全部语种











分享
AI视频何时才能跑出一个“Midjourney ”?
巴比特_光锥智能335天前
原文来源:光锥智能
文|郝 鑫
编|刘雨琦

图片来源:由无界 AI生成
AI视频一跃成为“明日之星”,大厂和创业公司们打得热火朝天。
去年12月,Pika的出现仿佛点燃了AI视频赛道的引线,一个月之内冒出了近十家公司,谷歌、阿里、字节、腾讯竞相下场,不断将战事推向了高潮。
“AI视频的Midjourney V5时刻就要到了”,即将迎来成为生产力的关键时刻。
2022年~2023年,文生图的技术以肉眼可见的速度迭代进化。Midjourney平均3个月一个版本,一路从V1狂奔到了V6,实现了从“面目全非”到“细腻逼真”的里程碑式的巨变。文生图技术以月为单位的进化速度,像一把节奏紧凑的小锤,不停提醒所有AI视频的公司们,留给他们成长的时间,不多了。

(图:网友制作的V1-V6的生成效果对比图,来源X)
如今AI视频的发展轨迹也正在慢慢向文生图靠拢,“Midjourney V5”成为了一个关键性的临界点:一旦突破,用户将大规模涌入,数据飞轮开始转动,效果日新月异,一步步推动着文生视频从“玩具”蜕变为“生产力”。
从文字到图片、视频的发展一脉相承,从文生图的进化历程中,也可以找寻到AI视频的影子。
当AI视频成为生产力后,才是产业链齿轮开始转动的开端。只有能用起来,才能诞生目标用户群体;只有能留存住用户,产生持续性的付费,才能构建起清晰的商业模式;也只有跑通了商业模式,池子里的企业才能存活下来,用消费端推动供给端,才能盘活整个AI视频产业。
“AI视频行业的生产力”——这恰恰才是现在各路玩家争夺的价值所在。
梦工厂创始人Jeffrey Katzenberg在近期预测,“生成式AI将使动画电影的成本,在未来3年内降低90%,该技术将给媒体和娱乐行业带来彻底的颠覆”。
“未来可能实现以每秒30帧的高分辨率实时生成内容,并且到2030年,可能会实现整个视频游戏的生成 ”,Midjourney首席执行官DaVid Holz判断道。
V5赛点已至,新一轮的排位赛正式打响,何时才能诞生下一个Midjourney?
AI视频迎来“生产力”时刻
实际上,AI视频几乎与文生图同一时期进入到人们视野中。
2023年初,Midjourney带火了文生图,Runway则激起了“人人制作电影大片”的无限遐想。
彼时,看到文生图领域在效果上大放异彩的Runway创始人曾表示:“希望 Gen-1 能像 Stable Diffusion 在图像上所做的那样为视频服务。我们已经看到了图像生成模型的爆发,我相信2023年将会是视频之年。”
但显然这个论断下得有点过早。2月,RunwayAI视频编辑Gen-1发布,功能类似于AI版的PS,可通过文字输入进行视频的风格转化和修改;3月,发布文生视频模型Gen-2,支持文生视频、文本+图像生成视频。
宣传视频很酷炫,但具体使用效果却差强人意,出现了时长短、生成画面不稳定、指令理解出错、没有音频、动作不连贯和不合理等等种种问题。
Runway打响AI视频第一枪后,虽未停下脚步,但却在视频编辑工具的道路越走越远,运动笔刷、文字转语音、视频合成等功能,只能算“锦上添花”。Gen-2迟迟没有根本性的突破,也让AI视频沉寂了一段时间。
就在大家快要失去对AI视频耐心的时候,去年12月,Pika、Genmo、Moonvalley、NeverEnds、谷歌VideoPoet、阿里Animate Anyone、字节Magic Animate,踏着希望之光来了。
在Pika的官方宣传片中,仅需一句话,就生成了动画版的马斯克,不但神形兼备,而且背景和动作都非常合理连贯,面部一致性也惊人得完美。

