全部语种











分享
又是疯狂的一周,全世界都「AI 麻了」!
巴比特_AI之势206天前
文章来源:极客公园
作者 | 宛辰
编辑 | 靖宇

图片来源:由无界AI生成
是因为「劳动节」吗?全世界所有的公司,都选择在 5 月第三周,将最新的 AI 产品和技术,集中释放。
丧心病狂的一周!
铺垫了许久的「周一见」,OpenAI 用 GPT-4o 夺走了注意力。24 小时后的发布会上,谷歌也没有「掉链子」,Veo 视频模型、Project Astra、新版 AI 搜索都留下了惊艳的记忆点。
地表最强但风格迥异的两场发布会,只在一点上达成共识——电影《Her》一般的超强语音助手(GPT-4o 和 Project Astra),这也变相公布了 2024 年大模型赛道的竞赛点——GPT-4o 和 Astra 背后的多模态融合技术。
大洋彼岸的另一端,姗姗来迟的字节跳动发布了豆包大模型家族,腾讯终于交出了「GPTs」和大模型助手 App 的答卷。
今天看来,无论是「拖家带口」的大厂,还是「没有包袱」的创业公司,产品形态都一再扩展:从聊天机器人,到 AI 搜索、「GPTs」、多模态语音助手.... 玩得越来越花。
不知道你麻没麻,反正我们是幸福地麻了。
5 月 13 日(周一)
AI 化身/人形智能体正在快速演进:宇树发布 Unitree G1 人形机器人
¥9.9 万元起,远低于行业售价
大语言模型出圈,让可以实现具身智能的人形机器人火了。
2023 年 8 月,宇树科技发布了人形机器人 H1,预售价为 9 万美元(约合 65 万元人民币)。本周,宇树推出的新版人形机器人 Unitree G1 将价格降到 9.9 万元人民币起,便宜了超 80%。
与第一代产品相比,Unitree G1 能力显著提升:开瓶盖、砸核桃、颠锅、跑步、舞棍、自我蜷缩……在宇树科技发布的产品演示视频里,身体和双腿能旋转近 360°,Unitree G1 像人类一样用机械双臂灵活地完成一系列工作。

图片来源:宇树科技
开源闭源并进:零一万物发布千亿参数 Yi-Large 模型
开源构建生态,闭源探索AI上限
零一万物成立一周年之际,其千亿参数 Yi-Large 闭源模型正式亮相,在斯坦福最新的 AlpacaEval 2.0 达到全球大模型 Win Rate 第一。
同时,零一万物将早先发布的 Yi-34B、Yi-9B/6B 中小尺寸开源模型版本升级为 Yi-1.5 系列,每个版本达到同尺寸中 SOTA 性能最佳。

Yi 大模型 API 开放平台 | 图片来源:零一万物
5 月 14 日(周二)
「Her」真的来了:「GPT-4o」将语音助手带到了新高度
多模态融合模型,只是工程的进步吗?
OpenAI 发布了新一代旗舰模型 GPT-4o,它可以让人们在手机上与 ChatGPT 对话,就像他们与 Siri 和其他语音助手对话一样。不同的是,ChatGPT 语音助手的理解能力有了质的飞跃,还可以分析和讨论它所看到的图像或视频,并能识别用户说话时的不同情绪。
有了 GPT-4o 的加持,ChatGPT 可以根据你的想法引导你做数学题目、按照你的实时要求讲一个睡前故事。OpenAI 称 GPT-4o 是为了创建一个对音频、图像和文本有更深入、更自然理解的模型,这依旧是为了向 AGI 目标行进。
OpenAI 的发布,也在 AI 圈引起了广泛讨论。业界普遍认为,GPT-4o 的惊艳之处在于两点:1)将语音交互延迟缩短到 300ms;2)端到端多模态原生大模型
P.S.: 留一个观察作业:GPT-4o 会显著提升 ChatGPT 的日活和用户粘性吗?有了更高 AI 能力的智能助手,2016 年的百箱大战会席卷重来?Siri 一样的语音助手会成为入口级的必争之地?

图片来源:OpenAI
5 月 15 日(周三)
没有一款产品没有被 AI 改造:谷歌全面进入 Gemini 时代
Sora 尚且是科技巨头的选做题,但多模态融合就是大模型公司的必做题。
提了 121 次 AI,谷歌 I/O 2024 开发者大会发布了一箩筐,从搜索到 Gmail、TPU,再到语音助手 Astra 和多模态视频模型 Veo 等。
三个产品值得关注:
- Project Astra 的多模态 AI 助手。如果说 2023 年的竞赛点是 Copilot,2024 年,赛点则进化为多模态融合的 Agent,背后是从 LLM(大语言模型)到 One-network-multimodality(一个框架下的多模态大模型)的技术路径迁移,最终迈向跟通用的人工智能。

多模态语音助手正在与用户实时对话|图片来源:Google
- Veo:Veo 可以根据文本、图像和视频提示创建 AI 生成的视频,并且即将登陆 YouTube,帮助创作者快速制作更专业品质的视频。
- AI 搜索:谷歌展示了如何进一步将人工智能集成到搜索中,从而实现更复杂形式的研究和规划(例如,根据查询生成三天的素食计划)。

