所有語言











分享
OpenAI、微軟、智譜AI等全球16家公司共同簽署前沿人工智能安全承諾
巴比特_AI领航员189天前
文章來源:機器之心

圖片來源:由無界AI生成
人工智能(AI)的安全問題,正以前所未有的關注度在全球範圍內被討論。
日前,OpenAI 聯合創始人、首席科學家 Ilya Sutskever 與 OpenAI 超級對齊團隊共同領導人 Jan Leike 相繼離開 OpenAI,Leike 甚至在 X 發布了一系列帖子,稱 OpenAI 及其領導層忽視安全而偏愛光鮮亮麗的產品。這在業界引起了廣泛關注,在一定程度上凸顯了當前 AI 安全問題的嚴峻性。
5 月 21 日,圖靈獎得主 Yoshua Bengio、Geoffrey Hinton 和姚期智聯合國內外數十位業內專家和學者,在權威科學期刊 Science 上刊文,呼籲世界各國領導人針對 AI 風險採取更有力的行動,並警告說,“近六個月所取得的進展還不夠”。

他們認為,AI 的無節制發展很有可能最終導致生命和生物圈的大規模損失,以及人類的邊緣化或滅絕。
在他們看來,AI 模型的安全問題,已經上升到足夠威脅人類未來生存的水平。
同樣,AI 模型的安全問題,也已經是可以影響每一個人、每一個人都有必要關心的話題。
5 月 22 日,註定是人工智能史上的一個重大時刻:OpenAI、谷歌、微軟和智譜AI 等來自不同國家和地區的公司共同簽署了前沿人工智能安全承諾(Frontier AI Safety Commitments);歐盟理事會正式批准了《人工智能法案》(AI Act),全球首部 AI 全面監管法規即將生效。
再一次,AI 的安全問題在政策層面被提及。
人工智能首爾峰會“宣言”
在以“安全、創新、包容”為議題的“人工智能首爾峰會”(AI Seoul Summit)上,來自北美、亞洲、歐洲和中東地區的 16 家公司就 AI 開發的安全承諾達成一致,共同簽署了前沿人工智能安全承諾,包括以下要點:
- 確保前沿 AI 安全的負責任治理結構和透明度;
