全部语种











分享
回顾苹果 AI 布局:迟到的王,迎接关键一战
巴比特_无限智能215天前
文章来源:AI 科技大本营

图片来源:由无界AI生成
随着诸如 ChatGPT 之类的生成式 AI 工具的迅速普及,越来越多人开始猜测苹果公司在 AI 时代的未来动向:是端出 iOS 版的对话式人工智能?还是革新智能语音助手 Siri?
昨晚,苹果以一场仅 38 分钟的发布会为六月份 WWDC 2024 预热,CEO 蒂姆·库克宣布,此次发布将是 iPad 历史上的重要里程碑。在苹果的一系列宣传中,除了“最薄 iPad”,最引人瞩目的便是苹果推出的最新 M4 芯片:它搭载苹果最强大的神经引擎,每秒执行 38 万亿次操作,比 A11 Bionic 的首代神经引擎快 60 倍,被誉为“极端强大的 AI 芯片”,只需 M2 一半的功耗即可提供相同性能,且在 AI 处理能力上超越当前任何 PC 神经处理单元。

库克曾经如此评价过 AI:它们会嵌入到我们制造的每一个产品中。现在看看苹果在 AI 领域的一系列动作,特别是 Ferret、HUGS、MM1、ReALM 等论文的发布,我们会发现苹果的战略方向仍是“软硬件的结合”,在资源有限的移动设备上高效部署大型语言模型,是实现 AI 技术大众化应用的关键。
WWDC 还有一整月才会亮相,本文将简单回顾苹果这半年的各种动向作为前瞻,让我们一起看看苹果将怎么逐步构建一个以 AI 为驱动的全新生态系统。

Siri——改造它还是“生二胎”?
2023 年 5 月,蒂姆·库克(Tim Cook)在苹果的财报电话会议上表示,人工智能有“许多问题需要解决”,重要的是“在开发方法上要深思熟虑”,并计划继续在深思熟虑的基础上将 AI 融入到产品中。
实际上早在 2019 年,苹果就组建了专注于对话式 AI 的团队,AI 部门主管约翰·詹南德里亚(John Giannandrea)在公司内部领导着大语言模型的研发,他的工作直接向苹果 CEO 蒂姆·库克汇报。但直到 OpenAI 发布 ChatGPT 之前,这个团队一直没传出过什么消息,可谓是起了个大早、赶了个晚集。
时间回到 2023 年,彭博社专职报道苹果科技新闻的记者马克·古尔曼(Mark Gurman)透露,AI 研发在苹果内部被赋予高度优先级,公司设计了一套名为“Ajax”的大型语言模型框架。当时的新闻表示 Ajax 相较于 ChatGPT 3.5 在能力上有所超越,且已基于超过 2000 亿参数进行训练(虽然从今天的角度来看已经不怎么样了)。事实是,OpenAI 随后发布的 GPT-4 模型就已超越 Ajax 泄露出的纸面数据。
这段时期的苹果对于如何面向消费者推出生成式 AI 产品尚无清晰策略。
2023 年 9 月,外媒 The Information 首次曝光了苹果 AI 研发的种种细节:
- 苹果在对话式人工智能的研究上每日投入数百万美元,因为训练语言模型需庞大硬件支持。
- 核心团队只有 16 人。
- 核心目标之一是让 Siri 能够执行多步骤任务。

团队核心成员也相继曝光:
- John Giannandre,前文提及的这位领导者其实是苹果公司的机器学习和 AI 战略高级副总裁。
- Daphne Luong,苹果特意从谷歌挖来的 AI 高管。
- Arthur Van Hoff,他曾从事 Java 程序语言的早期开发工作,传闻中 Java 名字中的那个“v”就来自于他。
- Ruoming Pang,2021 年加入苹果,擅长神经网络研究。
苹果在生成式 AI 领域的探索,有望最终融入 Siri 语音助手。
负责 2014 年改进 Siri 的前苹果工程师 John Burkey 曾如此批评这款语音助手:Siri “基于笨拙的代码构建”,其“累赘的设计”使得工程师很难添加新功能,即使是最基本的功能更新也需要数周时间。比如,Siri 的数据库包含接近二十多种语言的大量短语列表,形成一个“大雪球”。因此,Burkey 认为,Siri 最终无法成为像 ChatGPT 那样的人工智能助手。

John Burkey
苹果公司的研究人员一直在研究「无需使用唤醒词即可使用 Siri」的方法,也就是让语音助手“凭直觉”判断机主是否正在与其交谈,而不是聆听“嘿 Siri”或“Siri”。2023 年 10 月份,苹果的研究人员发表了一篇论文研究唤醒词的这个问题:

论文地址:https://arxiv.org/pdf/2310.16990
这篇论文旨在让 Siri 设法弄清你什么时候在问一个后续问题,什么时候在问一个新问题。它利用 LLM 来更好地理解所谓“模棱两可的询问”,无论你怎么说,它都能猜出你的意思。
文中写道:“在不清楚对话者的意图时,智能对话代理可能需要「主动出击」,通过主动提出好问题来减少不确定性,从而更有效地解决问题。”
除了 Siri 的问题,苹果本身还需要解决另一项大麻烦。2023 年年底,Keivan Alizadeh 等人发布了一篇论文,针对现代自然语言处理领域核心的大型语言模型(LLMs)进行了研究。他们要解决的问题是当今的一大挑战:怎么把动辄千亿参数的这些 AI 大模型塞到小小的 iPhone 里面?

论文地址:https://arxiv.org/pdf/2312.11514
他们的研究通过细致设计的系统策略,着力于最小化在模型推断阶段从闪存到设备有限 DRAM 资源的数据迁移负担。核心在于构建一个与闪存特性和操作机制紧密配合的推理成本模型,籍此双管齐下优化数据处理流程:一方面,减少数据在闪存与 DRAM 间往返的总量;另一方面,优化数据读取模式,倾向于更大规模和更高连贯性的数据块读取操作。
研究团队创新性地推出了两项关键技术:“窗口化”策略,这种方法聪明地复用近期推理中已激活的数据,减少不必要的重复加载;以及“行列捆绑”技术,通过智能组织数据的存储布局,使得每次从闪存提取的数据块更为庞大且读取连续,尤其适合闪存介质的读取特性。在苹果自家 M1 Max CPU 平台上实施这些技术,与常规的数据加载方案对比,推理效率实现了显著的 4 至 5 倍跃升;而转移到 GPU 环境,这一效率提升更是激增到 20 至 25 倍,成效斐然。
未来展望中,这些优化技术的实装,或将很快赋能诸如 iPhone、iPad 以及其他移动设备,使复杂的 AI 助手和聊天机器人在这些平台上的运行变得丝滑无阻。如今看来,M4 芯片的发布或许就是苹果端侧 AI 的最后一块垫脚石。
除此之外,苹果欲将生成式 AI 引入移动设备,可能还需要解决隐私问题。从 Siri 的历史可以看出,苹果素来对隐私保护持审慎态度,这种决策虽使 Siri 在功能性上略逊于 Alexa、Google 助手等竞品,却彰显了其对用户隐私的重视。

“百模大战”时期的苹果:封闭,还是开源?
2023 年 10 月份,苹果悄然发布了 Ferret 开源多模态大型语言模型。这篇论文相当不得了,同时包含了“苹果”“开源”以及“全华班”几大元素——没错,论文的作者全是华人。

论文地址:https://arxiv.org/pdf/2310.07704
开源地址:https://github.com/apple/ml-ferret
这篇论文介绍的多模态模型 Ferret 能够理解和处理图像中任意形状或粒度级别的空间参照,并准确地对开放词汇描述进行定位。其核心创新在于它采用了一种新颖且强大的混合区域表示方法,这种方法将离散坐标与连续特征结合起来,共同表征图像中的某个区域。这不仅融合了传统上分开处理的参照(referring)和定位(grounding)任务,还在 LLM 的框架内实现了两者的统一。
为了提取不同区域的连续特征,苹果提出了一种空间感知的视觉采样器。这种采样器擅长处理不同形状间变化的稀疏性,使得 Ferret 能够接受多样化的区域输入形式,包括点、边界框以及自由形态的形状。这一设计显著增强了模型处理复杂视觉信息的能力。
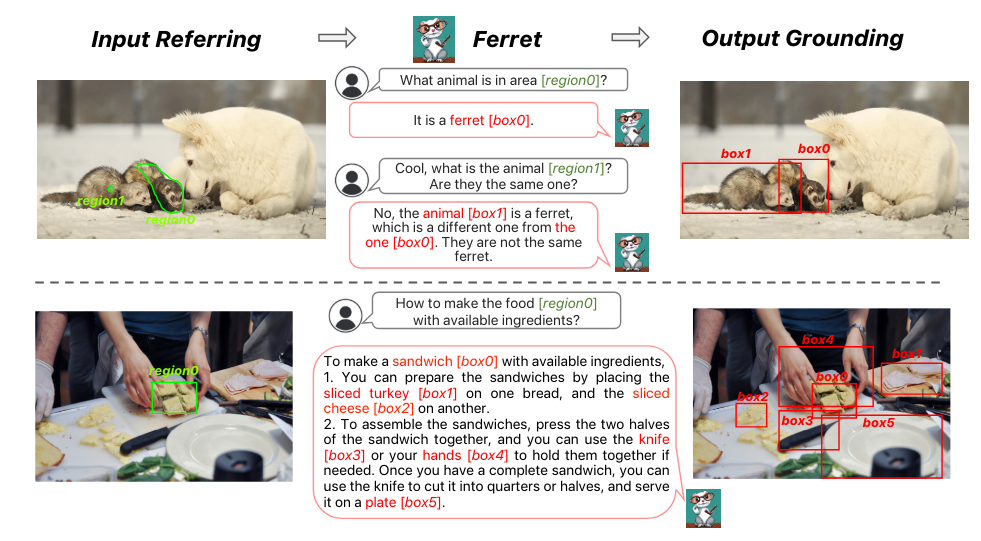
为了强化 Ferret 的这些特有能力,研究团队还精心构建了 GRIT 数据集,这是一个全面的参照与定位指令微调数据集,包含 110 万个样本,这些样本富含层次化的空间知识,并特别加入了 9.5 万个困难负例数据来增强模型的稳健性。GRIT 数据集的设计旨在通过丰富的训练实例,促进模型在理解和生成基于空间关系的多模态指令方面的表现。
实验结果显示,Ferret 不仅在经典的参照和定位任务上取得了卓越的性能,在基于区域的以及需要精确定位的多模态对话任务上,其表现更是远超当时的其他多模态大语言模型。