(图:Pika 1.0宣传视频动图,源自X)
在其官方展示的第一个视频中,生成效果几乎可以达到迪士尼等动画电影公司的质感。

(图:Pika 1.0宣传视频动图,源自X)
据使用过Pika 1.0产品的用户反映,Pika 1.0 支持3种方式生成视频:文生视频、图生视频、视频转视频。3D和2D效果确实上了一个全新的台阶,逼真度、稳定性、光影效果都可以吊打Gen-2。
“Pika 1.0和Gen-2仿佛不是一个时代的产品”,不少网友都在使用后给出了这样的评价。
Pika们的爆火,要归根于背后基建技术的成熟。其中最重要的就是AnimateDiff。这是一种基于Stable Diffusion文生图模型所搭建起来的动画框架,可让生成的图片直接动起来,字节、腾讯、阿里便是在这个框架的基础上推出了自己的AI视频模型。
当然,除了AnimateDiff的广泛应用,也与大模型多模态的发展,息息相关。
Pika们的出现开启了AI视频的新篇章,AI视频即将迎来“Midjourney V5”时刻。
这里面有两层重要的变化,首先体现在生成层面。
V5阶段,可达到更好的生成效果,在几秒的生成时间内能够达到动作、表情、叙事逻辑的连贯性;更有效的控制方式,对输入指令的理解、遵从,镜头、转场 、风格转化的控制都有了新的提升;更低的资源消耗,能够以更短的时间、更少的算力调用,生成更高分辨率和优质的视频,几秒的视频也可以达到几十秒的效果。
更重要的体现在生产力的突破上。
以Midjourney为例,在V5阶段,成为了UI设计师的设计工具,游戏原画师的助手,跨境电商的商品展示、广告营销的素材库。同样在这个阶段,AI视频也将有可能生成广告、短视频、电影、游戏,成为可以替代编导、导演、演员、设计师的生产力工具。
大模型、扩散模型
两条技术路径的殊途同归
AI视频就像一部电影大片,卖不卖座、叫不叫好,取决于剧本和特效两个重要元素。其中,剧本对应着AI视频生成过程中的“逻辑”,特效则对应着“效果”。
为了实现“逻辑”和“效果”,在AI视频行业中,分化出了两条技术路径扩散模型和大模型。
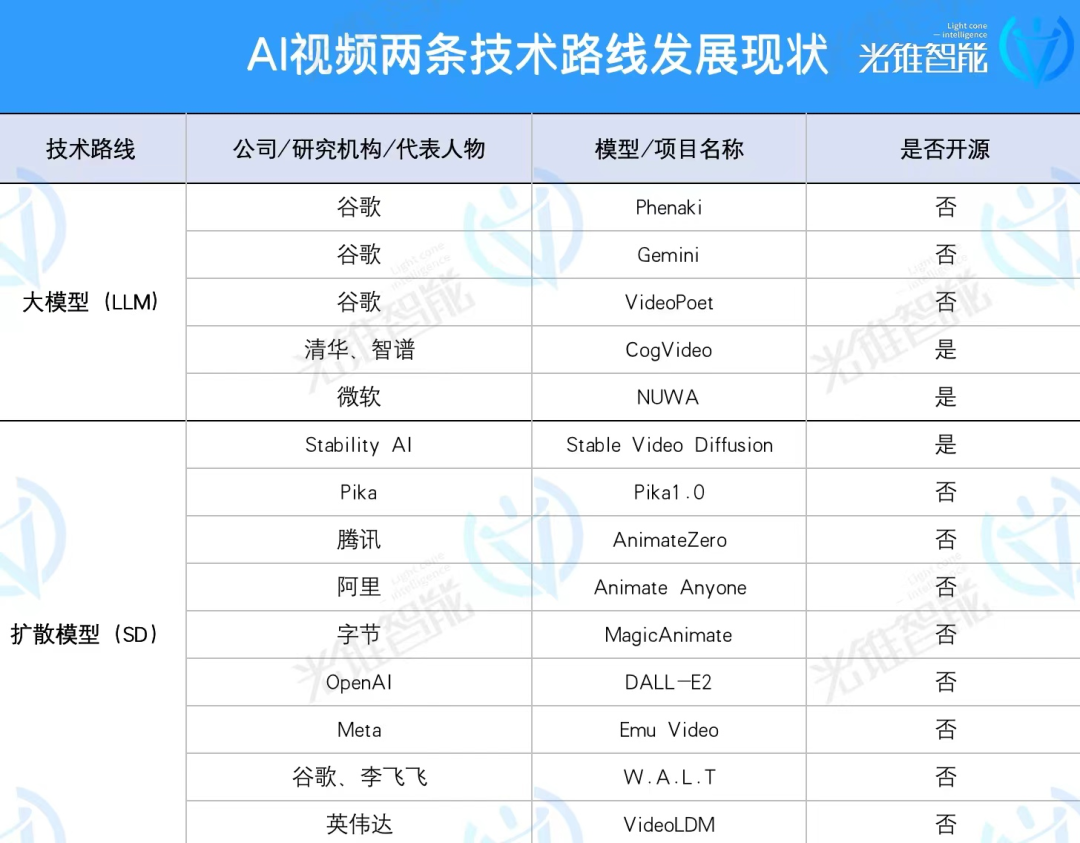
(图:光锥智能自制)
AIGC火了以后,扩散模型长期占据了图像生成领域的主导位置,这背后要归功于Stability AI的不断开源,一方面让更多的开发者加入到了精进模型的队伍中,另一方面也一手将扩散模型捧到了文生图领域的“王位”上。
如今,AI视频自然也被深深地打上了扩散模型的烙印。大厂和初创公司或多或少都在采访和论文中提到过扩散模型的思路,Pika一批新崛起的公司取扩散模型之长,打造自身的新模型;英伟达、阿里、字节、腾讯等公司在其基础之上,进一步提升模型能力。
在大模型技术路线上,经历过一次改变。大模型面世的初期,AI视频的主要思路是用训练大模型的那套方法,靠大参数、大数据来从头构建一个文生视频的模型,比如2022年就问世的CogVideo就是这类代表。
但随着大模型从单一文本迈向多模态,视频就像之前文字、图像生成一样,成为了从大模型根上长出来的一项功能。从很早的时候,谷歌、微软就在尝试用大模型中Transformer的方法训练和增强现有的扩散模型,但直到谷歌发布多模态大模型Gemini和VideoPoet视频大模型后,大模型生视频这条路才终于看到了曙光。

