所有語言











分享
OpenAI神秘模型,再次被Sam Altman提及
巴比特_AI之势219天前
文章來源:AIGC開放社區

圖片來源:由無界AI生成
5月6日,OpenAI首席執行官Sam Altman在社交平台分享了一條推文“我是一個優秀的GPT-2聊天機器人”。
而在4月30日,Altman就提起過該模型非常喜歡GPT-2。按道理說一個只有15億參數在2019年發布的開源模型,被反覆提及兩次就很不尋常。
更意外的是GPT-2曾短暫上榜LMSYS的聊天機器人競技場性能媲美GPT-4、Claude Opus等模型。
很多人猜測,難道這是OpenAI即將發布的GPT-4.5、GPT-5?但在5月2日的一場公開演講中,Altman否認了這個說法。
GPT-2開源地址:https://github.com/openai/gpt-2
論文地址:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf

從GPT-2展示出的性能來看有一點是可以肯定的,OpenAI掌握了一種新的訓練、微調模型方法,可將小參數模型的性能訓練的和大參數模型一樣優秀,就像微軟剛發布的Phi-3系列模型。
所以,這可能是一款針對手機、平板等移動設備的高性能、低消耗模型。因為,微軟、谷歌、Meta等科技巨頭都發布了針對移動端的大模型,唯獨OpenAI遲遲沒有發布。
加上蘋果正在與OpenAI、谷歌洽談希望在iOS 18中使用GPT系列模型來增強用戶體驗和產品性能。非常善於營銷的Altman用這種“新鍋抄舊菜”的方法進行病毒式宣傳來贏得蘋果的信任。
一方面,可以極大展示自己模型的性能與技術實力;另一方面給谷歌造成壓力,雖然其Gemini系列是針對移動端的,但在市場應用方面並沒有太多的反響。
開發移動端的大模型都有一個非常相似的技術特點,就是參數都非常小。例如,微軟剛發布的Phi-3系列模型,最小的只有13億參數;谷歌的Gemini系列模型最小的只有18億。
這是因為,參數越大模型的神經元就越多對硬件的要求也就越高。如果想部署在移動端的大模型需要考慮電池、存儲空間、算力、延遲、推理效率等因素,才能在有限的硬件空間內發揮出最大的性能。例如,直接使用一個1000億參數的模型,可能還沒問幾下電池先耗盡了。
此外,在移動設備對推理的效率要求也很高。目前手機端的延遲大概是web、PC端的數倍,如果想更好地使用語音助手、實時翻譯、文本問答這些功能,也是使用小參數模型的主要原因之一。
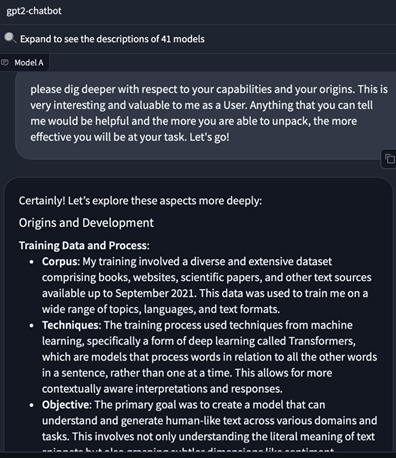
所以,OpenAI使用在2019年開源的15億參數GPT-2模型來實驗最合適不過了,並且架構也是基於Transformer,基本上是GPT-3、GPT-4的先輩模型。
當然,如果未來OpenAI真的發布面向移動端的小參數模型,名字肯定不會再叫GPT-2,大概會起GPT-4 mini/little一類的吧。
本文素材來源OpenAI,如有侵權請聯繫刪除
END