摘要,LLM 的任務是評判哪個摘要更為優秀。這種方法不僅提高了訓練效率,還解決了傳統 RLHF(Reinforcement Learning from Human Feedback)中因人類標註成本高昂和規模受限的問題。
RLAIF 通過 AI 反饋來增強強化學習的能力,使得模型能夠處理更大規模的數據集,同時降低了對人類標註的依賴。這種方法為訓練更高效、更大規模的語言模型提供了新的可能性,並有助於推動自然語言處理領域的進一步發展。
使用 AI 合成數據訓模型有風險嗎?最近還有誰正在做AI自我迭代?小模型監督大模型的方法好用嗎?
目前,模型訓練大部分的數據來自於互聯網,如 Twitter、GitHub、Arxiv、Wikipedia、Reddit 等網站。隨着模型的規模繼續增大,人們需要投喂更多的數據來訓練模型。在使用模型生成的數據來訓練新模型時,會產生「哈布斯堡詛咒」或稱「模型自噬」現象......