(谷歌VideoPoet视频生成效果演示)
两条技术路径无好坏,但侧重点不同,扩散模型的核心在于“还原呈现”,重效果;而大模型核心在于“接收理解”,重逻辑。
正是基于这样的特性,导致了走扩散模型路线的AI视频公司在细节刻画和生成效果上优势更强,走多模态大模型路线的公司在连贯性和生成合理性上更好。
Pika联合创始人兼CTO Chenlin Meng认为,可以同时发挥两条路径的优势来构建视频模型,比如GPT一类的大模型可以捕捉上下文,视频中也需要上下文控制生成每一帧从而达到系统的一致性;同时每一帧仍然是一张图片,可以用扩散模型来提高生成效果。
Pika的观点不是个例,行业中越来越呈现出这样的趋势。原因在于,虽然现阶段,Pika、Runway每一次升级都在效果宣传上搏足了眼球,但要落地到广告、电影、营销等实际场景中,还有很大的距离。
英伟达高级研究科学家兼人工智能代理负责人,Jim Fan认为,目前所生成的视频只能被称作“无意识的、局部的像素移动”,缺乏可以一以贯之的时间、空间、行为逻辑来控制生成过程。
有一个例子可以很好地理解当前AI视频发展现状。在X上,一个名叫Ben Nash的网友,做了一个测试,用同样的英文提示词“威尔·史密斯吃意大利面”来测试Runway、Pika的视频生成效果。结果发现,在两个视频中,虽然大致可以呈现出想要呈现的效果,但却出现了“意大利面倒流”、“面被直接吸入嘴里”的滑稽场面。