图片来源:谷歌黑板报
大模型之字节打法:没准备好就不发,否则一次发布 9 个模型
模型发得晚,应用没少做,怎么想的?
字节跳动自研大模型豆包大模型(原云雀大模型)家族带着 9 个模型,首次对外亮相。字节跳动方面称,之所以是这 9 个模型,是根据后台模型调用量和需求而来,做了最强通用模型、性价比之选、和场景优化模型。
豆包大模型的推理价格成为一大亮点,其主力模型在企业市场的定价只有 0.0008 元/千 Tokens,0.8 厘就能处理 1500 多个汉字。
值得注意的是,字节发布会没有介绍模型参数、数据和语料,甚至没有给出豆包模型的评测数据,而是直接把模型能力在场景里做了垂直细分。字节可能是在建立用户反馈、数据反馈,从而做更精准地场景和服务。根据不同的数据链反馈,决定产品或者模型的下一步动作。
过去大半年,字节跳动推出的 AI 应用几乎涵盖了所有热门赛道,「豆包」、AI 应用开发平台「扣子」、互动娱乐应用「猫箱」,以及星绘、即梦等。

图片来源:字节跳动
大模型队伍的隐秘玩家:DeepSeek Chat 通过大模型备案
降成本!我带头!
国内拥有超过 1 万枚 GPU 的企业不超过 5 家,幻方这家千亿规模的量化基金就是其中之一。意外地提前压中大模型的入场券——囤卡,但幻方做大模型是认真的。
今年 1 月以来,幻方旗下公司的 DeepSeek 模型被频繁作为开源社区里讨论的对标对象。本月,幻方开源了第二代 MoE 模型:DeepSeek-V2,主打参数更多、能力更强、成本更低。其在能力逼近第一梯队闭源模型的前提下,推理成本降到了 1 块钱 per million token,也就是说,成本是 Llama3 70B 的七分之一,GPT-4 Turbo 的七十分之一。而且,DeepSeek v2 还有利润。
DeepSeek v2 发布后,引来了大模型价格战,智谱、面壁、字节相继宣布了模型推理价格降低。这背后是模型架构、系统、工程的一系列进步。你有没有发现,OpenAI 的价格也降低了 10 倍不止。
Anyway,现在,DeepSeek-V2 已经通过备案,你可以联网体验,隐秘玩家的隐秘实力究竟如何?