评估还揭示了 Ferret 在描述图像细节方面的显著提升,以及在减少臭名昭著的“幻觉”(hallucination)现象上的明显改善。这意味着 Ferret 不仅能更准确地理解和生成与图像内容相关的语言描述,还能在描述过程中减少不准确或不存在信息的引入,从而提高了生成内容的真实性和可靠性。
尽管 Ferret 公布材料含代码与权重(仅供科研,无商用授权),导致初时并未引发广泛关注,但随着开源 Mistral 模型近期炙手可热,小型设备上本地 LLMs 的应用潜能日益受到瞩目。苹果宣布在 iPhone 上实现 LLM 部署的重大突破后,讨论热度也是随之骤增。

当时引起了 Hacker News 三百多条的评论
2023 年底伴随而来的一项研究报告还揭示了苹果最新的 HUGS(Human Gaussian Splats)技术,旨在从单镜头短视频中创制动态 3D 虚拟形象,提供更为沉浸的视觉体验。论文一作 Muhammed Kocabas 还曾放言:“我们的方法可以从一段单镜头短视频(50 - 100 帧)中自动区分静态场景与全动画虚拟形象,整个过程仅需 30 分钟。”


论文地址:https://arxiv.org/pdf/2311.17910
HUGS 借助高效的 3D 高斯斑点渲染技术,同步展现主体与背景。人体模型依托 SMPL(统计形体模型),HUGS 凭借高斯形变捕获衣物、发型等细微之处。一新型神经变形模块借力线性混合蒙皮技术,使高斯动态表现更为真实,避免了摆姿调整中的视觉扭曲。
相比早期虚拟形象生成手段,HUGS 在训练和渲染速度上快至 100 倍,仅需 30 分钟即可在标准游戏 GPU 上优化出逼真的效果。在 3D 重建质量方面,HUGS 也超越了诸如 Vid2Avatar 和 NeuMan 等最先进技术。
此项创新让用户仅凭一段含人物与场景的视频,即可将各式数字角色或“虚拟形象”置入新情境,以每秒 60 帧的速率刷新,呈现流畅逼真的效果。
苹果的一系列 AI 技术发布——尤其是开源多模态模型的举动,直接给许多业内人士送上了一份惊喜。专注于医疗领域开源 AI 的欧洲非营利组织负责人 Bart de Witte 当时在 X 平台上赞扬苹果:“不知怎的,我错过了这个消息。苹果在 10 月份加入了开源 AI 行列。Ferret 的问世,彰显了苹果致力于有影响力的 AI 研究的决心,并巩固了其在多模态 AI 领域的领头羊地位……我对将来本地大型语言模型(LLLMs)作为 iOS 新设计一部分运行于 iPhone 上充满期待。”
德国 AI 音乐艺术家及顾问 Tristan Behrens 在 Linkedin 上写道:“圣诞节提前到来,但你知道吗?苹果(没错,就是苹果!)最近发布了一个包含代码和权重的多模态大型语言模型。”
科技博主 Ben Dickson 曾就这一惊喜发表意见:“2023 年最让你惊讶的 AI 发展是什么?对我来说,是苹果发布了开源 LLM(虽然是非商业许可的)。”他指出,苹果历来坚持封闭系统、保密、严格的保密协议,甚至对微小创新也会严格申请专利。
他接着说:“但回过头看,苹果(像 Meta 一样)发布开源 LLM 模型是有道理的。要与像 ChatGPT 这样的模型竞争,要么你得有台超级计算机,要么得有强大的合作伙伴。虽然苹果资源丰富,但其基础设施并不适合支持大规模 LLMs。另一个选择是依赖像微软或谷歌(两大竞争对手)这样的云服务提供商,或者像 Meta 那样开始发布自己的开源模型。”
回顾完 2023 年的“旧闻”,再来看目前苹果对于战略合作的最新动向:2024 年 3 月彭博社曾报道,苹果正与谷歌探讨在 iOS 18 中集成 Gemini AI 引擎的可能性。苹果意在获取谷歌大型语言模型的授权,但具体条款与品牌命名尚未敲定。
此外,苹果还正开发基于设备的 AI 新功能,同时寻求拥有强大硬件基础的合作伙伴以支持云端生成式 AI 应用,如根据提示生成图像和编写文章,但目前并无开发 ChatGPT 风格聊天机器人的计划。
除谷歌外,苹果今年亦与 OpenAI 接洽,探讨如何在 iOS 18 中运用 OpenAI 技术。在中国市场,苹果同样于三月份引起过一波热议,也就是先前传闻的和百度的合作:

到了今年四月份,苹果寻求与照片分享服务网站 Photobucket 达成协议,利用其超过 130 亿份图像和视频资料训练 AI 模型,并已从 Shutterstock 购得数百万张图片授权。
苹果的生成式 AI 蓝图徐徐铺开,一切皆待下个月的 WWDC24 大会正式揭晓。当前,几乎每家大型科技企业均有 AI 产品筹备中。除 OpenAI 的 ChatGPT 以外,国际知名的谷歌、微软、亚马逊等大厂都蓄势待发:
- 谷歌:推出了 Bard 和 Gemini。已将生成式 AI 融入搜索产品与应用,而 Bard 还与 Google Flights、地图、Drive 等服务整合。
- 微软:前脚与 OpenAI 合作,后脚发布 MAI-1 模型进行“背刺”。将 ChatGPT 融入自家 Bing 搜索引擎,并拥有 Copilot AI 应用。
- 亚马逊:努力通过生成式 AI 改进国外火爆的 Alexa 语音助手。
- Meta:发布了开源模型 LLaMA 造福世界,坐拥 AI 教父杨立昆,准备今年下半年再发布 LLaMA-3 的最强版本。此外,还将生成式 AI 融入多款应用,如 WhatsApp 和 Messenger 和 Instagram。

透明到底不妥协
如果说去年的苹果还让人有些难以捉摸,那今年全面专攻 AI 的苹果可谓是大显身手了。2 月份,在「造车」与「AI」两条截然不同的赛道上,苹果毅然决定取消搞了十多年的电动车项目,引得乐视创始人贾跃亭点评:
同一时间段发布的 VisionPro 亦是争议满满,但由于本文主讲 AI,便不再深入,等待六月份苹果的进一步更新。
很快来到 3 月,苹果并没有闲着,而是扎出了一记利枪:300 亿多模态大模型 MM1。30 多位研究员,且和前文提到的 Ferret 大模型一样,华人含量极高。