Runway生成效果

Pika生成效果
Jim Fan表示:“到2024年我们将看到具有高分辨率和长时间连贯性的视频生成。但这将需要更多的‘思考’,即系统2的推理和长期规划(对应System 1负责无意识的感觉运动控制)”。
近期Runway也在官网宣布了一项新的长期研究项目“通用世界模型”(General Wold Models),其解释原因称:“我们相信人工智能的下一个重大进步将来自于理解视觉世界及其动态的系统。”
逻辑、思考、推理,或许将成为,2024年AI视频的关键词,两条技术路线的融合也将成为常态。
生产力“解救”商业化
而一旦成为生产力,眼前AI视频面临的商业化困境,便迎刃而解。
生产力工具有两个方向,向上走的专业化路线,和向下包容的大众路线。但现阶段,AI视频行业多数还是以视频剪辑工具的形态向用户开放使用。
“工具即产品”在文生图和AI视频赛道十分普遍,大部分公司选择方法就是,最开始先在Discord上小范围开放测试,到正式开放使用,再到上线网站。
“工具”意味着专业性高、门槛高、操作复杂、上手困难,这就与易上手、操作便捷、体验性高的“产品”拉开了差距。
举一个很典型的例子,你需要花费时间、金钱成本在PR软件上了解每个工具的功能是什么以及怎么使用这些工具,以达到比较好的视频制作效果;但你打开抖音发布视频只需三步,点击加号-拍摄视频-发布,下至幼儿园的孩子,上至60多岁的中老年人,都能覆盖,这就是工具与产品最明显的差异。
生产力未突破的前夜,工具即产品或许还将存在一段时间,但下一步摆在AI视频公司面前的问题很明确:是要坚持走专业工具路线,还是要把门槛打下来,做下一个AI视频版的“抖音”?
在这个问题上,Pika已经率先做出了选择,其创始人郭文景在采访时表示:“我们开发的并不是电影制作工具,而是为日常消费者打造的产品——我们虽然有创造力,但并不是专业人士。”
落实到商业化上,郭文景称Pika最终可能会推出分层订阅模式,让普通的付费用户也能享用更多的功能,计划通过这种方式,让Pika与其他竞品分出区别。
生产力能力欠缺的AI视频工具也无法长期留住用户,不断地产生付费,从而形成健康的商业模式。现在的现状是,用户出于猎奇,或免费尝鲜,或抱着试一试的心态订阅一个月,到期过后,该视频工具就被抛之脑后。
这对创业公司的打击是巨大的,没有持续性的收入,不能自造血,就得依赖融资,哪天融资断了,公司也就维持不下去了。放眼到整个AI视频行业来看,如果作为身在其中的个体都生存不下去,又谈何行业未来前景。
如果一个行业只有单一的工具,没有更多的落地场景,也无法形成完整的生态闭环。就像现在,用户在AI视频工具上浅浅地停留一下,然后把大把的流量引向了社交平台。

(图:源自X)
比如,马斯克跳舞、蒙娜丽莎跑步等大量搞怪视频,一度席卷了TikTok;使用Runway、Pika等视频工具生成的视频,通过用户在X、TikTok、油管的分享一炮走红,获得了巨大的流量,有人甚至已经靠这种方式完成了流量变现,而作为工具的提供方,却只能沦为社交平台的“嫁衣”。
打通工具和场景的壁垒,作为参考案例,国内抖音已经开始在尝试。
剪映的相关AI功能一上线就和抖音实现了联动,并引发了一波抖音扩图大赏,“让你意想不到的AI扩图”一话题挑战,达到了2亿多的播放量,甄嬛打篮球、星黛露秒变星黛驴、皮草美女化身狼人,AI是惊喜还是惊吓,引发了大量的讨论。
一旦成为了生产力,整个产业链条的消费端将开始出现购买力,消费端的需求推着供给端进化,至此,AI视频才算彻底“活了”。