- 基於人工智能安全框架,負責任地說明將如何衡量前沿 AI 模型的風險;
- 建立前沿 AI 安全模型風險緩解機制的明確流程。
圖靈獎得主 Yoshua Bengio 認為,前沿人工智能安全承諾的簽署“標志著在建立國際治理制度以促進人工智能安全方面邁出了重要一步”。
作為來自中國的大模型公司,智譜 AI 也簽署了這一新的前沿人工智能安全承諾,完整簽署方名單如下:

對此,OpenAI 全球事務副總裁 Anna Makanju 表示,“前沿人工智能安全承諾是促進更廣泛地實施先進 AI 系統安全實踐的重要一步。” Google DeepMind 總法律顧問兼治理主管 Tom Lue 說道,“這些承諾將有助於在領先開發者之間建立重要的前沿 AI 安全最佳實踐。” 智譜AI 首席執行官張鵬表示,“伴隨着先進技術而來的是確保 AI 安全的重要責任。”
日前,智譜AI 也受邀亮相 AI 頂會 ICLR 2024,並在題為“The ChatGLM's Road to AGI”的主旨演講中分享了他們針對 AI 安全的具體做法。
他們認為,超級對齊(Superalignment)技術將協助提升大模型的安全性,並已經啟動了類似 OpenAI 的 Superalignment 計劃,希望讓機器學會自己學習、自己判斷,從而實現學習安全的內容。
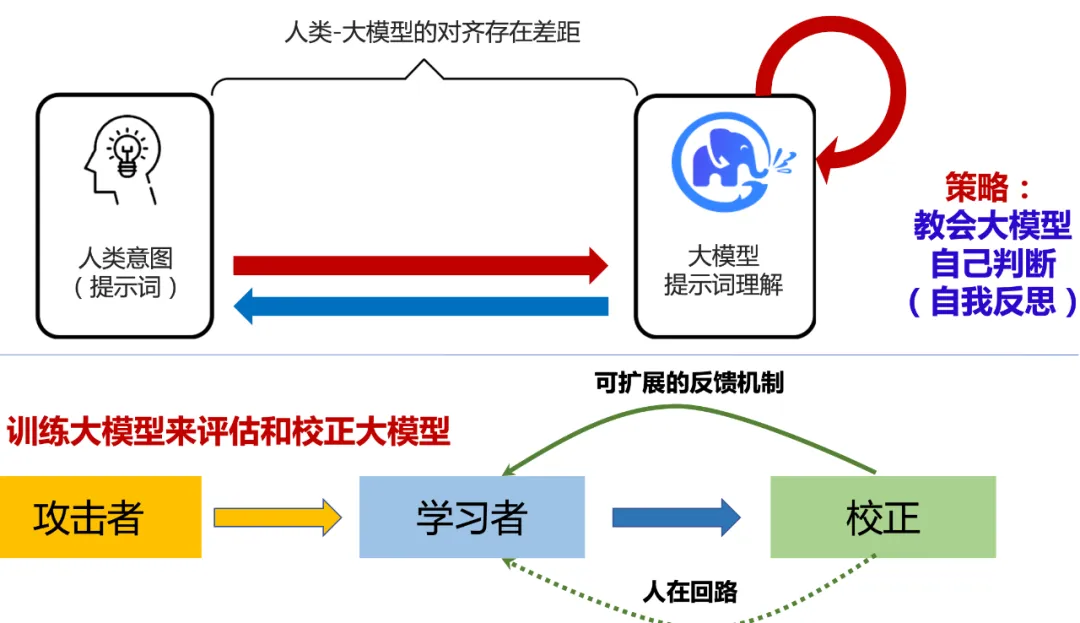
他們透露,GLM-4V 即內置了這些安全措施,以防止產生有害或不道德的行為,同時保護用戶隱私和數據安全;而 GLM-4 的後續升級版本即 GLM-4.5 及其升級模型,也應當基於超級智能(Superintelligence)和超級對齊技術。
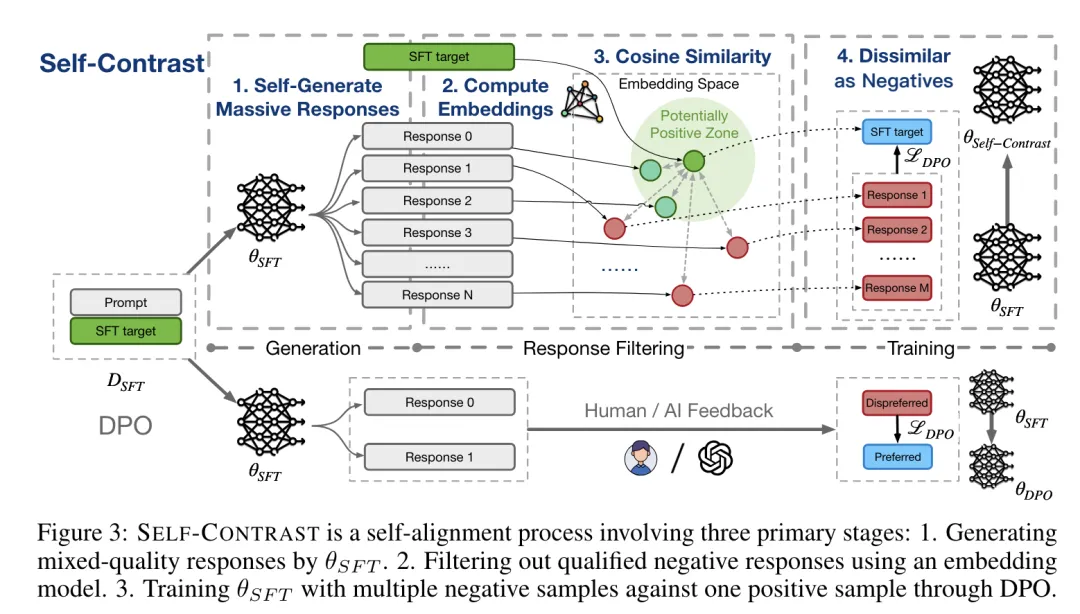
我們也發現,在一篇近期發表的論文中,智譜AI、清華團隊介紹了一種通過利用大量自生成的否定詞而實現的無反饋(feedback-free)大型語言模型對齊方法——Self-Contrast。