论文地址:https://arxiv.org/pdf/2311.17910
MM1 继承了 Ferret 的理念,在论文中直接指出当前众多 AI 公司在 AI 模型的学习方法上有着“不透明性”的痛点。大多数的模型对于他们所使用的算法设计选择的过程几乎没怎么进行公开,而今年爆火的多模态预训练更是如此。为了在多模态这条赛道跑下去,苹果发布了这篇论文,完整记载了模型的构建过程。
当时还引起了英伟达研究科学家 Jim Fan 的吐槽:
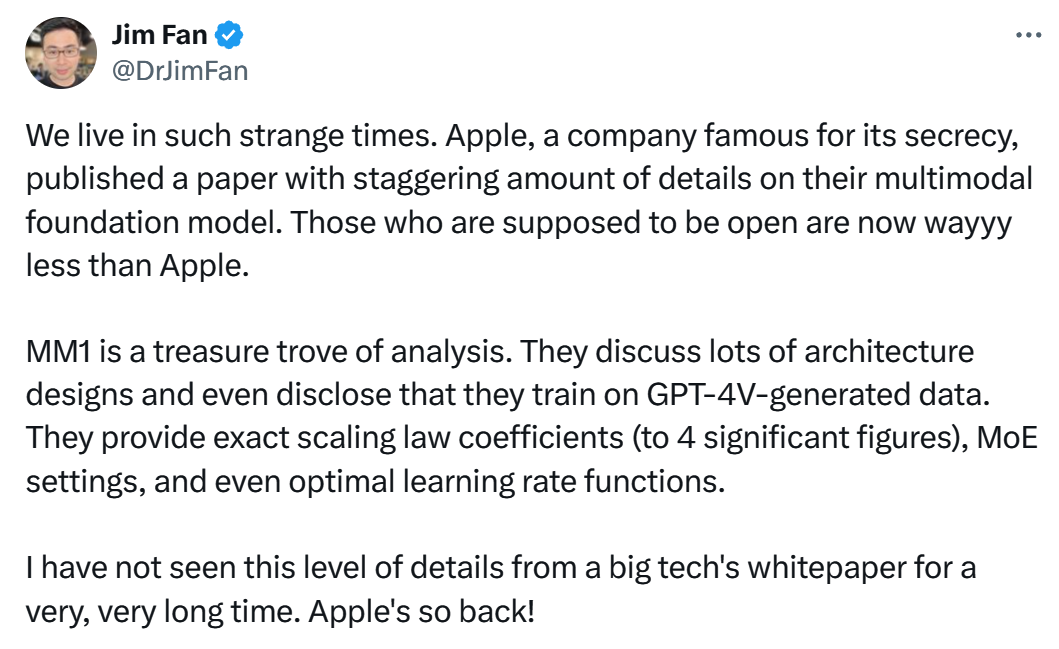
我们正处在一个如此奇特的时代。苹果,一家以保密著称的公司,竟然发表了一篇关于其多模态基础模型的论文,其中包含了令人震惊的详尽细节。那些本应更加开放的公司,如今在这方面反而远不如苹果透明。MM1(假设这是苹果模型的代号)是一座分析的宝库。他们讨论了许多架构设计方面的问题,甚至透露他们使用了 GPT-4V 生成的数据进行训练。他们提供了精确到四位有效数字的缩放定律系数、MoE(专家混合网络)设置,乃至最优学习率函数等信息。我已经很久很久没有在大型科技公司的白皮书中看到过如此详尽的内容了。苹果真的回来了!(Apple's so back!)
三月底,苹果再发力作,推出 ReALM 框架,附带四款神秘的超小参数模型,性能直逼 GPT-4。

论文地址:https://arxiv.org/pdf/2311.17910
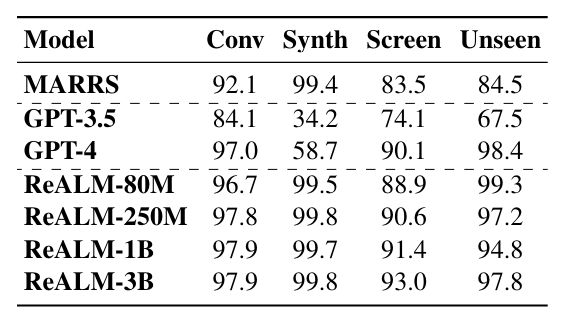
ReALM 对抗了曾经“参数量即王道”的普遍认知,在不依赖于模型规模的持续膨胀下,通过算法和架构创新达到与当前顶尖模型如 GPT-4 相当的性能。其中,参数最“大”的 30 亿参数 LLM 在标准对话数据集中达到了 97.9% 的准确率,在合成数据集上则达到了 99.8% 的准确率;在涉及屏幕上的实体引用解析任务上,3B LLM 达到了 93.0% 的准确率;在未知领域,如警报系统的测试中,该模型依然保持了 97.8% 的准确率,与 GPT-4 的表现相近。
ReALM 对 Siri 最显著的强化在于上下文理解的升级,它可以掌握诸如“再次播放那首歌”或“给她打电话”等参考信息,甚至预测用户的需求和偏好,根据过去的行为和上下文理解建议或启动操作。
2011 年推出 Siri 时,苹果曾一度走在语音助手创新的前沿,适应着全球用户的需求。时间一点点推进,Siri 逐渐变成大家所调侃的“人工智障”,其未来形态也成为了本次 WWDC 2024 被关注的焦点。
库克曾在今年二月的股东大会上曾用一个词形容苹果的 AI 计划:“break new ground”——开辟新天地。最晚进场的苹果,这次是姗姗来迟还是伺机待发?此刻,你心中或许已经有了答案。