图片来源:DeepSeek
5 月 16 日(周四)
文生图、文生视频:DiT 架构正在被广泛拥抱
开源力量大
腾讯旗下的混元文生图大模型宣布对外开源,目前已在 Hugging Face 平台及 Github 上发布,包含模型权重、推理代码、模型算法等完整模型,可供企业与个人开发者免费商用。
混元文生图大模型是中文原生的 DiT(Diffusion Models with transformer)架构文生图开源模型,这也是 Sora 和 Stable Diffusion 3 的同款架构和关键技术,是一种基于 Transformer 架构的扩散模型。过去,视觉生成扩散模型主要基于 U-Net 架构,但随着参数量的提升,基于 Transformer 架构的扩散模型展现出了更好的扩展性,有助于进一步提升模型的生成质量及效率。
5 月 17 日(周五)
「GPTs」和大模型助手 App:大厂必备,腾讯版来了
已接入 600 多个腾讯内部业务和场景
本周,腾讯公布了大模型研发、应用产品的系列进展。
腾讯混元大模型升级,推出在质量和成本上有不同特点的三个模型版本,其内部已经有 600 多个业务接入大模型。
在工具层,发布了腾讯云大模型知识引擎、图像创作引擎、视频创作引擎三大 PaaS 工具链,简化数据接入、模型精调、应用开发流程。
值得注意的是,腾讯终于推出了自家「GPTs」——元器,用户可以使用腾讯官方的插件和知识库直接创建智能体。开发完成后,将智能体一键分发到 QQ、微信客服、腾讯云等渠道上。腾讯还将于月底推出基于混元大模型的全新助手 App「腾讯元宝」。
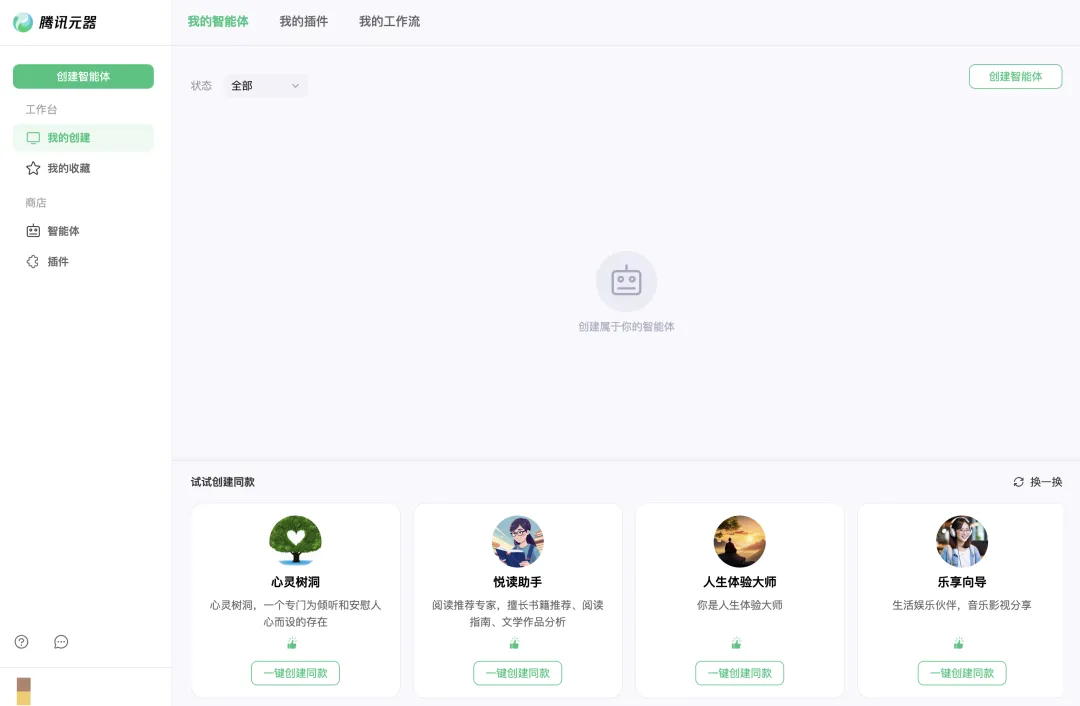
腾讯元器官网开放申请试用
写在最后:
本周,与上述 AI 产品、技术发布一同进展的,还有各大 AI 公司的「水下操作」。
什么都无法阻挡 Scaling Law 的脚步:
- 主导超级对齐的 OpenAI 联合创始人兼首席科学家 Ilya Sutskever 在社交平台 X 上宣布,他将离开公司。随后,超级对齐团队负责人之一 Jan Leike 也宣布离职,并发推称,超级对齐团队在公司内部被边缘化,无法获取计算资源做研究。
- AWS CEO Adam Selipsky 离职,或由于 AWS 错失 AI 投资和研发的最佳时机。
- 微软宣布将在法国投资 40 亿欧元,大部分将集中在 AI 领域
- 马斯克的 xAI 斥资近 100 亿美元租用 Oracle 人工智能服务器
AI 应用正在拓展既有想象力:
- 企业级可用大模型的 Anthropic 从 Instagram 挖来了 CTO 做产品,或进军 ToC APP。
- Meta Platforms 正在开发的带有摄像头的人工智能耳机项目,摄像头将使耳机能够识别佩戴者周围物理世界中的物体。Sam Altman 最近也被曝和前苹果设计大师 Jony Ive 正在探索开发带有摄像头的 AI 耳机,「很快你的耳朵里也会长出眼睛」。
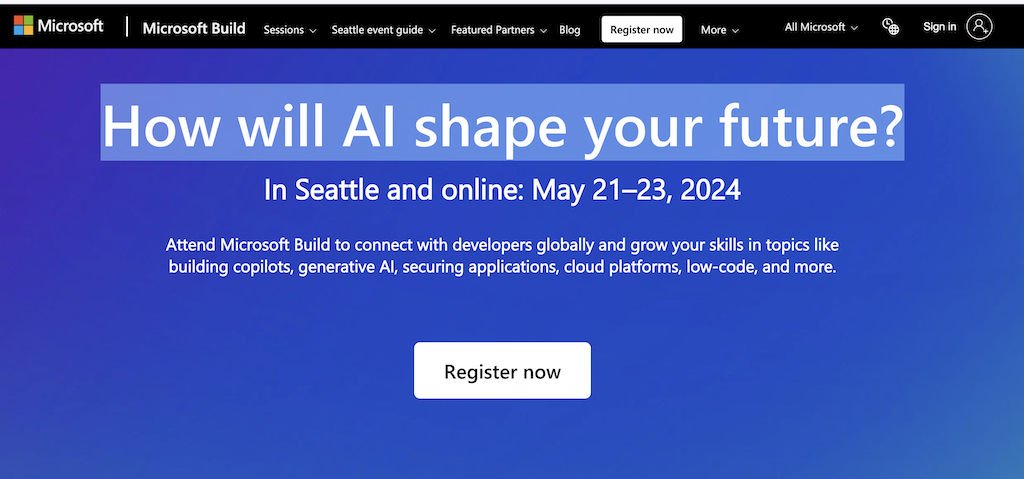
微软 Build 大会官网|图片来源:微软
下周,北京时间 5 月 22 日凌晨,AI 的另一大玩家微软,即将在西雅图举办 Hybrid:Microsoft Build 大会。官方网页上大大的「How will AI shape your future?」,强调了本次大会的主题。
金钱永不眠,AI 也是。