據論文描述,在只有監督微調(SFT)目標的情況下,Self-Contrast 就可以利用 LLM 本身生成大量不同的候選詞,並利用預先訓練的嵌入模型根據文本相似性過濾多個否定詞。
論文鏈接:https://arxiv.org/abs/2404.00604
在三個數據集上進行的直接偏好優化(DPO)實驗表明,Self-Contrast 可以持續大幅超越 SFT 和標準 DPO 訓練。而且,隨着自生成的負樣本數量增加,Self-Contrast 的表現也在不斷提高。
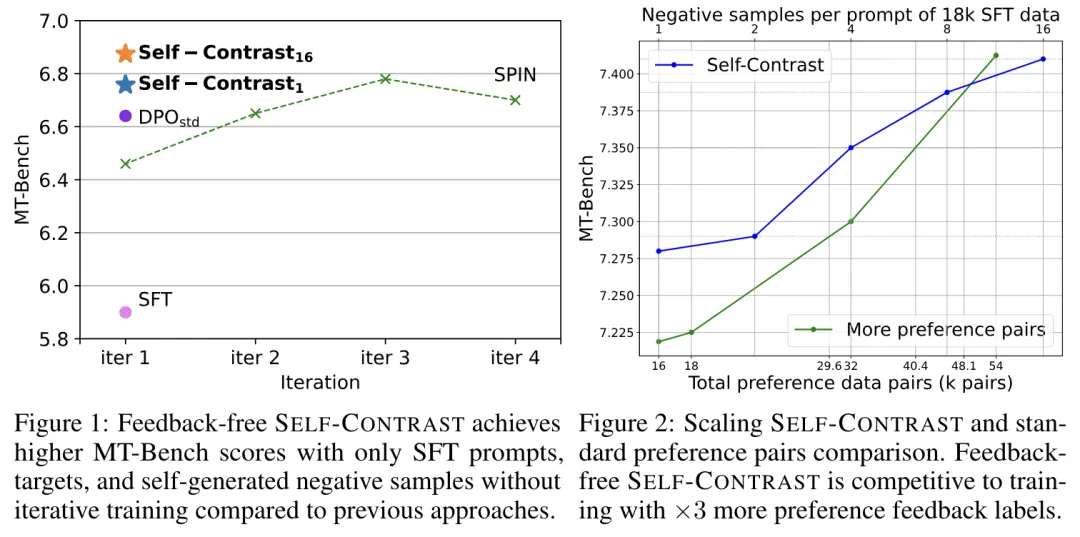
總的來說,這一研究為偏好數據缺失情況下的對齊(如 RLHF 方法)提供了一種新的方法。在偏好數據標註代價昂貴且難以獲得的情況下,可以利用未標註的 SFT 數據構建語法偏好數據,通過增加負樣本的數量來彌補因正樣本不足造成的性能損失。
歐盟理事會正式批准《人工智能法案》
同日,歐盟理事會也於同日正式批准了《人工智能法案》(AI Act),這是全球首部 AI 全面監管法規,這一具有里程碑意義的人工智能法規將於下月生效,目前僅適用於歐盟法律範圍內的領域,或將為商業和日常生活中使用的技術設定一個潛在的全球基準。
“這部具有里程碑意義的法規是世界上第一部此類法規,它解決了一個全球性的技術挑戰,同時也為我們的社會和經濟創造了機遇,” 比利時数字化大臣 Mathieu Michel 在一份聲明中說。
這一綜合性的 AI 立法採用“基於風險”的方法,意味着對社會造成傷害的風險越高,規則就越嚴格。例如,不構成系統性風險的通用目的 AI 模型將承擔一些有限的要求,但那些具有系統性風險的則需要遵守更嚴格的規定。
對違反《人工智能法案》中行為的罰款,該法案設定為違規公司前一個財年全球年營業額的百分比或預定的金額,以較高者為準。
如今,無論是小到科技公司,還是大到政府機構,都已經將預防、解決 AI 安全問題提上日程。正如牛津大學工程科學系教授 Philip Torr 所言:
“在上一次人工智能峰會上,全世界一致認為我們需要採取行動,但現在是時候從模糊的建議轉變為具體的承諾了。”